
作者:Praneeth Nemani, Satyanarayana Vollala
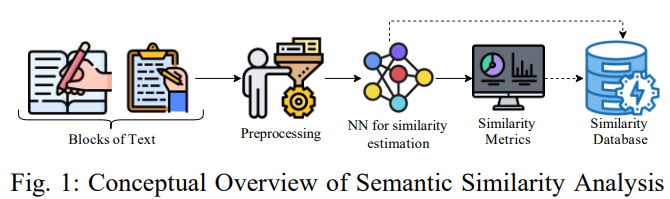
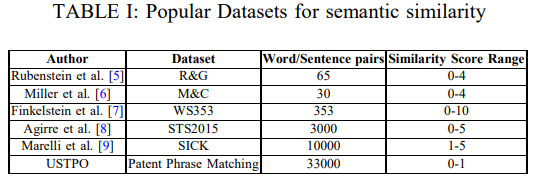
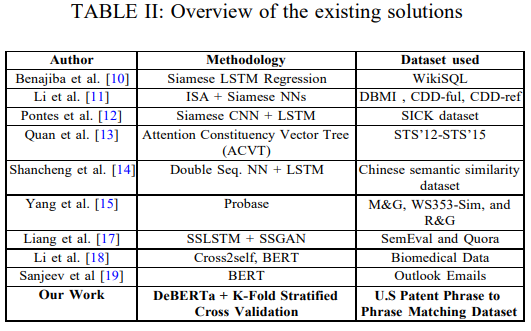
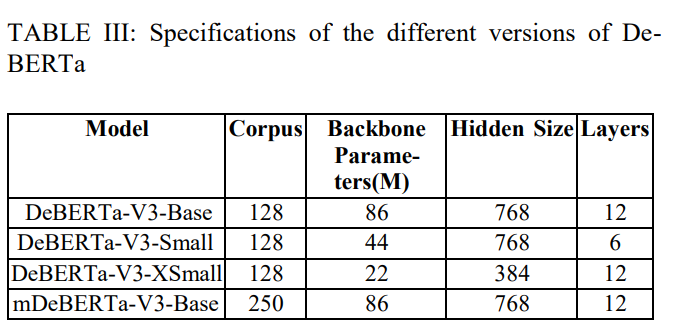
简介:本文在大型语料库上对传统的和基于Transformerbase的语义相似性建模方法进行研究实验。在当今自然语言处理的许多开创性应用中,语义相似性分析和建模是一项广受好评的任务。由于顺序模式识别的感觉,许多神经网络如 RNN 和 LSTM 在语义相似度建模方面取得了令人满意的结果。然而,这些解决方案被认为是低效的,因为它们无法以非顺序方式处理信息,从而导致上下文提取不当。Transformer 因其非顺序数据处理和自注意力等优势而成为最先进的架构。在本文中,作者使用传统和基于Transformer 的技术对美国专利短语到短语匹配数据集进行语义相似性分析和建模。作者对解码增强型 BERT——DeBERTa 的四种不同变体进行了试验,并通过执行 K-Fold 交叉验证来增强其性能。实验结果表明:与传统技术相比,作者的方法具有更高的性能,平均 Pearson 相关分数为 0.79。
论文下载:https://arxiv.org/ftp/arxiv/papers/2207/2207.11716.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢