
近日,牛津大学教授Michael Wooldridge谈到了人工智能所缺少的组成部分,推文翻译如下:
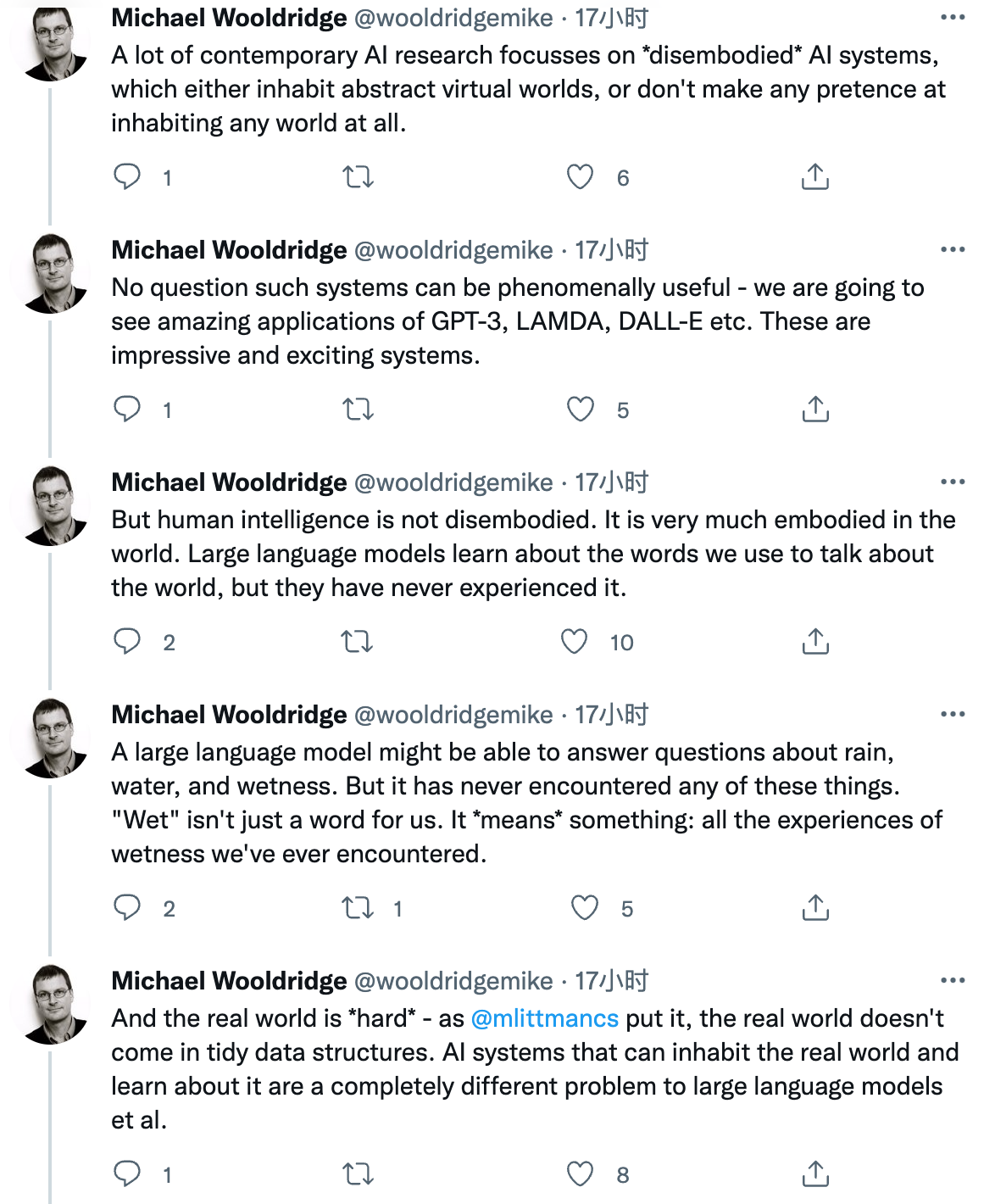
许多当代人工智能研究都集中在*无实体*人工智能系统上,它们要么居住在抽象的虚拟世界中,要么根本不假装居住在任何世界中。毫无疑问,这样的系统可能非常有用——我们将看到 GPT-3、LAMDA、DALL-E 等令人惊叹的应用。这些系统令人印象深刻且令人兴奋。但人类的智慧并没有脱离实体。它在世界上有很多体现。大型语言模型学习我们用来谈论世界的词,但它们从未体验过。大型语言模型可能能够回答有关雨、水和湿度的问题。但它从来没有遇到过这些事情。 “湿”对我们来说不仅仅是一个词。它*意味着*某种东西:我们曾经遇到过的所有潮湿的经历。现实世界是*硬核的* ——换句话说,现实世界并没有整齐的数据结构。可以居住在现实世界中并学习它的人工智能系统与大型语言模型等人是完全不同的问题。我强调我并不是说法学硕士等没有用或不重要。但是,如果我们想要*人工智能*,就需要能够居住和了解*世界*的系统。没有它,我们只解决了人工智能难题的一部分——而不是最难的部分。
他同时提到了自己在AAAS发表的一篇文章,摘要如下:
摘要:在过去的三年里,我们见证了一类新的人工智能系统的出现——所谓的基础模型,其特点是使用极大的机器学习模型(具有数百亿或数千亿参数)训练和广泛的数据集。有人认为,基础模型具有广泛的任务能力,可以专门用于特定应用程序。大型语言模型,其中 GPT-3 可能是最著名的,是当前基础模型中最突出的例子。虽然基础模型在某些任务中展示了令人印象深刻的能力——自然语言生成是最明显的例子——但我认为这是因为它们本质上是无实体的,并且它们在所学和能做的方面受到限制。基础模型可能在许多应用中非常有用:但它们并不是人工智能之路的尽头。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢