
论文:Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition
论文链接:https://arxiv.org/abs/2204.05544
发表方:华为云,发表在NAACL 2022 Findings
现在很多基于填表方式的NER方法,在构造表中元素的时候,一般用的都是由相应span的head字和tail字的表征得到的,而本文在此基础上加入了从span中所有字的表征中抽取出来的特征,下面介绍一下具体怎么搞。
1. 论文出发点
中文没有天然的单词边界,所以中文的的NER比英文的还要难一些。这两年NER有一个很好的点子就是引入外部词典,显式的告诉模型哪些字的组合在中文中是一个词,从而给模型注入一些先验的字与字之间的关系,取得了很好的效果,比如Lattice LSTM、FLAT、LEBERT等。但这类方法都需要提供一个外部词典,外部词典的质量就尤为重要了。本文的想法就是「不依赖外部字典,让模型自己去学习实体内字与字之间的关联,以及实体之所以会是某一个类型的实体的规律」。为了实现这个想法, 本文提出了两个idea:
- 「探索实体内部的组成规律——“命名规律性”,用来增强实体的边界监测和类型预测。」
本文的作者们发现很多常规实体类型(LOC、ORG等)都有“「命名规律性」”,就是说「某个实体类型的mentions都有某种内部的构成模式,如果模型学习到了这种内部的构成结构,那么对于识别实体的边界以及预测实体的类型会有一定的帮助」。举个例子,比如以“公司”或者“银行”等词结尾的实体,一般就是ORG,再比如,图1中“尼日尔河流经尼日尔与尼日利亚”中就有一个规律,“XX+河”大部分情况下就是和地理位置相关的实体类型(LOC),虽然“流”字的右边是“经”也可以组成“流经”这个词,导致“流”字这里有边界模糊问题,但是如果模型可以学到“XX+河”这个命名规律,那么大概率还是会把"尼日尔河"作为一个实体识别出来的。

- 「利用上下文来缓解仅依赖命名规律性无法完全确定实体边界的问题」
有的时候仅依赖命名规律性,可能会造成一些冤假错案,这时候「可以通过上下文来缓解命名规律性对边界的决定性影响」,比如图1中“中国队员们在本次比赛中取得了优异成绩”中,XX+队是一个pattern的话,但实际上实体并不是“中国队”,这时候只利用命名规律性来判别实体边界和类型就会出问题,需要看上下文了。
可以看出,本文的方法是要在上两者之间取一个平衡。
2. RICON模型
本文提出的这个模型叫做「R」egularity-「I」nspired re「CO」gnition 「N」etwork (「RICON」),采用是「填表」的方式进行标注,也就是搞一个word-word表,表中每一个元素表示相应的span是什么类型的实体。
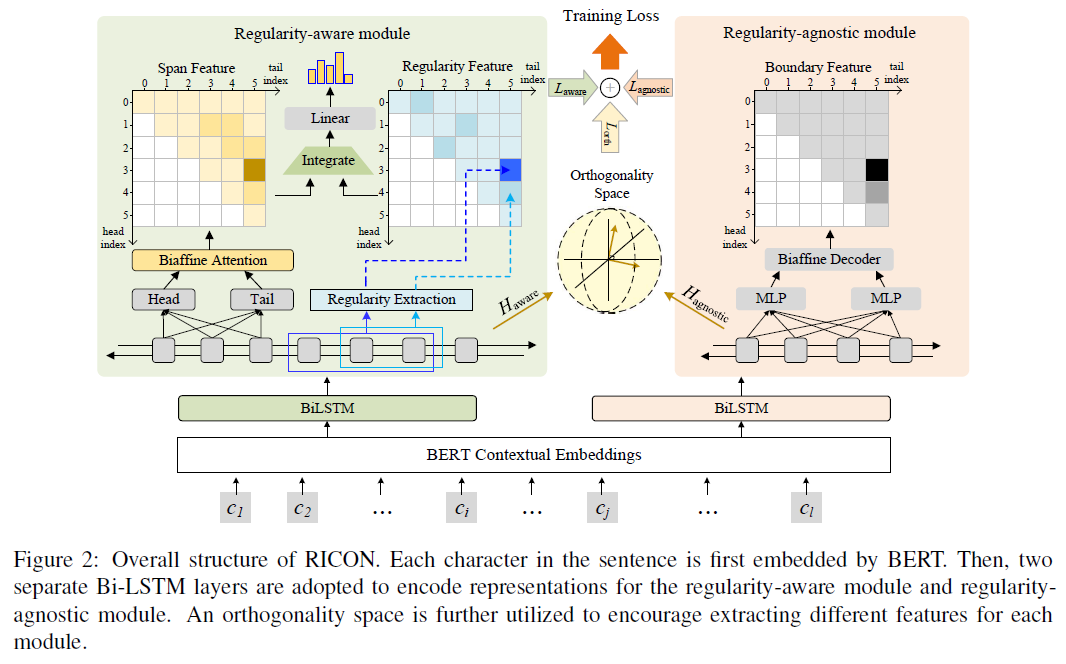
RICON模型结构
如上图所示,模型主要有两个模块:
- 「Regularity-aware Module(规律感知模块)」:这个模块负责分析span内部的规律,进而获取结合了规律的span表征,然后用于实体类型的预测;
- 「Regularity-agnostic Module (规律判断模块)」:这个模块主要获取span上下文的表征,然后用于判断这个实体到底是不是一个实体。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢