

相信大多数学习过人工智能课程的读者,当听到A*算法的时候,都会有一种既熟悉又陌生的感觉。说A*算法熟悉,是因为一听到这个算法,就想起那本厚厚的《人工智能——一种现代的方法》,想起这个算法似乎是人工智能课程考试的重点;说A*算法陌生,是因为大家现在在从事人工智能相关的研究和开发工作时,似乎又很少用到这个算法,大部分时间都花在了研究数据处理和处理实验设置上面。而在NAACL2022上,一群来自AI2的自然语言处理研究者们 利用A*算法开发了一种新的自然语言生成解码方式,还被授予了NAACL2022 Best New Method paper。看起来已经过时的A*算法,居然能在深度学习时代有如此的妙用,看完这篇论文,笔者情不自禁地打开了《人工智能——一种现代的方法》,想看看还有什么经典算法可以深挖一下!
论文标题:
NEUROLOGIC A*esque Decoding: Constrained Text Generation with Lookahead Heuristics
论文链接:
https://arxiv.org/pdf/2112.08726.pdf
问题背景
自然语言生成任务一般指给定一个输入序列x,生成一个输出序列y。目的是解出使得目标函数F(y)最大化的序列y*,而H(y)衡量y对约束条件的满足。传统的Beam Search不考虑全局的最优,而是最优化当前步骤添加的Token.
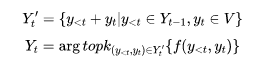
为了达到全局最优的效果,需要满足如下的优化目标
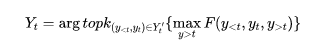
主要方法
前向启发算法
直接优化全局最优目标面临着搜索空间过大的问题。而A算法可以被用来解决这个搜索问题。A算法是一个最优优先的搜索算法,可以解决这样形式的搜索问题:
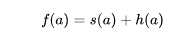
其中s(a)是迄今为止的分数,h(a)是对于未来分数的启发式估计。因此我们将优化目标修改为如下形式
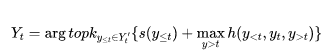
同时,需要限制前向搜索的长度为l,避免模型无限制地向前搜索
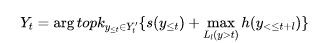
在前向生成的过程中有几种不同的方法。Greedy方法只生成一个序列,y<=t从开始,每次选择概率最大的Token 。Soft方法采用插值的思想,混合Greedy方法和随机选择一个Token的概率分布。Bean方法从y<t开始进行步的Beam Search,选择前个概率最大的序列, 而Smpling方法则是直接从按照概率进行采样。
无限制生成
在无限制生成的场景下,使用的优化函数为
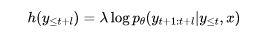
其中λ控制的是对未来估计的重视程度,类似于加权A*算法
受限制生成
在受限制生成任务上,作者们基于之前的工作NeuroLogic进行改进。首先我们简要介绍一下NeuroLogic方法。首先,将对生成文本的限制表示为合取范式。NeuroLogic的优化目标可以写为
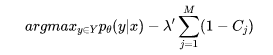
其中λ’远大于0,用来惩罚不满足的约束。在每一步搜索时,NeuroLogic利用如下的打分函数进行计算
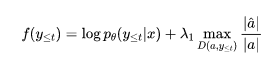
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢