
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:面向大批量训练的并行对抗学习、可逆视觉Transformer、基于蛋白质语言模型的免MSA蛋白质结构预测替代方案、矢量量化图像到图像翻译、基于稀疏运动感应的铰接全身姿态跟踪、面向图像描述生成的检索增强Transformer、基于语义控制的组合人-场景交互合成、用视觉摘要图解文章、基于错误感知空间集成的视频帧插值
1、[LG] Concurrent Adversarial Learning for Large-Batch TrainingY Liu, X Chen, M Cheng, C Hsieh...
[National University of Singapore & University of California, Los Angeles & Hong Kong University of Science and Technology]
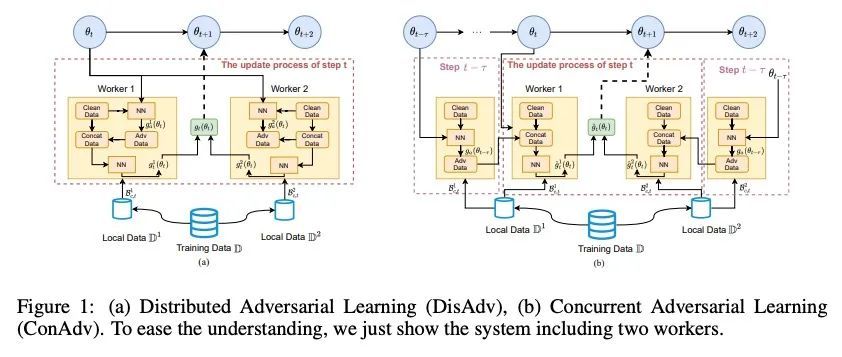
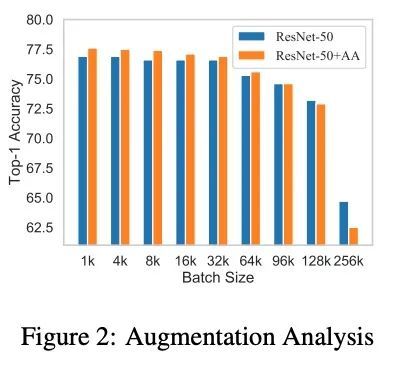
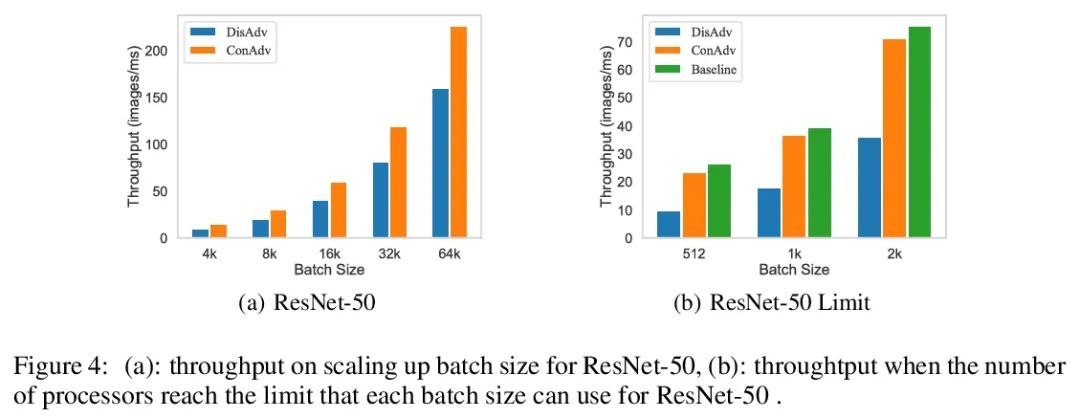
面向大批量训练的并行对抗学习。在用大量GPU/TPU处理器训练神经网络时,大批量训练已成为一种常用技术。随着批量大小的增加,随机优化器往往会收敛到尖锐的局部最小值,导致测试性能下降。目前的方法通常用各种数据增强来增加批处理规模,但本文发现随着批处理规模的增加,数据增强的性能增益会下降,而且数据增强在一定程度上会变得不够。本文建议在大批量训练中用对抗学习来增加批量大小。尽管对抗学习是平滑决策面和偏向平坦区域的自然选择,但是对抗学习还没有成功地应用于大批量训练,因为它在每一步都需要至少两次连续的梯度计算,即使有大量的处理器,与vanilla训练相比,运行时间至少增加一倍。为了克服这个问题,本文提出一种新的并发对抗学习(ConAdv)方法,通过利用定标参数来解耦对抗学习中的顺序梯度计算。实验结果表明,ConAdv可成功地增加ImageNet上ResNet-50训练的批处理量,同时保持较高的精度。特别是,ConAdv在96K的批处理规模下,在ImageNet ResNet-50训练中可以达到75.3%的最高精度,而当ConAdv与数据增强相结合时,精度可进一步提高到76.2%。这也是第一项成功地将ResNet-50的训练批量扩展到96K的工作。
Large-batch training has become a commonly used technique when training neural networks with a large number of GPU/TPU processors. As batch size increases, stochastic optimizers tend to converge to sharp local minima, leading to degraded test performance. Current methods usually use extensive data augmentation to increase the batch size, but we found the performance gain with data augmentation decreases as batch size increases, and data augmentation will become insufficient after certain point. In this paper, we propose to use adversarial learning to increase the batch size in large-batch training. Despite being a natural choice for smoothing the decision surface and biasing towards a flat region, adversarial learning has not been successfully applied in large-batch training since it requires at least two sequential gradient computations at each step, which will at least double the running time compared with vanilla training even with a large number of processors. To overcome this issue, we propose a novel Concurrent Adversarial Learning (ConAdv) method that decouple the sequential gradient computations in adversarial learning by utilizing staled parameters. Experimental results demonstrate that ConAdv can successfully increase the batch size on ResNet-50 training on ImageNet while maintaining high accuracy. In particular, we show ConAdv along can achieve 75.3\% top-1 accuracy on ImageNet ResNet-50 training with 96K batch size, and the accuracy can be further improved to 76.2\% when combining ConAdv with data augmentation. This is the first work successfully scales ResNet-50 training batch size to 96K.
https://arxiv.org/abs/2106.00221

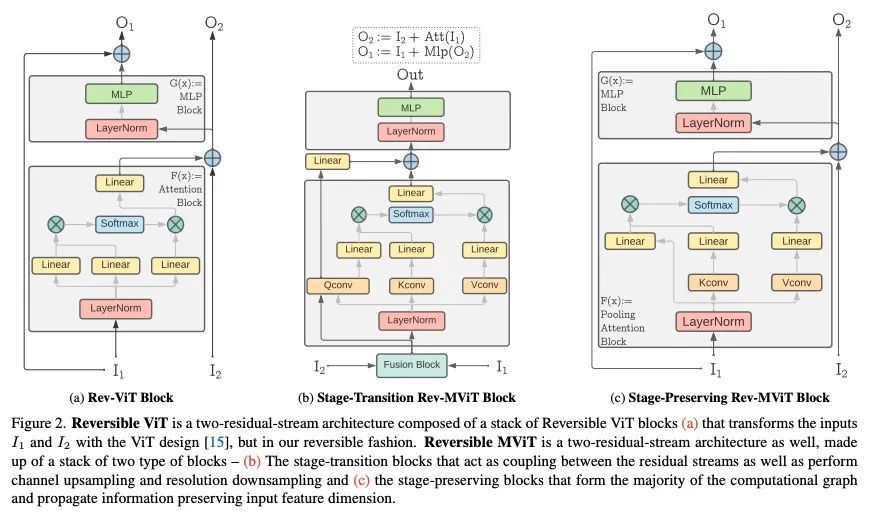
2、[CV] Reversible Vision Transformers
K Mangalam, H Fan, Y Li, CY Wu, B Xiong...
[Facebook AI Research]
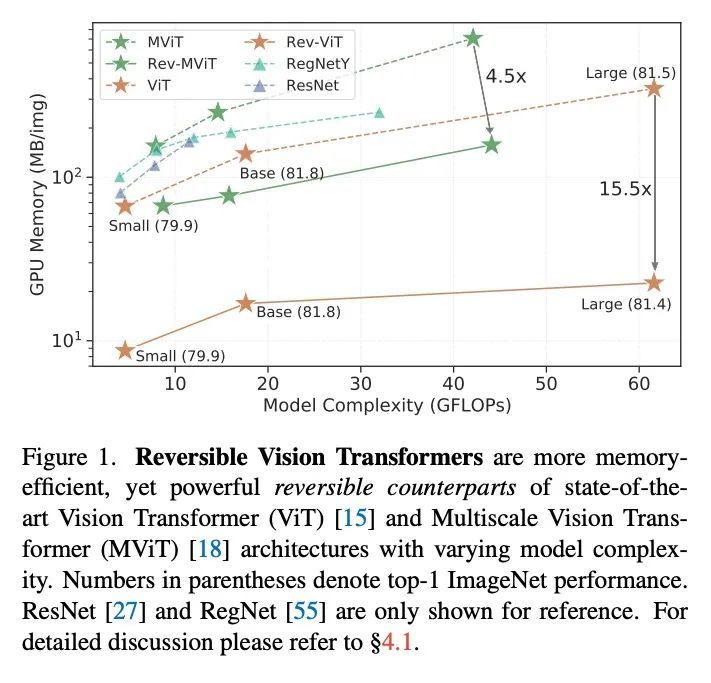
可逆视觉Transformer。本文提出可逆视觉Transformer,一种面向视觉识别的内存高效架构设计。通过将GPU内存足迹与模型的深度解耦,可逆视觉Transformer能实现Transformer架构的内存高效扩展。将两种流行的模型,即视觉Transformer和多尺度视觉变Transformer,改为可逆变体,在各模型规模,对图像分类、目标检测和视频分类的任务进行了广泛的基准测试。在模型复杂度、参数和准确度相同的情况下,可逆视觉Transformer减少了高达15.5倍的内存占用,证明了可逆视觉Transformer作为资源有限的训练机制的有效骨干的前景。重新计算激活的额外计算负担对于更深层的模型来说是可以克服的,其吞吐量可以比非可逆的对应模型增加3.9倍。
We present Reversible Vision Transformers, a memory efficient architecture design for visual recognition. By decoupling the GPU memory footprint from the depth of the model, Reversible Vision Transformers enable memory efficient scaling of transformer architectures. We adapt two popular models, namely Vision Transformer and Multiscale Vision Transformers, to reversible variants and benchmark extensively across both model sizes and tasks of image classification, object detection and video classification. Reversible Vision Transformers achieve a reduced memory footprint of up to 15.5× at identical model complexity, parameters and accuracy, demonstrating the promise of reversible vision transformers as an efficient backbone for resource limited training regimes. Finally, we find that the additional computational burden of recomputing activations is more than overcome for deeper models, where throughput can increase up to 3.9× over their non-reversible counterparts. Code and models are available at https:// github.com/facebookresearch/mvit.
https://openaccess.thecvf.com/content/CVPR2022/papers/Mangalam_Reversible_Vision_Transformers_CVPR_2022_paper.pdf


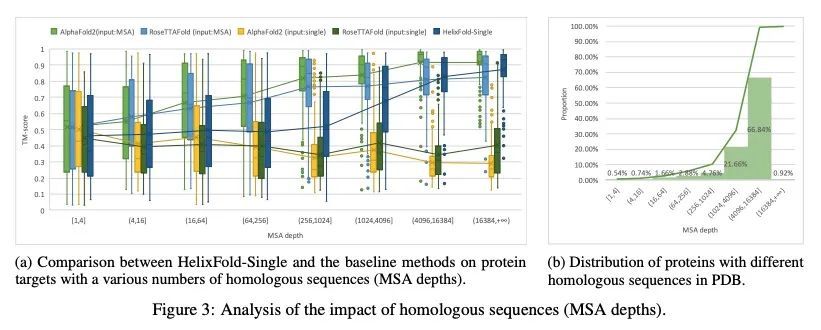
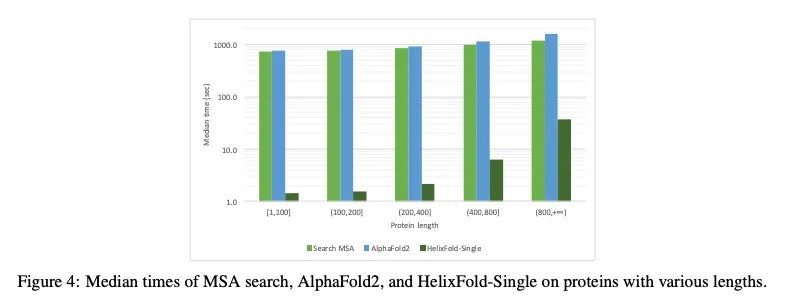
3、[LG] HelixFold-Single: MSA-free Protein Structure Prediction by Using Protein Language Model as an Alternative
X Fang, F Wang, L Liu, J He, D Lin, Y Xiang, X Zhang, H Wu, H Li, L Song
[Baidu Inc & BioMap]
HelixFold-Single: 基于蛋白质语言模型的免MSA蛋白质结构预测替代方案。基于人工智能的蛋白质结构预测管道,如AlphaFold2,已经达到了接近实验的精度。这些先进的管道主要依靠多序列比对(MSA)和模板作为输入,从同源序列学习共同进化信息。然而,从蛋白质数据库中搜索MSA和模板是非常耗时的,通常需要数十分钟。因此,本文试图通过只用蛋白质的一级序列来探索快速蛋白质结构预测的极限。HelixFold-Single的提出是为了将大规模的蛋白质语言模型与AlphaFold2的卓越的几何学习能力相结合。所提出的方法,HelixFold-Single,首先利用自监督学习范式,用数以百万计的主序列预训练一个大规模蛋白质语言模型(PLM),它将作为MSA和模板的替代品来学习共同演化信息。然后,通过结合预训练PLM和AlphaFold2的基本组件,得到了一个端到端的可微模型,仅从主序列预测原子的3D坐标。HelixFold-Single在CASP14和CAMEO数据集中得到了验证,在具有大型同源族的目标上实现了与基于MSA的方法相竞争的精度。此外,HelixFold-Single比蛋白质结构预测的主流管道消耗的时间要少得多,表明它在需要大量预测的任务中具有潜力。
AI-based protein structure prediction pipelines, such as AlphaFold2, have achieved near-experimental accuracy. These advanced pipelines mainly rely on Multiple Sequence Alignments (MSAs) and templates as inputs to learn the co-evolution information from the homologous sequences. Nonetheless, searching MSAs and templates from protein databases is time-consuming, usually taking dozens of minutes. Consequently, we attempt to explore the limits of fast protein structure prediction by using only primary sequences of proteins. HelixFold-Single is proposed to combine a large-scale protein language model with the superior geometric learning capability of AlphaFold2. Our proposed method, HelixFold-Single, first pre-trains a large-scale protein language model (PLM) with thousands of millions of primary sequences utilizing the self-supervised learning paradigm, which will be used as an alternative to MSAs and templates for learning the co-evolution information. Then, by combining the pre-trained PLM and the essential components of AlphaFold2, we obtain an end-to-end differentiable model to predict the 3D coordinates of atoms from only the primary sequence. HelixFold-Single is validated in datasets CASP14 and CAMEO, achieving competitive accuracy with the MSA-based methods on the targets with large homologous families. Furthermore, HelixFold-Single consumes much less time than the mainstream pipelines for protein structure prediction, demonstrating its potential in tasks requiring many predictions. The code of HelixFold-Single is available at this https URL, and we also provide stable web services on this https URL.
https://arxiv.org/abs/2207.13921



4、[CV] Vector Quantized Image-to-Image Translation
Y Chen, S Cheng, W Chiu, H Tseng, H Lee
[National Chiao Tung University & Meta & Snap Inc]
矢量量化图像到图像翻译。目前的图像到图像翻译方法用条件生成模型来制定任务,导致只学习重新着色或区域变化,因为受到条件背景提供的丰富结构信息的限制。本文建议将矢量量化技术引入图像-图像翻译框架。矢量量化的内容表示不仅可以促进翻译,还可以促进不同域之间共享的无条件分布。同时,伴随着拆分后的风格表示,所提出的方法进一步实现了图像扩展的能力,在域内和域间都具有灵活性。定性和定量实验表明,该框架实现了与最先进的图像到图像翻译和图像扩展方法相媲美的性能。与单个任务的方法相比,所提出的方法作为一个统一的框架,将图像到图像的翻译、无条件生成和图像扩展的应用完全释放出来。例如,它为图像生成和扩展提供了风格的可变性,并为图像到图像的翻译提供了进一步的扩展能力。
Current image-to-image translation methods formulate the task with conditional generation models, leading to learning only the recolorization or regional changes as being constrained by the rich structural information provided by the conditional contexts. In this work, we propose introducing the vector quantization technique into the image-to-image translation framework. The vector quantized content representation can facilitate not only the translation, but also the unconditional distribution shared among different domains. Meanwhile, along with the disentangled style representation, the proposed method further enables the capability of image extension with flexibility in both intra- and inter-domains. Qualitative and quantitative experiments demonstrate that our framework achieves comparable performance to the state-of-the-art image-to-image translation and image extension methods. Compared to methods for individual tasks, the proposed method, as a unified framework, unleashes applications combining image-to-image translation, unconditional generation, and image extension altogether. For example, it provides style variability for image generation and extension, and equips image-to-image translation with further extension capabilities.
https://arxiv.org/abs/2207.13286





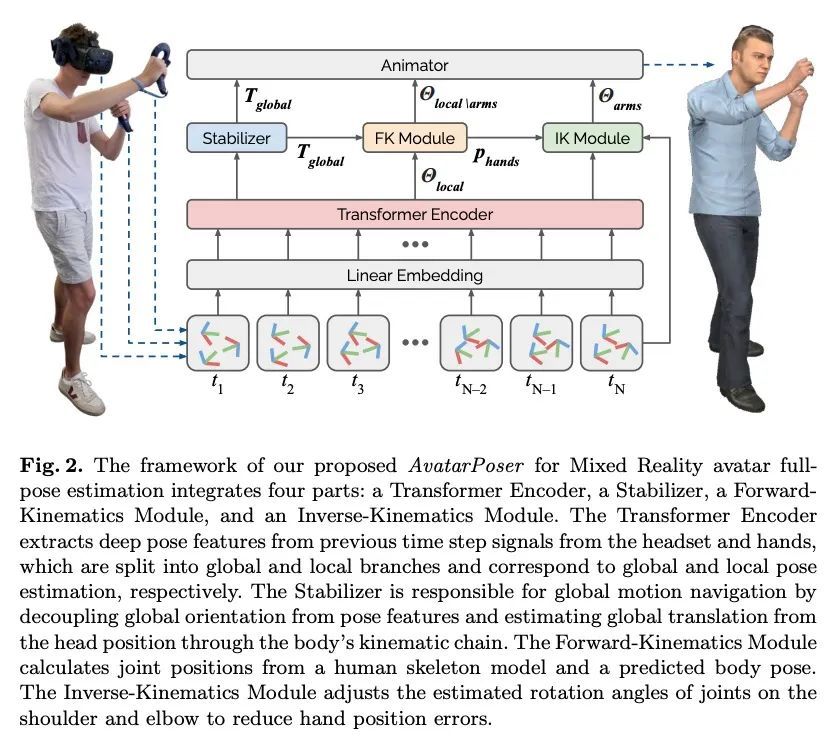
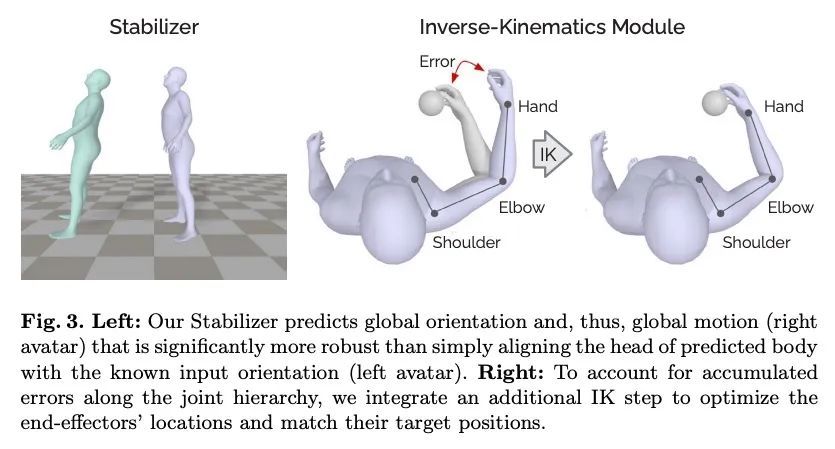
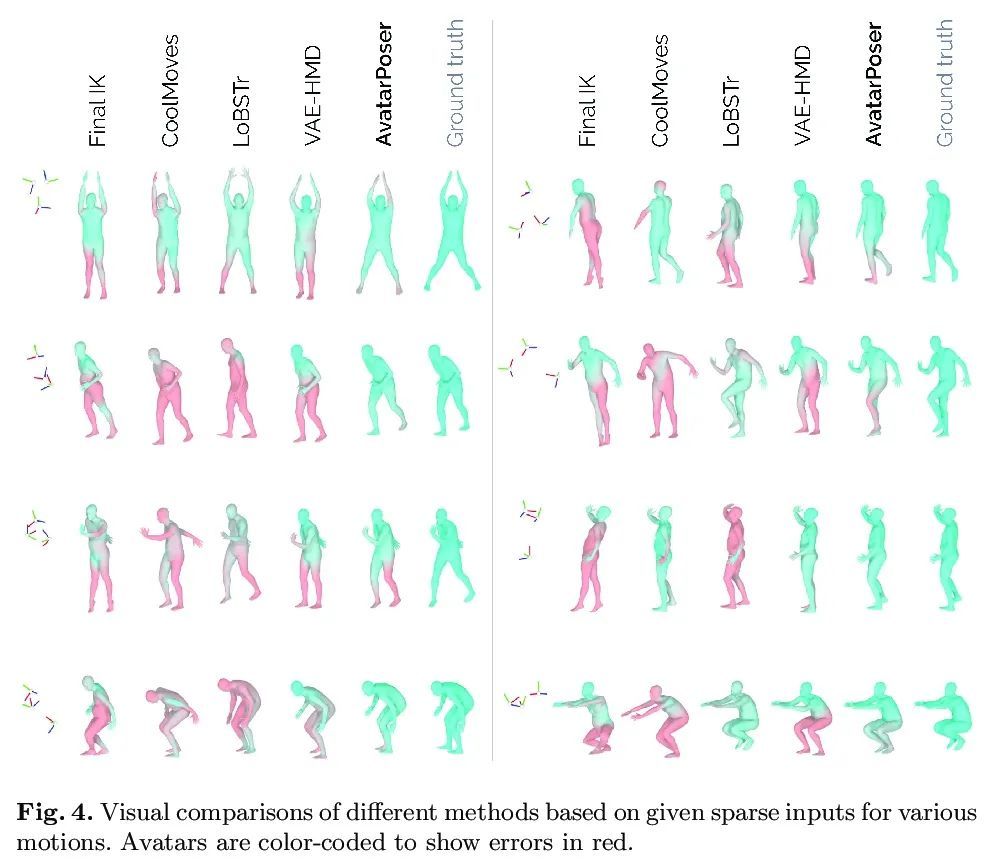
5、[CV] AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing
J Jiang, P Streli, H Qiu, A Fender, L Laich, P Snape, C Holz
[ETH Zurich & Reality Labs at Meta]
AvatarPoser: 基于稀疏运动感应的铰接全身姿态跟踪。如今的混合现实头戴式显示器追踪用户在世界空间中的头部姿态,以及用户在增强现实和虚拟现实场景中的双手交互。虽然这足以支持用户的输入,但不幸的是,它将用户的虚拟表示仅限制在他们的上半身。因此,目前的系统求助于浮动的化身,其局限性在协作环境中尤为明显。为了从稀疏的输入源中估计全身姿态,之前的工作在骨盆或下半身加入了额外的跟踪器和传感器,这增加了设置的复杂性并限制了在移动环境中的实际应用。本文提出AvatarPoser,第一个基于学习的方法,只用用户的头和手的运动输入就能预测世界坐标中的全身姿态。该方法建立在Transformer编码器基础上,从输入信号中提取深度特征,并将全局运动与学到的局部关节方向解耦,以指导姿态估计。为获得类似运动捕捉动画的准确的全身运动,用反运动学的优化程序来完善手臂关节位置,以匹配原始跟踪输入。评估显示,AvatarPoser在大型运动捕捉数据集(AMASS)的评估中取得了新的最先进的结果。同时,该方法的推理速度支持实时操作,为Metaverse应用提供了一个实用的界面来支持全身的化身控制和表现。
Today's Mixed Reality head-mounted displays track the user's head pose in world space as well as the user's hands for interaction in both Augmented Reality and Virtual Reality scenarios. While this is adequate to support user input, it unfortunately limits users' virtual representations to just their upper bodies. Current systems thus resort to floating avatars, whose limitation is particularly evident in collaborative settings. To estimate full-body poses from the sparse input sources, prior work has incorporated additional trackers and sensors at the pelvis or lower body, which increases setup complexity and limits practical application in mobile settings. In this paper, we present AvatarPoser, the first learning-based method that predicts full-body poses in world coordinates using only motion input from the user's head and hands. Our method builds on a Transformer encoder to extract deep features from the input signals and decouples global motion from the learned local joint orientations to guide pose estimation. To obtain accurate full-body motions that resemble motion capture animations, we refine the arm joints' positions using an optimization routine with inverse kinematics to match the original tracking input. In our evaluation, AvatarPoser achieved new state-of-the-art results in evaluations on large motion capture datasets (AMASS). At the same time, our method's inference speed supports real-time operation, providing a practical interface to support holistic avatar control and representation for Metaverse applications.
https://arxiv.org/abs/2207.13784


另外几篇值得关注的论文:
[CV] Retrieval-Augmented Transformer for Image Captioning
面向图像描述生成的检索增强Transformer
S Sarto, M Cornia, L Baraldi, R Cucchiara
[University of Modena and Reggio Emilia]
https://arxiv.org/abs/2207.13162



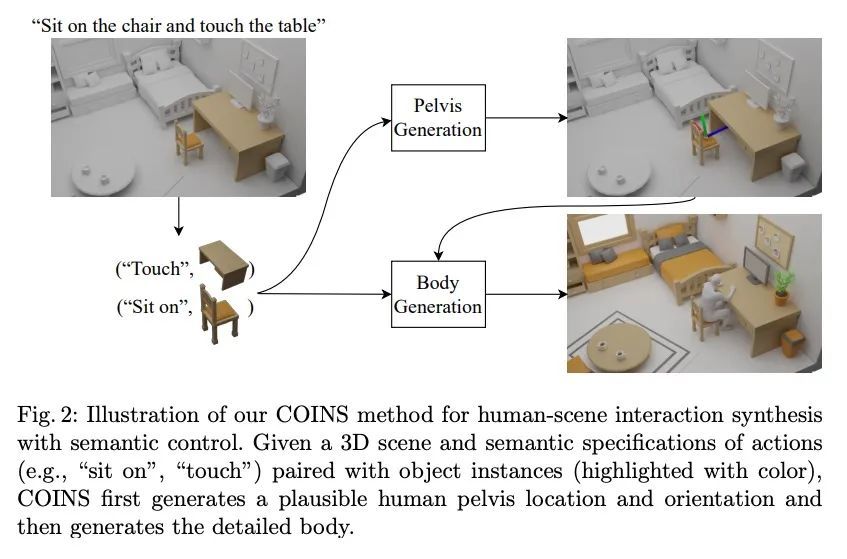
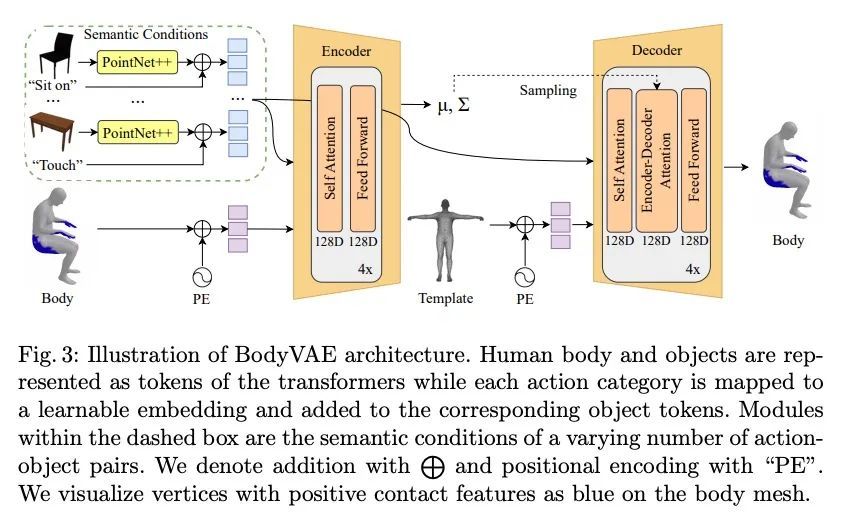
[CV] Compositional Human-Scene Interaction Synthesis with Semantic Control
基于语义控制的组合人-场景交互合成
K Zhao, S Wang, Y Zhang, T Beeler, S Tang
[ETH Zurich & Google]
https://arxiv.org/abs/2207.12824


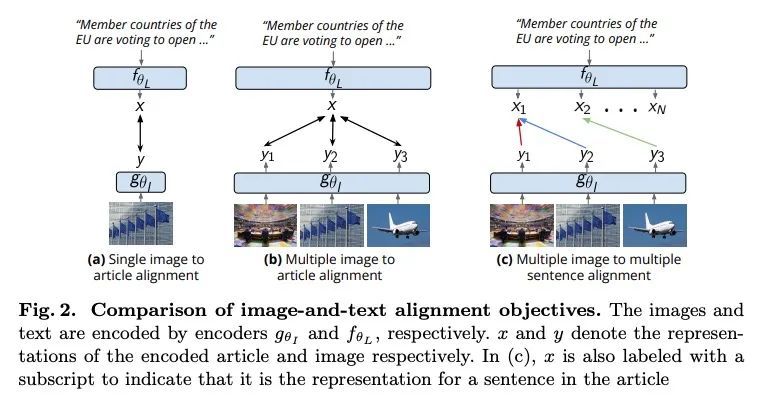
[CV] NewsStories: Illustrating articles with visual summaries
NewsStories:用视觉摘要图解文章
R Tan, B A. Plummer, K Saenko, J Lewis, A Sud, T Leung
[Boston University & Google Research]
https://arxiv.org/abs/2207.13061



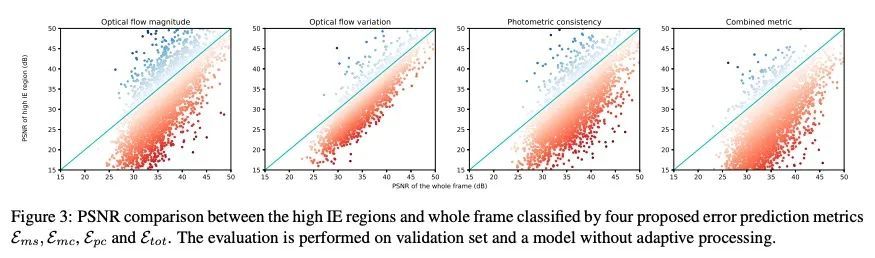
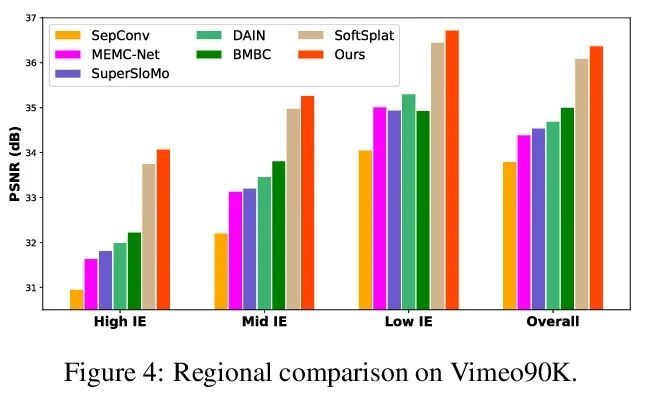
[CV] Error-Aware Spatial Ensembles for Video Frame Interpolation
基于错误感知空间集成的视频帧插值
Z Chi, R M Nasiri, Z Liu, Y Yu, J Lu, J Tang, K N Plataniotis
[Noah’s Ark Lab & University of Toronto]
https://arxiv.org/abs/2207.12305



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢