
作者:Bargav Jayaraman, Esha Ghosh, Huseyin Inan,等
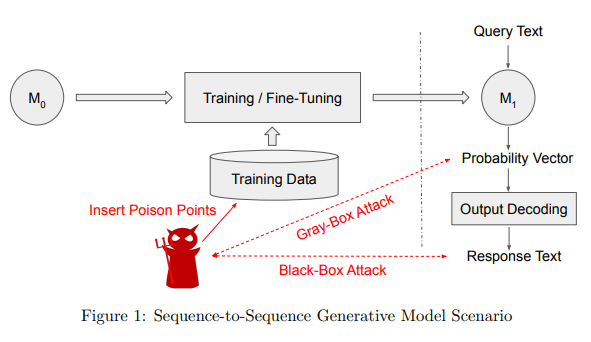
简介:本文研究语言模型泄漏敏感信息的安全议题。随着大型预训练语言模型检查点(例如 GPT-2 和 BERT)的广泛使用,最近的趋势是在下游任务上对其进行微调,以通过少量计算实现最先进的高性能。一个自然的例子是智能回复应用程序,其中预训练的模型经过微调,以建议给定查询消息的多个响应。在这项工作中,作者着手调查典型智能回复管道中的潜在信息泄漏漏洞,并表明具有黑盒或灰盒访问智能回复模型的对手有可能提取存在的敏感用户信息在训练数据中。作者通过攻击设置进一步分析了与此应用程序相关的特定组件的隐私影响(例如解码策略)。
实验结果表明,作者的黑盒和灰盒攻击能够从基于transformer的语言模型中恢复大量电子邮件ID、密码和登录凭据。早期停止模型训练过程的防御策略已被证明可以防止记忆(发生在训练过程的后期),也被认为是机器学习中的“最佳实践”,但无法抵御作者的攻击。然而,正如作者的实验所证明的那样,差异隐私被证明是一种很有前途的防御此类攻击的方法。作者希望作者的工作能够激励机器学习从业者和研究人员进一步了解对手如何与ML管道交互,并探索针对特定ML应用的各种对抗能力。

论文下载:https://arxiv.org/pdf/2207.10802.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢