

论文地址:https://arxiv.org/abs/2206.08358
导读
数据增强是提高深度学习中数据效率的必要条件。对于视觉语言预训练,数据仅在以前的作品中针对图像或文本进行增强。在本文中,作者提出了MixGen:一种用于视觉语言表示学习的联合数据增强,以进一步提高数据效率。它通过插入图像和连接文本来生成具有语义关系的新图像-文本对。它很简单,可以即插即用到现有的pipeline中。
作者在四种架构上评估 MixGen,包括 CLIP、ViLT、ALBEF 和 TCL,跨越五个下游视觉语言任务,以展示其多功能性和有效性。例如,在 ALBEF 预训练中添加 MixGen 会导致下游任务的绝对性能提升:图像文本检索(COCO 微调 +6.2% 和 Flicker30K Zero-shot +5.3%),视觉Grounding(+0.9% RefCOCO+)、视觉推理(在 NLVR2 上 +0.9%)、视觉问答(在 VQA2.0 上 +0.3%)和视觉entailment(在 SNLI-VE 上 +0.4%)。
贡献
近年来,视觉语言表示学习研究出现了爆炸式增长。在联合模态学习中,模型跨模态提取丰富的信息以学习更好的潜在表示。然而,这些模型通常使用数千个 GPU 在大量图像-文本对上进行训练。
例如,CLIP仅使用zero-shot就能达到 ResNet-50 在 ImageNet 上的准确度,但它在 256 个 V100 GPU 上使用 400M 图像-文本对训练了 12 天。此外,这些大规模数据集中的大多数都不能公开访问。即使它们可用,对现有方法的复制和进一步改进对于计算资源有限的研究人员来说也是具有挑战性的。
数据增强广泛用于深度学习,以提高数据效率并在计算机视觉 (CV)和自然语言处理 (NLP)的模型训练期间提供明确的正则化。然而,将现有的数据增强技术应用于视觉语言学习并不简单。在图像-文本对中,图像和文本都包含相互匹配的丰富信息。
直观地说,希望它们的语义在数据增强后仍然匹配。例如,考虑一个带有成对句子“一只白狗在绿色草坪的右角玩耍”的图像。对该图像应用裁剪、颜色更改和翻转等数据增强方法可能需要同时更改其配对句子中的颜色和位置词。
为了保留语义关系,以前的工作对视觉或文本模态进行了温和的数据增强。ViLT和后续作品采用 RandAugment用于没有颜色反转的图像增强。CLIP和 ALIGN仅使用随机调整大小的裁剪,没有其他图像增强。在语言方面,大多数文献只是将文本数据增强留给掩蔽语言建模来处理。也有使用协同增强的工作,但仅针对特定的下游任务设计,而不是通用的视觉语言预训练。
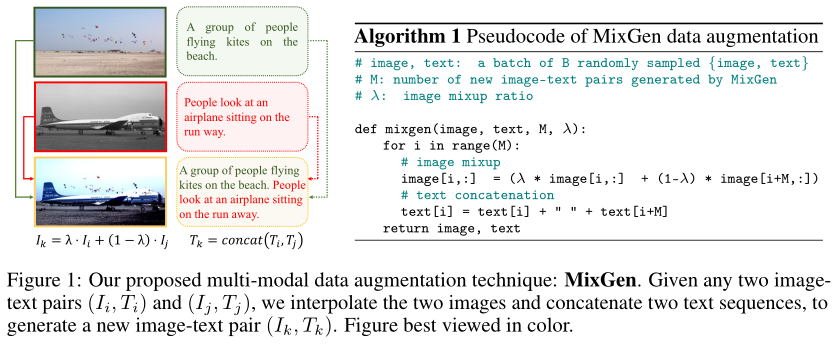
在这项工作中,作者提出了一种用于预训练的多模态联合数据增强方法:混合生成(MixGen)。如上图所示,MixGen 通过线性插值图像并连接来自两个现有图像-文本对的文本序列来生成新的训练样本。
可以看到,大多数对象和场景布局都保留在混合图像中,而文本信息则完全保留。在大多数情况下,新生成的图像-文本对内的语义关系是匹配的。因此,可以使用增强数据来改进模型训练。
尽管它很简单,但在强baseline(例如 ALBEF)之上使用 MixGen 始终可以提高五个下游视觉语言任务的最先进性能:图像文本检索(COCO 微调 +6.2% 和 Flicker30K Zero-Shot +5.3%)、视觉Grounding(RefCOCO+ 上 +0.9%)、视觉推理(NLVR2 上 +0.9%)、视觉问答(VQA2.0 上 +0.3%)和视觉entailment(+0.4% 上SNLI-VE)。
MixGen 还提高了数据效率,例如,在 1M/2M/3M 样本上进行预训练时,使用 MixGen 的 ALBEF 的性能分别与在 2M/3M/4M 样本上预训练的 ALBEF 相匹配。此外,作者进行了广泛的消融研究,以了解 MixGen 中各种设计选择的影响。最后,只需几行代码,MixGen 就可以集成到大多数方法中。
在 COCO 上的微调图像文本检索方面,MixGen 对四种流行且多样的架构带来了绝对的改进:ViLT (+17.2%)、CLIP (+4.1%)、ALBEF (+7.0%) 和 TCL (+3.2%)。
方法
作者提出了多模态联合数据增强技术:混合生成(MixGen)。假设有一个包含 N 个图像-文本对的数据集,其中图像和文本分别用下标表示为 I 和 T。给定两个图像-文本对(Ii,Ti)和(Ij,Tj),其中。一个新的训练样本(Ik,Tk)通过以下方法得到: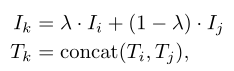
其中 λ 是介于 0 和 1 之间的超参数,表示两个图像Ii和Ij的原始像素之间的线性插值;concat 运算符直接连接两个文本序列Ti和Tj以最好地保留原始信息。这样,新生成的图文对(Ik,Tk)内的语义关系在大多数场景下仍然成立,如上图所示。这种图文样本的随机组合也增加了模型训练的多样性,这导致提供稀有的概念。
给定 B 个随机采样的图像-文本对的 mini-batch,MixGen 将前 M 个训练样本替换为新的生成样本。因此,mini-batch大小、总训练迭代次数和总训练pipeline保持不变。默认情况下,作者在算法中设置λ=0.5和M=B/4。这种即插即用的技术可以很容易地融入大多数视觉语言表示学习方法和任务中:只需要几行代码具有最小计算开销的代码。
3.1. MixGen variants
MixGen 的形式非常简单。但是,根据图像和文本增强的执行方式,可能会有多种变体。从理论上讲,还可以对混合之外的图像使用其他增强,以及连接之外的其他文本增强,但是设计空间将是棘手的。因此,作者专注于对图像使用混合,对文本使用连接,并选择 5 个最直接的 MixGen 变体来支持本文最终的设计选择。
由于默认的 MixGen 采用固定的 λ,作者引入了具有 λ ∼ Beta(0.1, 0.1) 的变体 (a),遵循从 Beta 分布中采样 λ 的原始 mixup 。为了展示执行联合图像文本增强的好处,作者提出了变体 (b) 和 (c)。具体来说,变体(b)混合两个图像并统一选择一个文本序列,而变体(c)连接两个文本序列并统一选择一个图像。最后,作者研究是否应该使用token子集,而不是连接来自两个文本序列的所有token。
变体 (d) 基于与图像混合相似的 λ 按比例从两个文本序列中获取token,然后连接。另一个变体 (e) 首先连接所有token,但随机保留其中一半以生成新的文本序列。
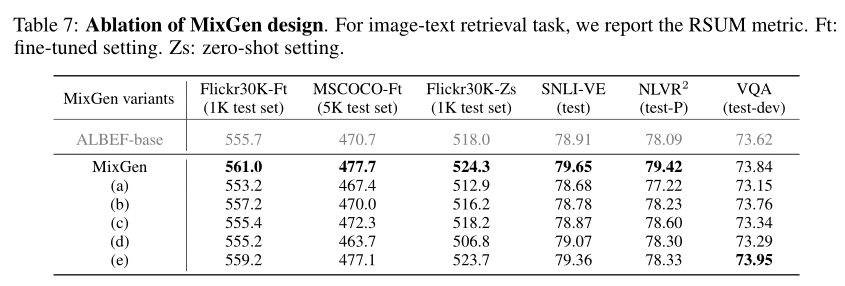
上表中可以看到这 5 个变体的更详细定义。作者还对它们进行了广泛的消融研究。从下表中可以看出,默认 MixGen 实现了整体最佳性能,并且在四种不同的视觉语言下游任务中始终优于其他变体。
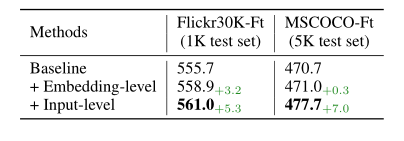
3.2. Input-level and embedding-level MixGen
另一个设计视角是在哪里应用数据增强。上面的公式直接在原始输入上执行,例如图像和文本序列。或者,可以将 MixGen 的思想应用于嵌入级别。具体来说,可以对从图像编码器中提取的图像特征进行插值,而不是对原始图像像素进行插值。
类似地,可以连接从文本编码器中提取的两个序列特征,而不是连接两个文本序列。将关于嵌入的训练对表示为(fIi,fTi)和(fIj,fTj),新生成的嵌入形式的训练对为: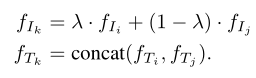
将在原始输入上执行的 MixGen 称为输入级别 MixGen,在嵌入级别执行的称为嵌入级别 MixGen。正如下表中所示,输入级 MixGen 始终比嵌入级 MixGen 表现更好。此外,输入级 MixGen 具有实现简单的优点,因为不需要修改网络架构,也不需要更改模型的forward。
实验
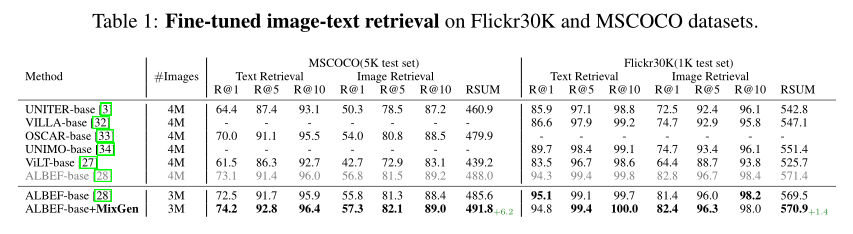
对于上表中的微调结果,可以看到 MixGen 在两个数据集上始终优于 ALBEF baseline。在 3M 设置下,简单地添加 MixGen 而不做任何修改会导致 COCO 的 RSUM 分数提高 6.2%,Flicker30K 的 RSUM 分数提高 1.4%。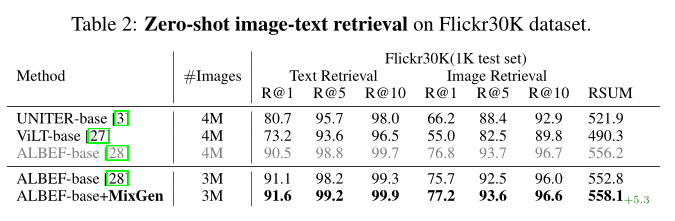
对于上表中的zero-shot结果,可以观察到类似的结论。在3M 设置下,MixGen 导致 Flicker30K 上的 RSUM 得分提高了 5.3%。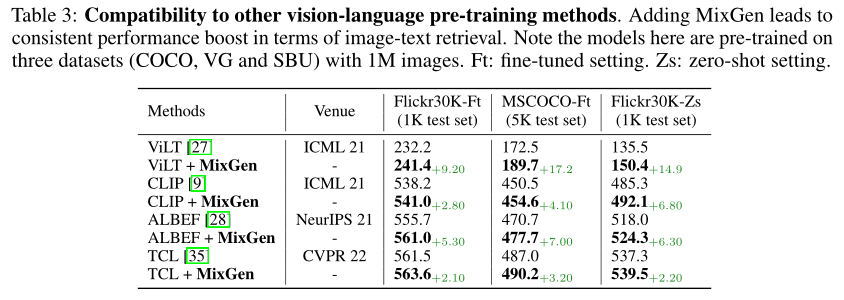
此外,作者展示了 MixGen 与其他视觉语言预训练方法的兼容性,即 CLIP、ViLT 和 TCL。鉴于 ViLT 训练非常昂贵(例如,使用 64 个 V100 GPU 需要 3 天),作者在本实验的预训练期间仅使用三个数据集(COCO、VG 和 SBU)。
如上表所示,在这些强大的baseline之上简单地添加 MixGen 可以持续提高最先进的性能。在 COCO 上的微调图像文本检索方面,MixGen 显示出显着的准确度提升(绝对):ViLT (+17.2%)、CLIP (+4.1%)、ALBEF (+7.0%) 和 TCL (+3.2%)。这显示了 MixGen 在预训练中作为图像文本数据增强的多功能性。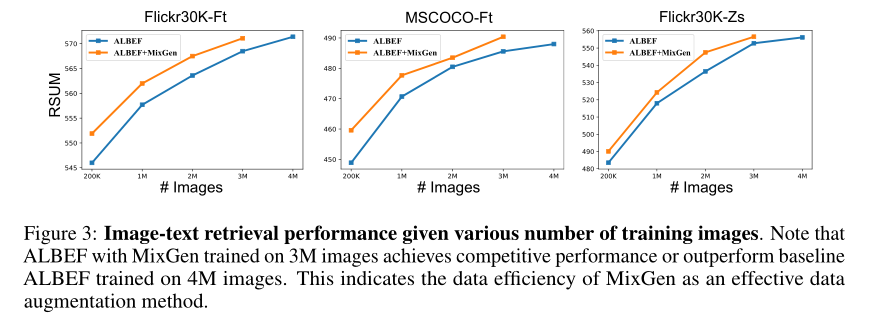
最后,作者研究了 MixGen 可以实现多少数据效率。作者将用于预训练的图像数量从 3M 减少到 2M、1M 和 200K。对于 2M,作者使用三个数据集加上来自 CC 数据集的随机子集。对于 200K,作者只使用两个数据集(COCO 和 VG)。上图中可以看到图文检索的性能。
首先注意到添加 MixGen 总是比没有它好。尤其是低数据制度的改善更为显着。其次,在 1M、2M 和 3M 样本上训练时使用MixGen 的 ALBEF 的性能分别与在 2M、3M 和 4M 样本上训练时的baseline ALBEF 相匹配。这再次表明了 MixGen 的数据效率。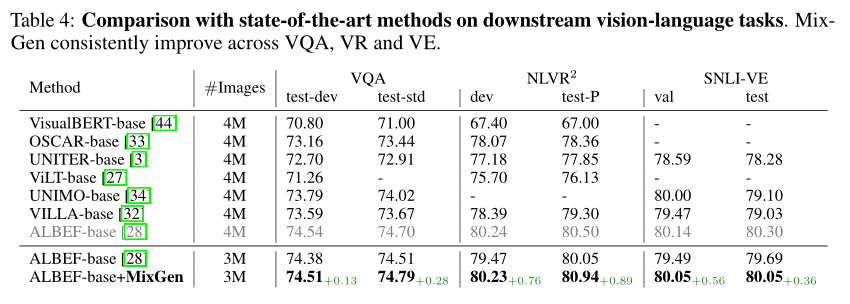
上表报告了不同视觉语言预训练baseline在下游 VQA、VR 和 VE 任务上的性能比较。与图像-文本检索任务类似,MixGen 不断提升这三个任务的性能。在 3M 设置下,使用 MixGen 的 ALBEF 在 VQA test-std 上绝对优于其相应的baseline 0.28%,在 NLVR2 test-P 上优于 0.89%,在 SNLI-VE 测试上优于 0.36%。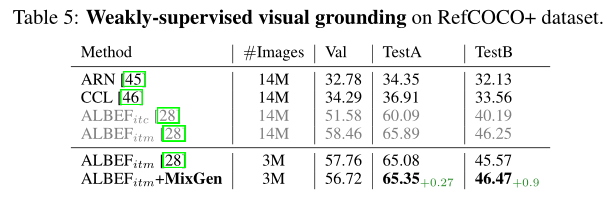
上表报告了 RefCOCO+ 数据集上视觉grounding的性能。
在上图中,作者展示了 MSCOCO 上文本到图像检索的可视化。具体来说,给定一个文本查询,希望在使用和不使用 MixGen 的 ALBEF 之间比较所有检索到的图像中检索到的真实图像的排名。可以看到,MixGen 通常能够在 top-3 检索中定位匹配图像,性能明显优于baseline ALBEF。
在上图中,作者展示了 Grad-CAM 可视化,以帮助理解为什么 MixGen 是有益的。对于 RefCOCO+ 数据集的视觉grounding任务,可以看到使用 MixGen 训练的模型可以根据文本查询更精确地定位图像区域。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢