
论文标题:Shunted Self-Attention via Multi-Scale Token Aggregation
论文地址:https://arxiv.org/abs/2111.15193
代码地址:https://github.com/oliverrensu/shunted-transformer
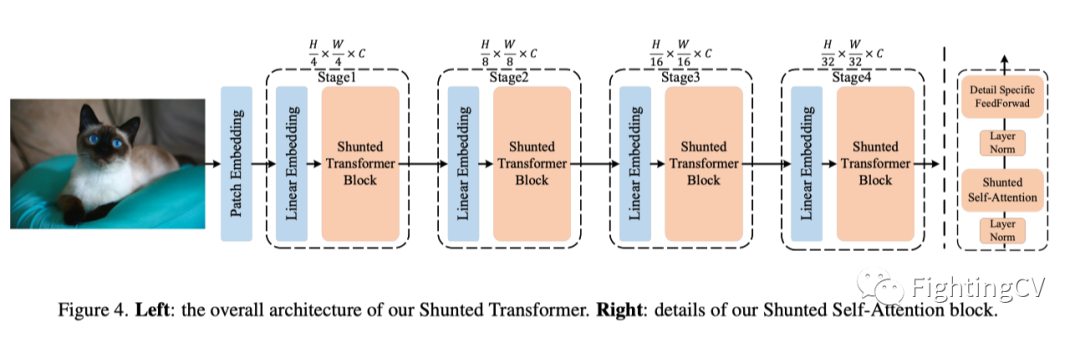
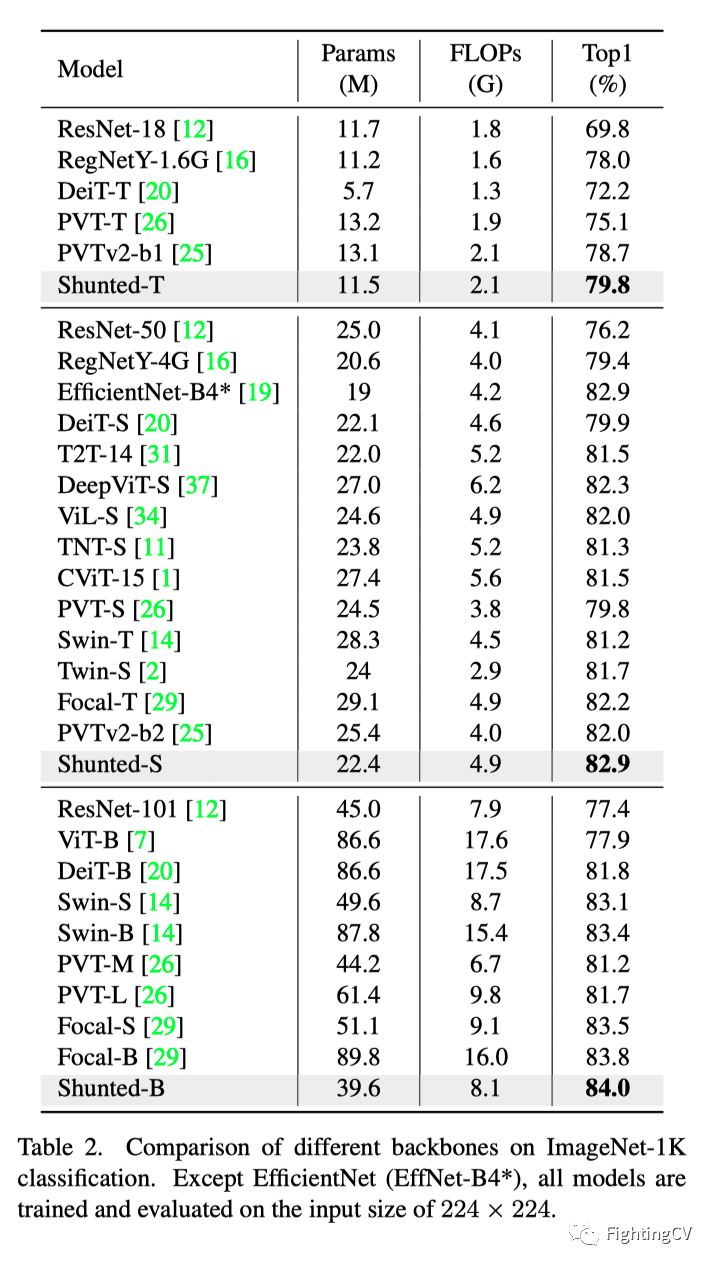
本文提出的分流Transformer的整体架构如上图所示。它建立在新型分流自注意力(SSA)块的基础上。本文的SSA块与ViT中的传统自注意力块有两个主要区别:1)SSA为每个自注意力层引入了分流注意力机制,以捕获多粒度信息和更好地建模不同大小的对象,尤其是小对象;2) 它通过增强跨token交互,增强了在逐点前馈层提取局部信息的能力。此外,本文的分流Transformer部署了一种新的patch嵌入方法,用于为第一个注意力块获得更好的输入特征图。在下文中,作者将逐一阐述这些新颖之处。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢