
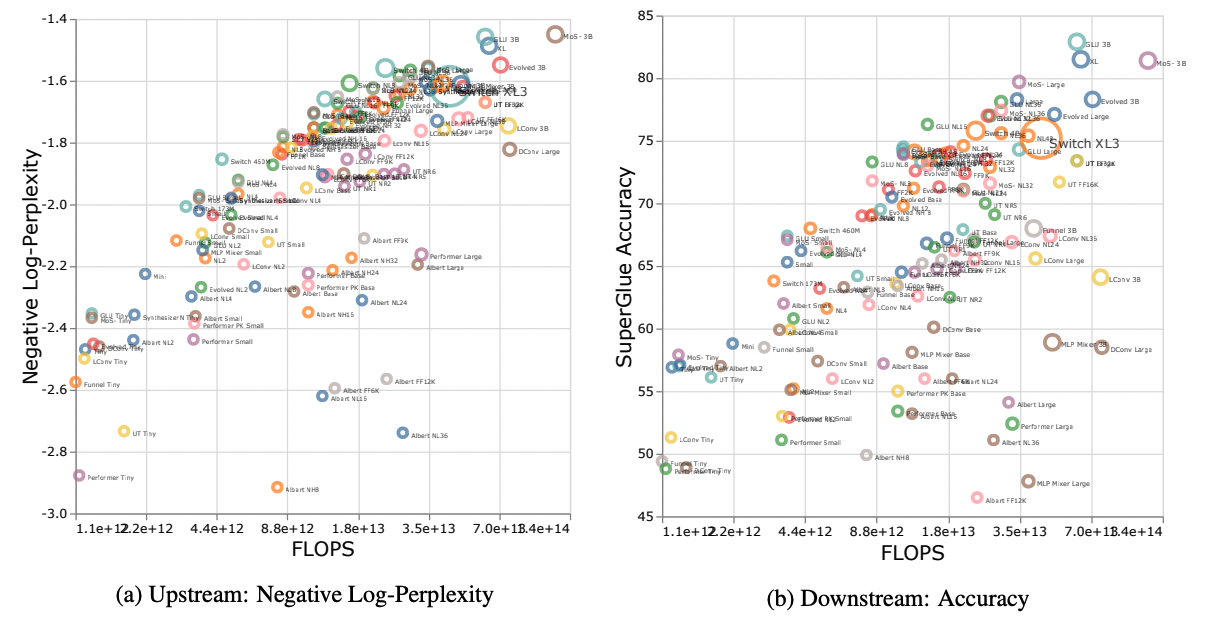
摘要:Transformer 模型的放大特性(Scaling-law)引起了很多人的兴趣。然而,并没有太多研究关注不同归纳偏差和模型架构的放大特性。模型架构的规模是否不同?如果是这样,如何感应偏置影响缩放行为?如何这会影响上游(预训练)吗和下游任务(迁移)?本文进行对十个模型结构的放大行为的系统研究。例如 Transformers、Switch Transformers、Universal Transformers、Dynamic convolutions、Performers、以及最近提出的 MLP-Mixers。通过广泛的实验,我们表明(1)架构在执行缩放时确实是一个重要的考虑因素,以及(2)性能最佳的模型可以在不同的情况下波动。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢