
https://arxiv.org/abs/2201.08984
https://github.com/hbzju/PiCO

现代深度神经网络的训练通常需要大量有标签的数据(labeled data),这给训练数据的收集带来了巨大的困难。这是因为给现实世界中的数据打标签 (data annotation) 会存在标签模糊 (label ambiguity) 和噪声的影响。
如图 1 所示,对于给图片打标签的人 (human annotator) 来说,将阿拉斯加雪撬犬这个这个正确的标签从它的候选标签集 {哈士奇犬、阿拉斯加犬、萨摩耶犬} 中选出来是很困难的,因为这几种犬类长得非常相似。标签模糊性 (label ambiguity) 的问题在许多应用中普遍存在,但经常被忽视。这就突显出了偏标签学习 (partial label learning PLL) 的重要性。
尽管 PLL 的应用前景广阔,但它会受到标签模糊性的影响。所以,PLL 的一个核心挑战就是标签消歧 (label disambiguation),即从候选标签集 (candidate label set) 中识别出正确的标签 (ground-truth label)。现有的一些标签消歧模型通常假设:在特征空间中距离相近的数据点更有可能享有相同的正确标签,这就导致它们往往需要一个较好的特征表示 (feature representation) 才可以达到比较好的表现。
这种对表征 (representation) 的依赖会形成一个重大的困境 (non-trivial dilemma):标签不确定性 (label uncertainty) 会对表征学习 (representation learning) 的过程产生不好的影响,从而生成不好的表征,而表征的不良质量又会反过来阻碍有效的标签消歧 (label disambiguation)。到目前为止,为解决这个问题所做的努力还很少。基于此,这篇文章想要通过调和这两个互相依赖的部分:表征学习和标签消歧之间的内在矛盾,来解决这个困境问题。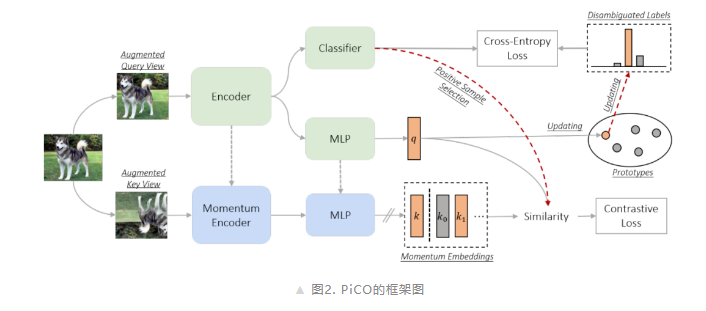
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢