
一 简介
最近,Transformer结构逐渐在计算机视觉(CV)广泛应用,Vision Transformer舍弃了传统的卷积层,通过将图像切分为不同数量的特征Token,利用Transformer结构提取图像特征,不论在计算效率还是计算准确率方面都超过了以往的CNN模型。
FlagAI目前陆续支持不同的视觉模型,可以方便的支持模型下载,参数加载,训练,推理,无缝切换多GPU训练,deepspeed显存优化,训练加速等全流程操作。尤其针对于加速,显存优化,可以方便的通过设置不同的运行参数即可轻松实现!
二 FlagAI对视觉模型的支持
FlagAI除了支持自然语言处理(NLP)中的大部分模型,最近陆续支持视觉相关的模型,例如各种尺寸的ViT,目前FlagAI共支持8种不同的Vit模型权重, (来自google https://github.com/google-research/vision_transformer)。这些权重都是已经在ImageNet21K上预选练好的,只需要在其他数据集,例如cifar100上finetune少数epoch就能达到很好的效果。
|
Model
|
Pach16 |
Patch32 |
||
|
Size 224 |
Size 384 |
Size 224 |
Size 384 |
|
|
VIT-base |
✅ |
✅ |
✅ |
✅ |
|
VIT-large |
✅ |
✅ |
✅ |
✅ |
以上8种不同的Vit模型均可以一行代码直接自动下载,构建好对应的模型,参数加载,并可以直接进行分类任务的finetune (https://github.com/FlagAI-Open/FlagAI).
三 ViT模型简介
Patch embedding
ViT模型的主干结构为Transformer,与NLP中有所不同的是,ViT利用相同kernel-size与stride-size的卷积核对图像提取为特征tokens。例如,如果patch-size=(16, 16),则使用的卷积核大小与步长均为(16, 16),卷积核数量若为768,那么每卷积一次,则会得到一个特征为768维度的token。
Cls
第一步我们将一张图像通过卷积操作提取为特征tokens,为了更好的进行分类,类似于NLP,ViT模型会自定义一个可学习的cls token作为分类头,用来做分类任务。
预训练
目前ViT有两种预训练方式,1. 比较传统的是在ImageNet21K数据集上进行分类任务的预训练。2. 何凯明(Meta AI)提出的MAE,类似于NLP,将图像随机Mask掉不同区域,利用ViT+decoder对Mask区域进行重构。
四 FlagAI一键训练ViT示例代码
以cifar数据集为例
|
import torch |
借助torchvision进行数据集的下载,构建;利用FlagAI中的AutoLoader一键加载模型,并加载参数,cifar100数据集分类类别数量为100。
此外,如果想无缝切换多GPU训练,直接将env_type设置为"pytorchDDP"即可,num_gpus参数设置GPU的个数。若想切换为deepspeed优化的方式使用更大batch-size进行训练,将env_type设置为"deepspeed"即可。
五 运行结果
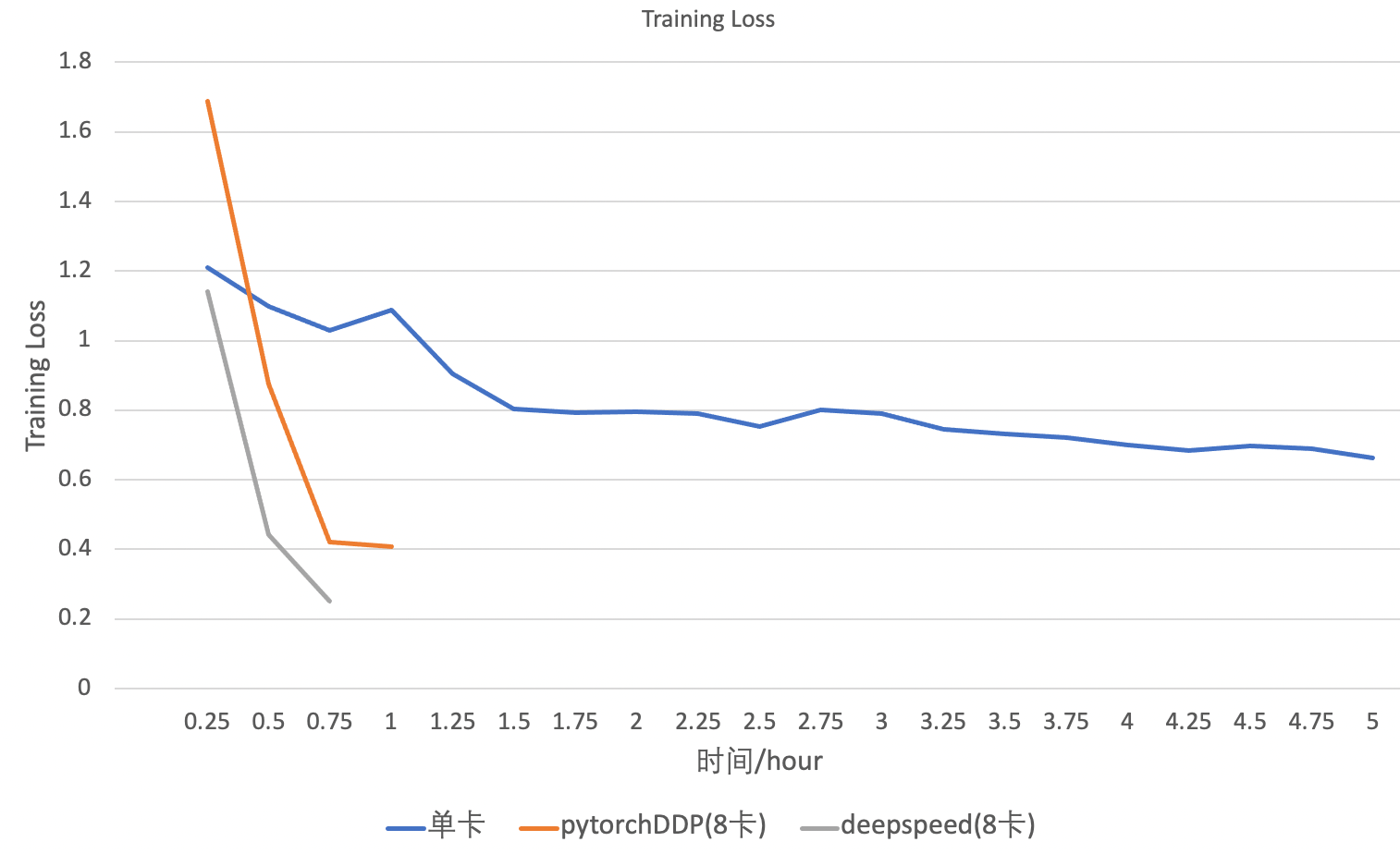
FlagAI运行log如图:

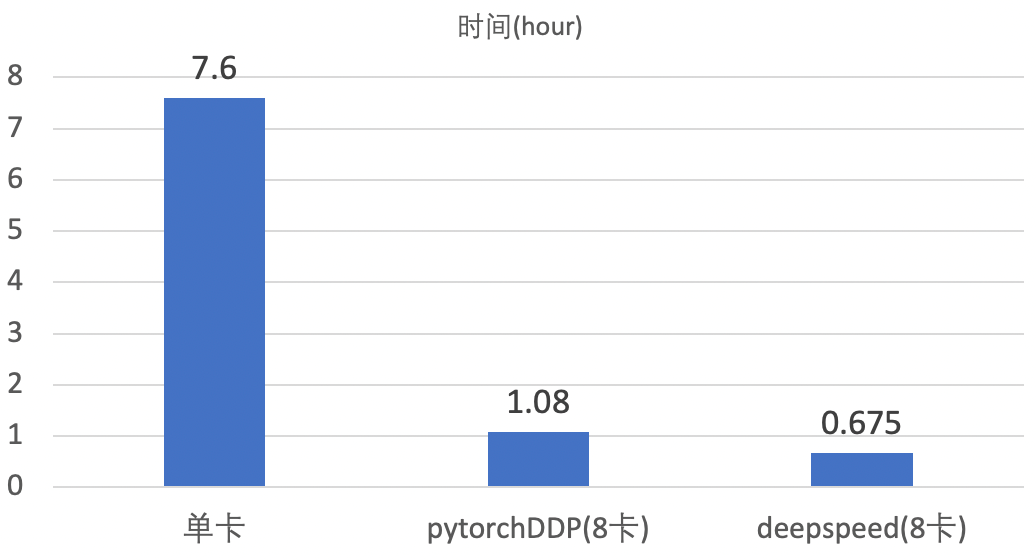
使用单块V100在cifar100数据集上进行finetune,则需要大概7.6小时。
使用8块V100在cifar100数据集上进行finetune,50个epoch大概需要1.08小时。
使用8块V100在cifar100数据集上进行finetune,利用deepspeed大batch-size加速,50个epoch大概需要0.675小时。
经过实验,表明可以做到不损失精度的情况下,进行提速。
deepspeed加速
除了无缝切换到多卡训练,在FlagAI中,还支持无缝切换deepspeed显存优化模式,使用八卡V100进行训练,batch-size最多支持到350,而使用Pytorch数据并行的方式,batch-size最多支持到160,如下表:
|
训练模式 |
GPU数量 |
GPU显存大小 |
单块GPU的最大batch-size |
|
pytorchDDP |
8 |
32G |
160 |
|
deepspeed |
8 |
32G |
350 |
使用deepspeed加大batch-size在cifar100数据集上进行finetune,50个epoch大概需要0.675小时。
不同模式下的训练时长
不同的训练模式在cifar100数据集上微调50个epoch的时间如下图:
六 FlagAI特点
FlagAI飞智是一个快速、易于使用和可扩展的AI基础模型工具包。 支持一键调用多种主流基础模型,同时适配了中英文多种下游任务。
- FlagAI支持最高百亿参数的悟道GLM(详见GLM介绍),同时也支持BERT、RoBERTa、GPT2、T5 模型、Meta OPT模型和 Huggingface Transformers 的模型。
- FlagAI提供 API 以快速下载并在给定(中/英文)文本上使用这些预训练模型,你可以在自己的数据集上对其进行微调(fine-tuning)或者应用提示学习(prompt-tuning)。
- FlagAI提供丰富的基础模型下游任务支持,例如文本分类、信息提取、问答、摘要、文本生成等,对中英文都有很好的支持。
- FlagAI由三个最流行的数据/模型并行库(PyTorch/Deepspeed/Megatron-LM)提供支持,它们之间实现了无缝集成。 在FlagAI上,你可以用不到十行代码来并行你的训练、测试过程,也可以方便的使用各种模型提速技巧。
开源项目地址:https://github.com/FlagAI-Open/FlagAI

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢