
作者:Maor Ivgi, Uri Shaham, Jonathan Berant
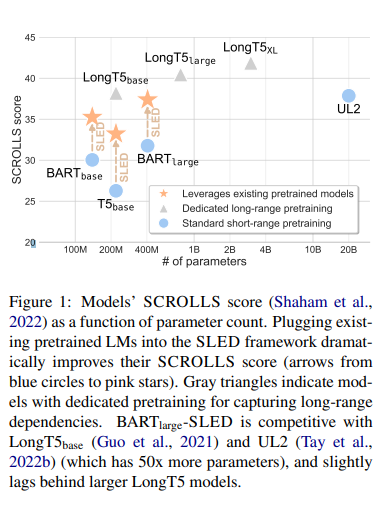
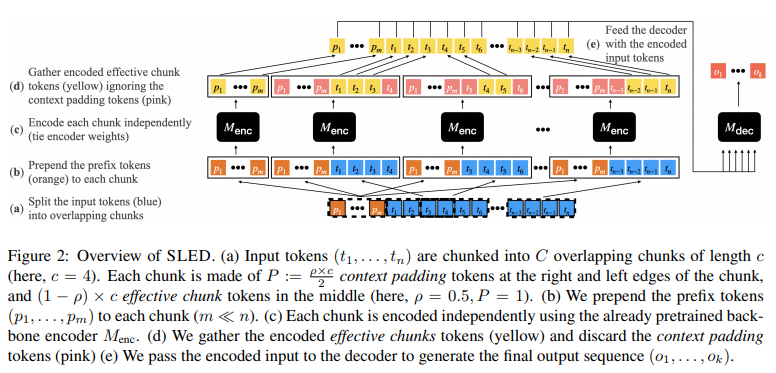
简介:本文研究预训练语言模型 (LM) 长序列处理的新方法。基于 Transformer 的LM在自然语言理解中无处不在,但由于其二次复杂性,不能应用于长序列,例如故事、科学文章和长文档。虽然已经提出了无数高效的Transformer 变体,但它们通常基于需要从头开始进行昂贵的预训练的自定义实现。在这项工作中,作者提出了 SLED:SLiding-Encoder and Decoder,这是一种处理长序列的简单方法,可重用和利用经过实战考验的短文本预训练 LM。具体来说,作者将输入划分为重叠的块,使用短文本 LM 编码器对每个块进行编码,并使用预训练的解码器跨块融合信息(解码器融合)。作者通过对照实验说明 SLED 为长文本理解提供了一种可行的策略,并评估了作者在 SCROLLS 上的方法,包含七个数据集的基准、涵盖了广泛的语言理解任务。作者发现 SLED 与最大 50 倍且需要专门且昂贵的预训练步骤的专用模型具有竞争力。
论文下载:https://arxiv.org/pdf/2208.00748.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢