
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:将乐高图示说明翻译成机器可执行指令序列、基于关键帧的视频高效能超分辨率和着色、随机神经网络活动维度、开放集标签漂移下的域自适应、基于检索增强扩散模型的文本指导艺术图像合成、Sinkhorn-Knopp的导数收敛、基于图块检索和变形学习的细节保留形状补全、面向少样本说话头部合成的动态人脸辐射场学习、基于模态共享对比语言图像预训练的视觉表示学习
1、[CV] Translating a Visual LEGO Manual to a Machine-Executable Plan
R Wang, Y Zhang, J Mao, C Cheng, J Wu
[Stanford University & MIT & Google Research]
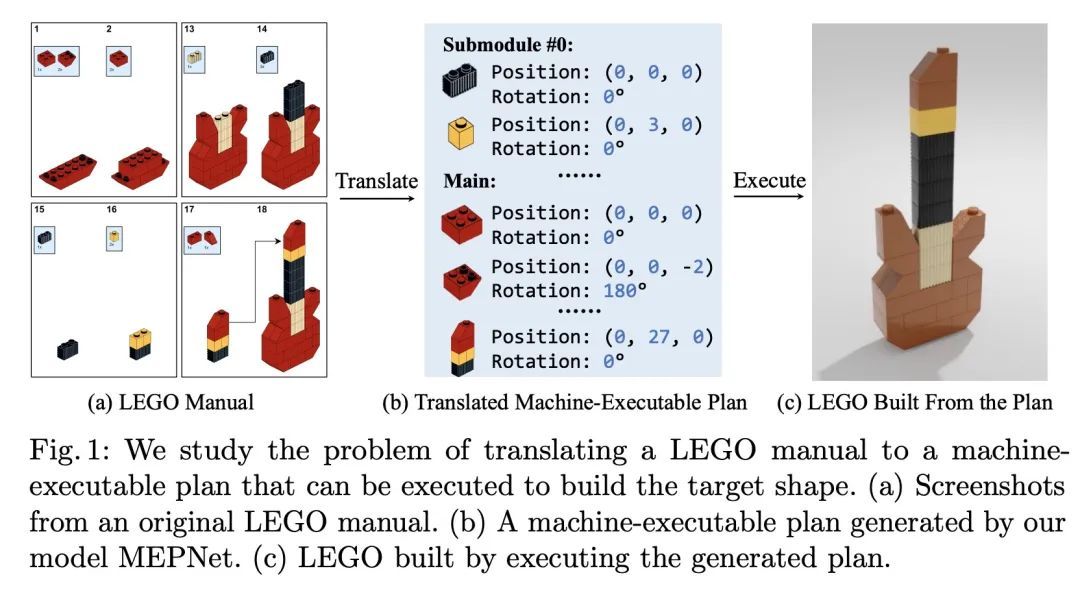
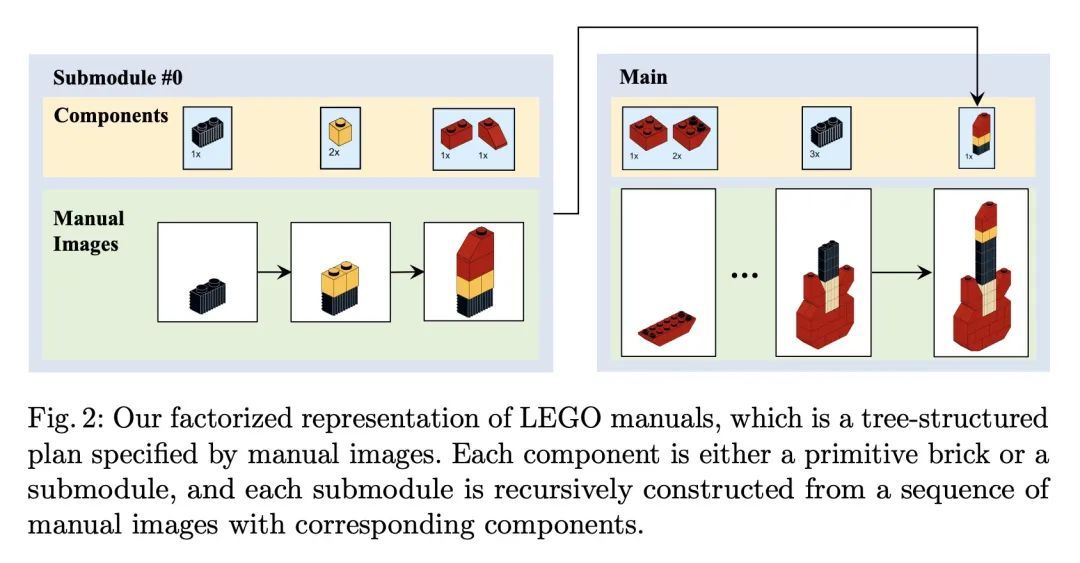
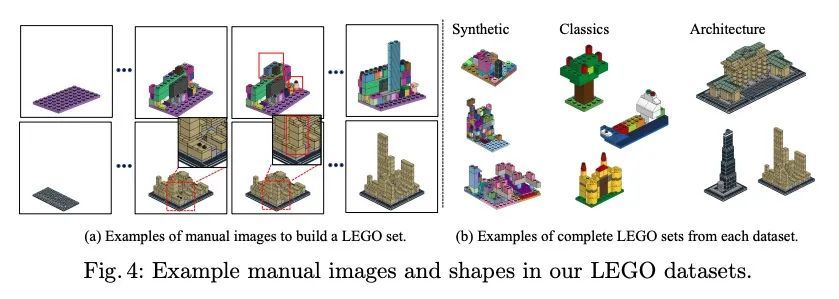
将乐高可图示说明翻译成机器可执行指令序列。本文研究的问题是如何将设计师创造的基于图像的、一步一步的组装手册翻译成机器可理解的指令。将这个问题表述为一个连续的预测任务:在每个步骤中,模型都会读取手册,定位要添加到当前形状的部件,并推断出其3D位置。这项任务带来的挑战是在手册图像和真实的3D物体之间建立2D-3D对应关系,以及对未见过的3D物体进行3D姿态估计,因为在一个步骤中要添加的新组件可能是由之前的步骤建立的物体。为了解决这两个挑战,本文提出一种新的基于学习的框架,即手册到可执行计划网络(MEPNet),从一连串的手册图像中重构装配步骤。其关键思想是整合神经2D关键点检测模块和2D-3D投影算法,以实现高精度的预测和对未见过的组件的强大泛化。MEPNet在三个新收集的乐高说明书数据集和Minecraft房屋数据集上的表现优于现有方法。
We study the problem of translating an image-based, stepby-step assembly manual created by human designers into machineinterpretable instructions. We formulate this problem as a sequential prediction task: at each step, our model reads the manual, locates the components to be added to the current shape, and infers their 3D poses. This task poses the challenge of establishing a 2D-3D correspondence between the manual image and the real 3D object, and 3D pose estimation for unseen 3D objects, since a new component to be added in a step can be an object built from previous steps. To address these two challenges, we present a novel learning-based framework, the Manual-to-ExecutablePlan Network (MEPNet), which reconstructs the assembly steps from a sequence of manual images. The key idea is to integrate neural 2D keypoint detection modules and 2D-3D projection algorithms for highprecision prediction and strong generalization to unseen components. The MEPNet outperforms existing methods on three newly collected LEGO manual datasets and a Minecraft house dataset.
https://arxiv.org/abs/2207.12572


2、[CV] NeuriCam: Video Super-Resolution and Colorization Using Key Frames
B Veluri, A Saffari, C Pernu, J Smith, M Taylor, S Gollakota
[University of Washington]
NeuriCam:基于关键帧的视频高效能超分辨率和着色。本文提出NeuriCam,一种基于关键帧的视频超分辨率和着色系统,以实现双模IOT摄像机的低功耗视频捕获。本文的想法是设计一个双模摄像机系统,其中第一模式是低功耗(1.1毫瓦),但只输出灰度、低分辨率和含有噪声的视频;第二模式消耗更高的功率(100毫瓦),但输出彩色和高分辨率图像。为减少总能量消耗,对高功率模式进行了严格的占空比控制,使其每秒钟只输出一次图像。然后,来自该摄像系统的数据被无线传输到附近的插入式网关,在那里运行实时神经网络解码器来重建一个更高分辨率的彩色视频。为实现这一目标,引入一个注意力特征过滤器机制,根据每个空间位置的特征图和输入帧的内容之间的相关性,为不同的特征分配不同的权重。本文用现成的相机设计了一个无线硬件原型,解决了包括丢包和视角不匹配等实际问题。实验评估显示,所提出的双摄像头硬件降低了摄像头的能耗,同时比之前的视频超分辨率方法实现了3.7分贝的平均灰度PSNR增益,比现有的颜色传播方法实现了5.6分贝的RGB增益。
We present NeuriCam, a key-frame video super-resolution and colorization based system, to achieve low-power video capture from dual-mode IOT cameras. Our idea is to design a dual-mode camera system where the first mode is low power (1.1 mW) but only outputs gray-scale, low resolution and noisy video and the second mode consumes much higher power (100 mW) but outputs color and higher resolution images. To reduce total energy consumption, we heavily duty cycle the high power mode to output an image only once every second. The data from this camera system is then wirelessly streamed to a nearby plugged-in gateway, where we run our real-time neural network decoder to reconstruct a higher resolution color video. To achieve this, we introduce an attention feature filter mechanism that assigns different weights to different features, based on the correlation between the feature map and contents of the input frame at each spatial location. We design a wireless hardware prototype using off-the-shelf cameras and address practical issues including packet loss and perspective mismatch. Our evaluation shows that our dual-camera hardware reduces camera energy consumption while achieving an average gray-scale PSNR gain of 3.7 dB over prior video super resolution methods and 5.6 dB RGB gain over existing color propagation methods.
https://arxiv.org/abs/2207.12496




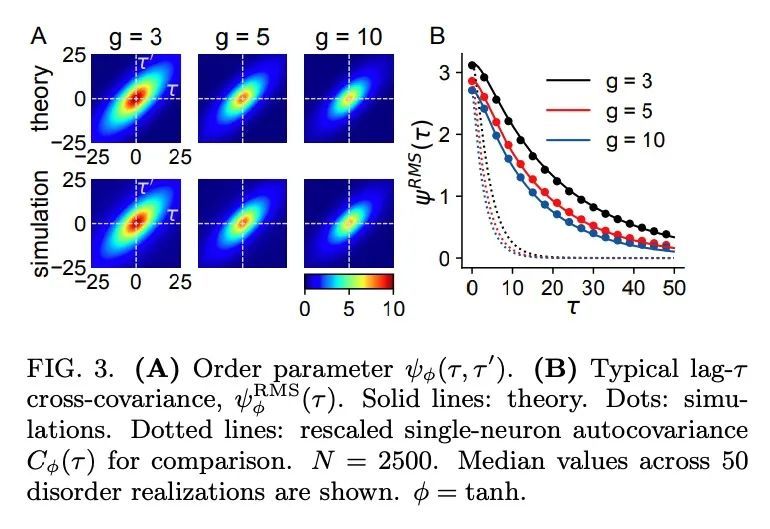
3、[LG] Dimension of Activity in Random Neural Networks
D G. Clark, L.F. Abbott, A Litwin-Kumar
[Columbia University]
随机神经网络活动维度。神经网络是高维非线性动态系统,通过许多相互连接的单元的协同活动来处理信息。理解生物和机器学习网络如何运作和学习需要了解这种协同活动的结构,即单元之间的交叉协方差所包含的信息。尽管动态平均场理论(DMFT)已经阐明了随机神经网络的几个特征,特别是它们可以产生混乱的活动,但现有的DMFT方法并不支持交叉协方差的计算。本文通过一种twosite cavity方法扩展DMFT方法来解决这个长期存在的问题。首次揭示了活动协同的几个空间和时间特征,包括有效维度,定义为协方差矩阵的频谱的参与率。所的出结果为研究随机神经网络中的集体活动结构提供了一个一般的分析框架,更广泛地,也适用于具有淬灭无序的高维非线性动力系统。
Neural networks are high-dimensional nonlinear dynamical systems that process information through the coordinated activity of many interconnected units. Understanding how biological and machine-learning networks function and learn requires knowledge of the structure of this coordinated activity, information contained in cross-covariances between units. Although dynamical mean field theory (DMFT) has elucidated several features of random neural networks—in particular, that they can generate chaotic activity—existing DMFT approaches do not support the calculation of cross-covariances. We solve this longstanding problem by extending the DMFT approach via a twosite cavity method. This reveals, for the first time, several spatial and temporal features of activity coordination, including the effective dimension, defined as the participation ratio of the spectrum of the covariance matrix. Our results provide a general analytical framework for studying the structure of collective activity in random neural networks and, more broadly, in high-dimensional nonlinear dynamical systems with quenched disorder.
https://arxiv.org/abs/2207.12373




4、[LG] Domain Adaptation under Open Set Label Shift
S Garg, S Balakrishnan, Z C. Lipton
[CMU]
开放集标签漂移下的域自适应。本文研究开放集标签漂移(OSLS)下的域自适应问题,其中标签分布可以任意改变,在部署过程中可能会出现一个新的类,但类的条件分布px|yq是域不变的。OSLS将域自适应性归入标签漂移和正向无标签(PU)学习中。学习器的目标有两方面:(a)估计目标标签分布,包括新的类别;(b)学习一个目标分类器。首先,建立识别这些量的必要和充分条件。其次,在标签漂移和PU学习进展的激励下,本文为这两项任务提出了利用黑盒预测器的实用方法。与典型的开放集域自适应(OSDA)问题不同,OSLS提供了一个良好的问题,可用于更多的原则性机制。在视觉、语言和医学数据集上进行的大量半合成基准实验表明,所提出方法总是优于OSDA基线,在目标域的精度上实现了10-25%的提高。最后,本文分析了所提出的方法,建立了对真实标签边际的有限样本收敛性和对高斯设置下线性模型最佳分类器的收敛性。
We introduce the problem of domain adaptation under Open Set Label Shift (OSLS) where the label distribution can change arbitrarily and a new class may arrive during deployment, but the class-conditional distributions ppx|yq are domain-invariant. OSLS subsumes domain adaptation under label shift and Positive-Unlabeled (PU) learning. The learner’s goals here are two-fold: (a) estimate the target label distribution, including the novel class; and (b) learn a target classifier. First, we establish necessary and sufficient conditions for identifying these quantities. Second, motivated by advances in label shift and PU learning, we propose practical methods for both tasks that leverage black-box predictors. Unlike typical Open Set Domain Adaptation (OSDA) problems, which tend to be ill-posed and amenable only to heuristics, OSLS offers a well-posed problem amenable to more principled machinery. Experiments across numerous semi-synthetic benchmarks on vision, language, and medical datasets demonstrate that our methods consistently outperform OSDA baselines, achieving 10–25% improvements in target domain accuracy. Finally, we analyze the proposed methods, establishing finite-sample convergence to the true label marginal and convergence to optimal classifier for linear models in a Gaussian setup. Code is available at https://github.com/acmi-lab/Open-Set-Label-Shift.
https://arxiv.org/abs/2207.13048



5、[CV] Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
R Rombach, A Blattmann, B Ommer
[University Munich]
基于检索增强扩散模型的文本指导艺术图像合成。最近,新的架构改善了生成性图像合成,从而在各种任务中获得了出色的视觉质量。特别值得注意的是"AI-艺术"领域,随着强大的多模态模型(如CLIP)的出现,该领域出现了前所未有的增长。通过结合语音和图像合成模型,所谓的"提示工程(prompt-engineering)"已经建立,其中精心选择和构造的句子被用来在合成的图像中实现某种视觉风格。本文提出一种基于检索增强的扩散模型(RDM)的替代方法。在RDM中,在每个训练样本的训练过程中,从外部数据库中检索一组最近邻,而扩散模型则以这些信息样本为条件。在推理(采样)过程中,用一个更专门的数据库取代检索数据库,例如,只包含特定视觉风格的图像。这提供了一种新的方式,在训练后"提示"一般的训练模型,从而指定一种特定的视觉风格。正如实验所显示的,这种方法比在文本提示中指定视觉风格更好。
Novel architectures have recently improved generative image synthesis leading to excellent visual quality in various tasks. Of particular note is the field of “AI-Art”, which has seen unprecedented growth with the emergence of powerful multimodal models such as CLIP. By combining speech and image synthesis models, so-called ”prompt-engineering” has become established, in which carefully selected and composed sentences are used to achieve a certain visual style in the synthesized image. In this note, we present an alternative approach based on retrievalaugmented diffusion models (RDMs). In RDMs, a set of nearest neighbors is retrieved from an external database during training for each training instance, and the diffusion model is conditioned on these informative samples. During inference (sampling), we replace the retrieval database with a more specialized database that contains, for example, only images of a particular visual style. This provides a novel way to “prompt” a general trained model after training and thereby specify a particular visual style. As shown by our experiments, this approach is superior to specifying the visual style within the text prompt. We open-source code and model weights at https://github.com/CompVis/latent-diffusion.
https://arxiv.org/abs/2207.13038





另外几篇值得关注的论文:
[LG] The derivatives of Sinkhorn-Knopp converge
Sinkhorn-Knopp的导数收敛
E PAUWELS, S VAITER
[Institut universitaire de France & CNRS & Universite Cote dAzur]
https://arxiv.org/abs/2207.12717


[CV] PatchRD: Detail-Preserving Shape Completion by Learning Patch Retrieval and Deformation
PatchRD:基于图块检索和变形学习的细节保留形状补全
B Sun, V G. Kim, N Aigerman, Q Huang, S Chaudhuri
[UT Austin & Adobe Research]
https://arxiv.org/abs/2207.11790





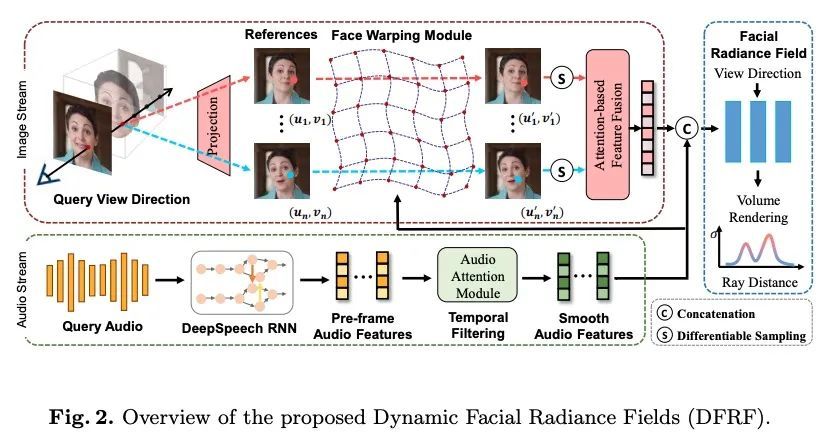
[CV] Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis
面向少样本说话头部合成的动态人脸辐射场学习
S Shen, W Li, Z Zhu, Y Duan, J Zhou, J Lu
[Tsinghua University & PhiGent Robotics]
https://arxiv.org/abs/2207.11770




[CV] Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-training
基于模态共享对比语言图像预训练的视觉表示学习
H You, L Zhou, B Xiao, N Codella, Y Cheng...
[Columbia University & Microsoft Cloud and AI & Microsoft Research]
https://arxiv.org/abs/2207.12661




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢