标题:清华 | GLM-130B: An Open Bilingual Pre-Trained Model(GLM-130B:一个开放的双语预训练模型)
简介:GLM-130B 是一个开放的双语(英文和中文)双向密集模型,具有 1300 亿个参数,使用通用语言模型(GLM)算法进行预训练。它旨在支持单个 A100 (40G * 8) 或 V100 (32G * 8) 服务器上的 130B 参数的推理任务。截至 2022 年 7 月 3 日,GLM-130B 已经接受了超过 4000 亿个文本标记(中英文各 200B)的训练,它具有以下独特功能:
(1)双语:支持英文和中文。
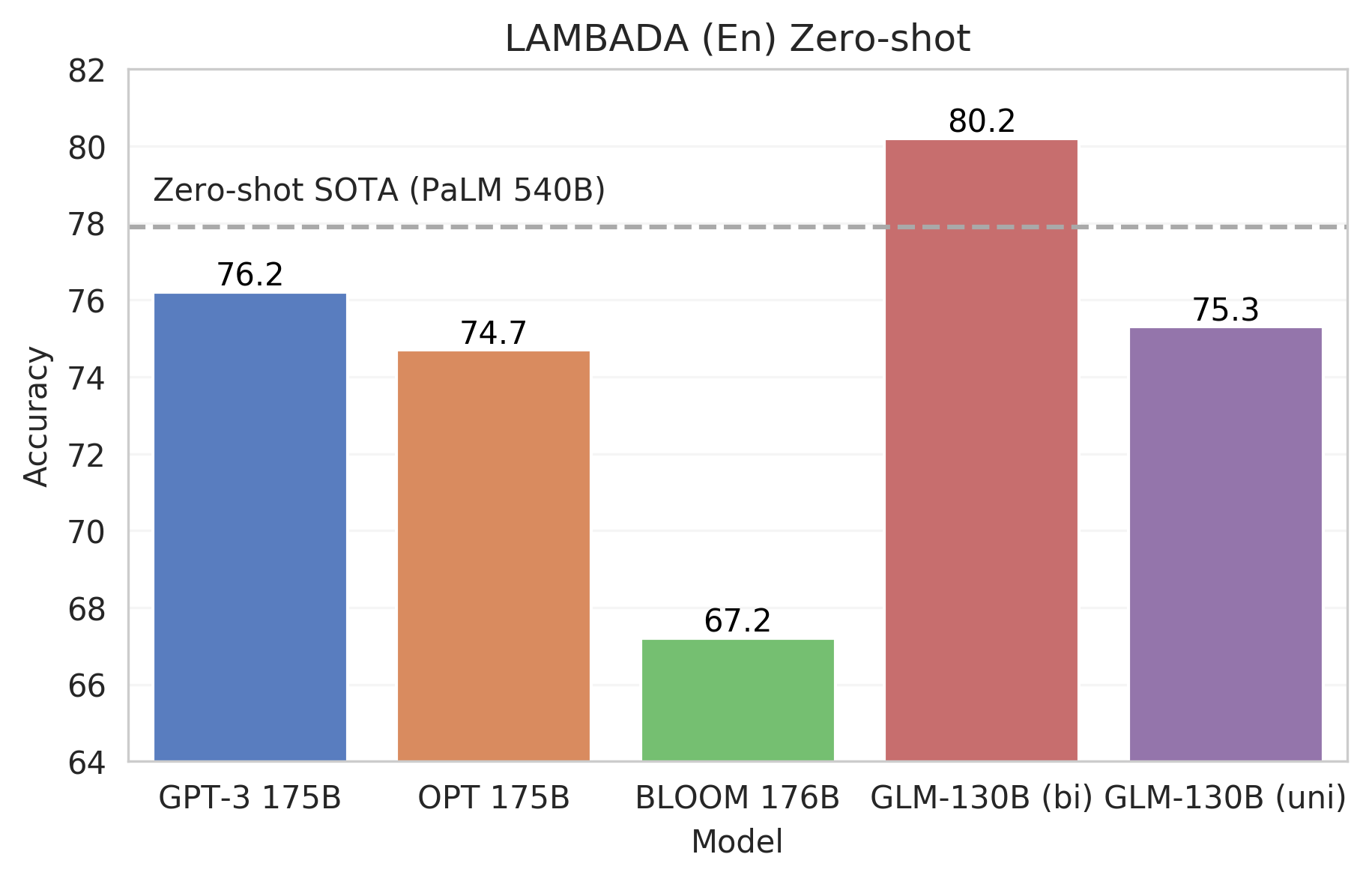
(2)性能 (EN):在 LAMBADA 上优于 GPT-3 175B (+4.0%)、OPT-175B (+5.5%) 和 BLOOM-176B (+13.0%),略优于 GPT-3 175B (+0.9%)在 MMLU 上。
(3)性能 (CN):在 7 个零样本 CLUE 数据集 (+24.26%) 和 5 个零样本 FewCLUE 数据集 (+12.75%) 上明显优于 ERNIE TITAN 3.0 260B。
(4)快速推理:使用单个 A100 服务器支持对 SAT 和 FasterTransformer 的快速推理(速度提高 2.5 倍)。
(5)可重现性:所有结果(30 多个任务)都可以通过开源代码和模型检查点轻松重现。
(6)跨平台:支持在 NVIDIA、Hygon DCU、Ascend 910 和 Sunway(即将发布)上进行训练和推理。
代码下载:https://github.com/THUDM/GLM-130B
博客地址:https://models.aminer.cn/glm-130b/
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢