
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于自调节扩散模型的离散数据生成、有效扩展Transformer以实现长输入摘要、口语对话智能体启动点预测、用熵损失实现鲁棒深度学习、从稀疏视图平面到3D重建、面向量子技术的人工智能和机器学习、Frozen CLIP模型是高效的视频学习器、统计物理学采样算法、基于现代Hopfield网络用文本生成遥感图像
1、[CV] Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning
T Chen, R Zhang, G Hinton
[Google Research]
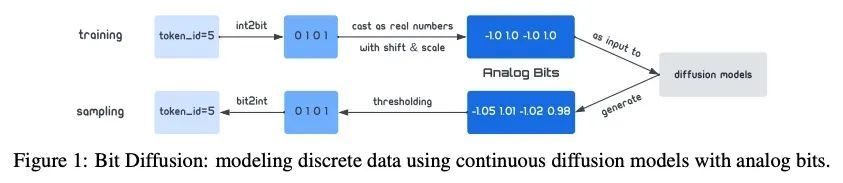
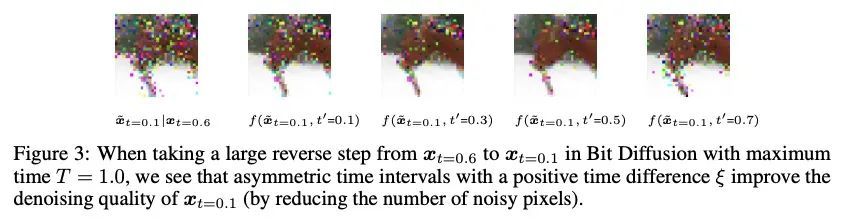
Analog Bits: 基于自调节扩散模型的离散数据生成。本文提出了比特扩散(Bit Diffusion):一种用连续扩散模型生成离散数据的简单和通用方法。主要思想是首先将离散数据表示为二进制比特,然后训练一个连续扩散模型,将这些比特模拟为实数,称为模拟比特。为了生成样本,模型首先生成模拟比特,然后对其进行阈值处理,得到代表离散变量的比特。本文进一步提出两种简单技术,即自我调节和不对称时间间隔,实现了样本质量的显著改善。尽管很简单,但所提出方法在离散图像生成和图像描述任务中都能取得强大的性能。对于离散图像生成,在CIFAR-10(有3K个离散的8位标记)和IMAGENET 64×64(有12K个离散的8位标记)上较之前的最先进技术都有很大改进,在样本质量(用FID衡量)和效率上都超过了最佳自回归模型。对于MS-COCO数据集上的图像描述,所提出方法与自回归模型相比取得了有竞争力的结果。
We present Bit Diffusion: a simple and generic approach for generating discrete data with continuous diffusion models. The main idea behind our approach is to first represent the discrete data as binary bits, and then train a continuous diffusion model to model these bits as real numbers which we call analog bits. To generate samples, the model first generates the analog bits, which are then thresholded to obtain the bits that represent the discrete variables. We further propose two simple techniques, namely Self-Conditioning and Asymmetric Time Intervals, which lead to a significant improvement in sample quality. Despite its simplicity, the proposed approach can achieve strong performance in both discrete image generation and image captioning tasks. For discrete image generation, we significantly improve previous state-of-the-art on both CIFAR-10 (which has 3K discrete 8-bit tokens) and IMAGENET 64×64 (which has 12K discrete 8-bit tokens), outperforming the best autoregressive model in both sample quality (measured by FID) and efficiency. For image captioning on MS-COCO dataset, our approach achieves competitive results compared to autoregressive models.
https://arxiv.org/abs/2208.04202



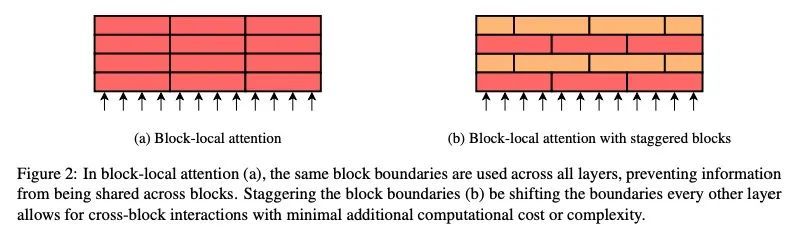
2、[CL] Investigating Efficiently Extending Transformers for Long Input Summarization
J Phang, Y Zhao, P J. Liu
[New York University & Google Research]
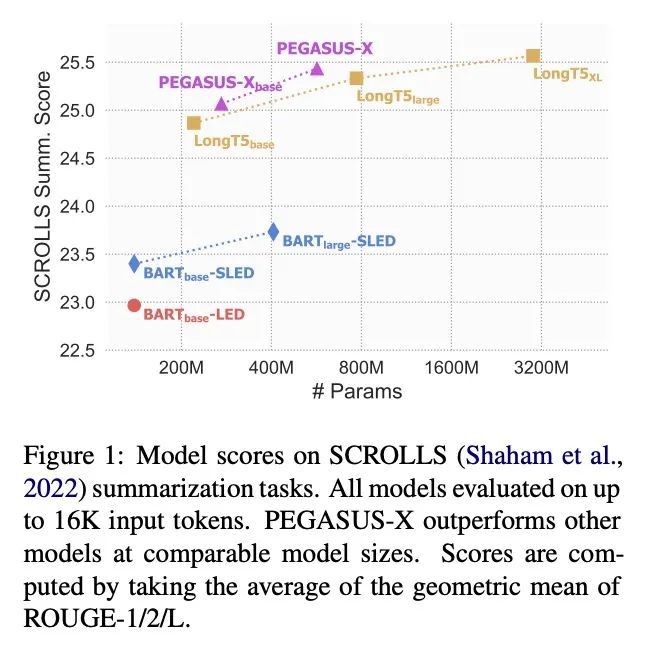
有效扩展Transformer以实现长输入摘要。虽然大型预训练Transformer模型已经证明在处理自然语言任务方面有很强的能力,但处理长序列输入仍然是一个重大挑战。其中一项任务是长输入摘要,即输入长度超过大多数预训练模型的最大输入范围。通过一系列广泛的实验,本文研究了哪些模型结构变化和预训练范式可以最有效地使预训练的Transformer适应长输入摘要。结果发现,一个交错的、具有全局编码器Token的块局部Transformer在性能和效率之间取得了良好的平衡,而对长序列的额外预训练阶段则有意义地提高了下游的摘要性能。基于该发现,本文提出PEGASUS-X,PEGASUS模型的扩展,带有额外的长输入预训练,以处理多达16K标记的输入。PEGASUSX在长输入的摘要任务上取得了强大的性能,可以与更大的模型相媲美,同时增加了很少的额外参数,不需要模型的并行训练。
While large pretrained Transformer models have proven highly capable at tackling natural language tasks, handling long sequence inputs continues to be a significant challenge. One such task is long input summarization, where inputs are longer than the maximum input context of most pretrained models. Through an extensive set of experiments, we investigate what model architectural changes and pretraining paradigms can most efficiently adapt a pretrained Transformer for long input summarization. We find that a staggered, blocklocal Transformer with global encoder tokens strikes a good balance of performance and efficiency, and that an additional pretraining phase on long sequences meaningfully improves downstream summarization performance. Based on our findings, we introduce PEGASUS-X, an extension of the PEGASUS model with additional long input pretraining to handle inputs of up to 16K tokens. PEGASUSX achieves strong performance on long input summarization tasks comparable with much larger models while adding few additional parameters and not requiring model parallelism to train.
https://arxiv.org/abs/2208.04347
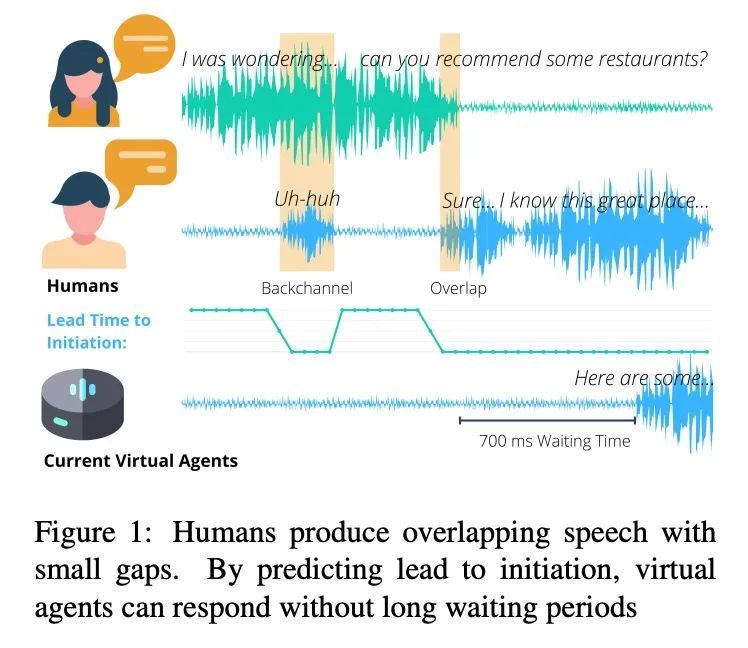
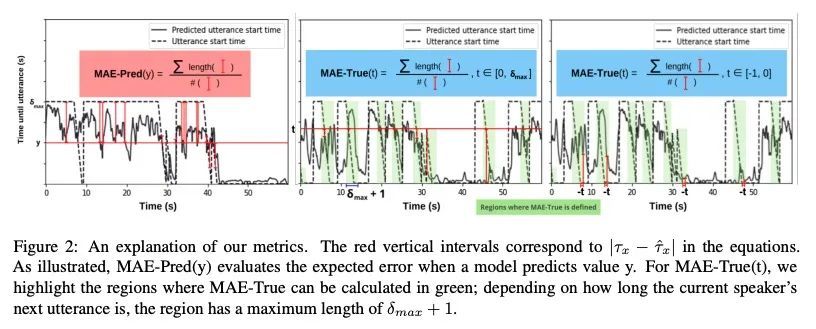
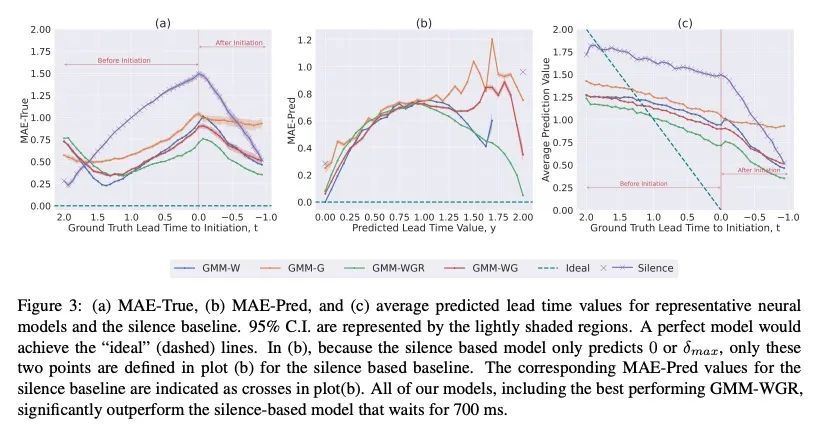
3、[CL] When can I Speak? Predicting initiation points for spoken dialogue agents
S Li, A Paranjape, C D. Manning
[Stanford University]
什么时候该说话?口语对话智能体启动点预测。目前的口语对话系统在很长一段时间的沉默(70-100000ms)后开始一个回合,这导致很少的实时反馈、迟缓的反应和整体僵硬的对话流程。人类通常在200毫秒内做出反应,而成功提前预测启动点,将使口语对话智能体也能做到这一点。本文用预训练好的语音表示模型(wav2vec 1.0)的声音特征来预测启动时间,该模型在用户音频上运行,词特征则来自预训练好的语言模型(GPT-2)处理的增量转录。为评估误差,本文提出两个指标,即预测时间和真实提前量。在Switchboard语料库上训练和评估了这些模型,发现所提出方法在这两个指标上都优于之前工作中的特征,并大大优于等待700ms的沉默的常见方法。
Current spoken dialogue systems initiate their turns after a long period of silence (7001000ms), which leads to little real-time feedback, sluggish responses, and an overall stilted conversational flow. Humans typically respond within 200ms and successfully predicting initiation points in advance would allow spoken dialogue agents to do the same. In this work, we predict the lead-time to initiation using prosodic features from a pre-trained speech representation model (wav2vec 1.0) operating on user audio and word features from a pre-trained language model (GPT-2) operating on incremental transcriptions. To evaluate errors, we propose two metrics w.r.t. predicted and true lead times. We train and evaluate the models on the Switchboard Corpus and find that our method outperforms features from prior work on both metrics and vastly outperforms the common approach of waiting for 700ms of silence.
https://arxiv.org/abs/2208.03812

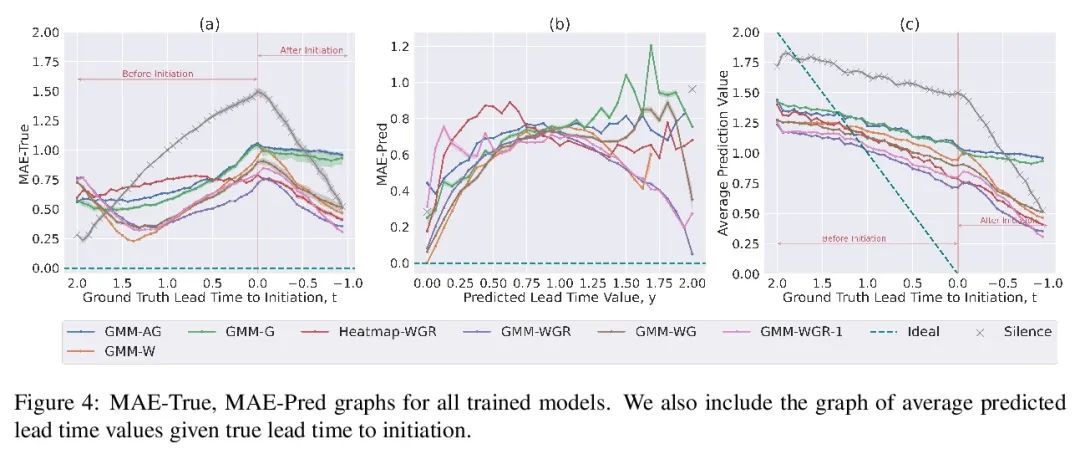
4、[LG] Towards Robust Deep Learning using Entropic Losses
D Macêdo
[Universidade Federal De Pernambuco]
用熵损失实现鲁棒深度学习。目前的深度学习解决方案,因在推理过程中不能告知它们是否能可靠地对一个样本进行分类而闻名。建立更可靠的深度学习解决方案的最有效方法之一,是提高它们在所谓的分布外检测任务中的表现,基本上可以表述成"知道你不知道"或"知道未知"。换句话说,当提交给神经网络没被训练过的类的实例时,具有分布外检测能力的系统可能会拒绝执行一个无意义的分类。本论文通过提出新的损失函数和检测分数,来解决分布外检测任务。不确定性估计也是构建更鲁棒深度学习系统的一个重要辅助任务。因此,本文也处理这个与鲁棒性有关的任务,评估了深度神经网络提出的概率的现实程度。为证明所提出方法的有效性,除了大量的实验(其中包括最先进的结果),本文用基于最大熵原则的论证来建立所提出方法的理论基础。与目前大多数方法不同,所提出的损失和分数是无缝和原则性的解决方案,除了快速和高效推理外,还能产生准确的预测。此外,所提出方法可以纳入当前和未来的项目中,只需替换用于训练深度神经网络的损失,并计算出一个快速检测的分数。
Current deep learning solutions are well known for not informing whether they can reliably classify an example during inference. One of the most effective ways to build more reliable deep learning solutions is to improve their performance in the so-called out-of-distribution detection task, which essentially consists of "know that you do not know" or "know the unknown". In other words, out-of-distribution detection capable systems may reject performing a nonsense classification when submitted to instances of classes on which the neural network was not trained. This thesis tackles the defiant out-of-distribution detection task by proposing novel loss functions and detection scores. Uncertainty estimation is also a crucial auxiliary task in building more robust deep learning systems. Therefore, we also deal with this robustness-related task, which evaluates how realistic the probabilities presented by the deep neural network are. To demonstrate the effectiveness of our approach, in addition to a substantial set of experiments, which includes state-of-the-art results, we use arguments based on the principle of maximum entropy to establish the theoretical foundation of the proposed approaches. Unlike most current methods, our losses and scores are seamless and principled solutions that produce accurate predictions in addition to fast and efficient inference. Moreover, our approaches can be incorporated into current and future projects simply by replacing the loss used to train the deep neural network and computing a rapid score for detection.
https://arxiv.org/abs/2208.03566

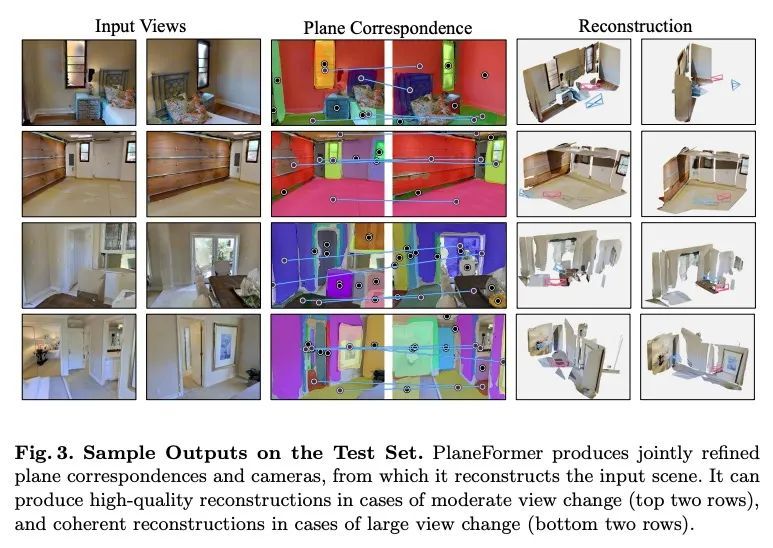
5、[CV] PlaneFormers: From Sparse View Planes to 3D Reconstruction
S Agarwala, L Jin, C Rockwell, D F. Fouhey
[University of Michigan]
PlaneFormers: 从稀疏视图平面到3D重建。本文提出一种从重叠度有限的图像中重建场景平面的方法。这一重建任务具有挑战性,因为它需要联合推理单幅图像的3D重建、图像间的对应关系以及图像间的相对相机姿态。之前的工作提出了基于优化的方法。本文引入了一种更简单的方法,即PlaneFormer,用一个应用于3D感知的平面标记的transformer来进行3D推理。实验表明,所提出方法比之前的工作要有效得多,而且几个针对3D的设计对其成功起到了至关重要的作用。
We present an approach for the planar surface reconstruction of a scene from images with limited overlap. This reconstruction task is challenging since it requires jointly reasoning about single image 3D reconstruction, correspondence between images, and the relative camera pose between images. Past work has proposed optimization-based approaches. We introduce a simpler approach, the PlaneFormer, that uses a transformer applied to 3D-aware plane tokens to perform 3D reasoning. Our experiments show that our approach is substantially more effective than prior work, and that several 3D-specific design decisions are crucial for its success.
https://arxiv.org/abs/2208.04307




另外几篇值得关注的论文:
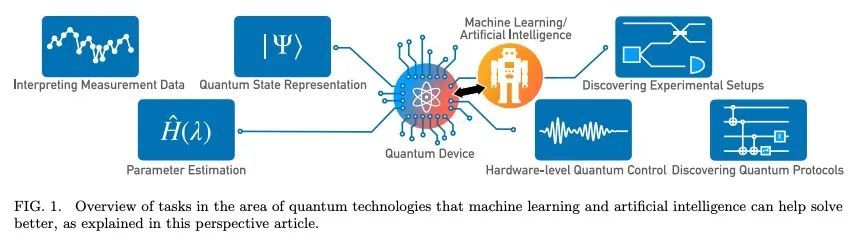
[LG] Artificial Intelligence and Machine Learning for Quantum Technologies
面向量子技术的人工智能和机器学习
M Krenn, J Landgraf, T Foesel, F Marquardt
[Max Planck Institute for the Science of Light]
https://arxiv.org/abs/2208.03836

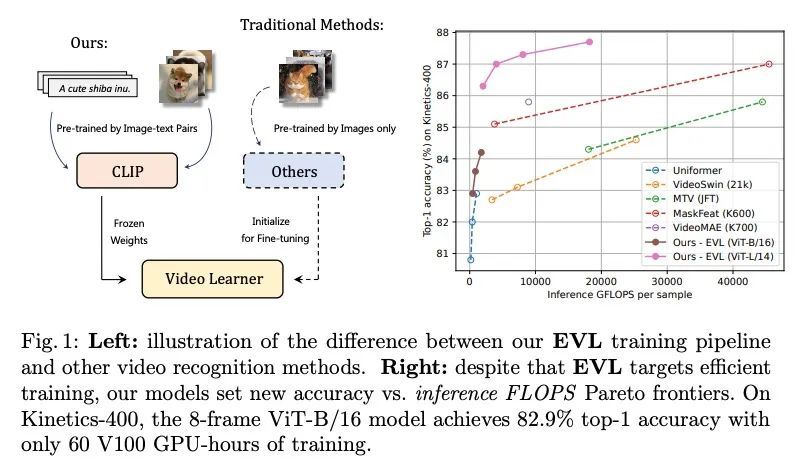
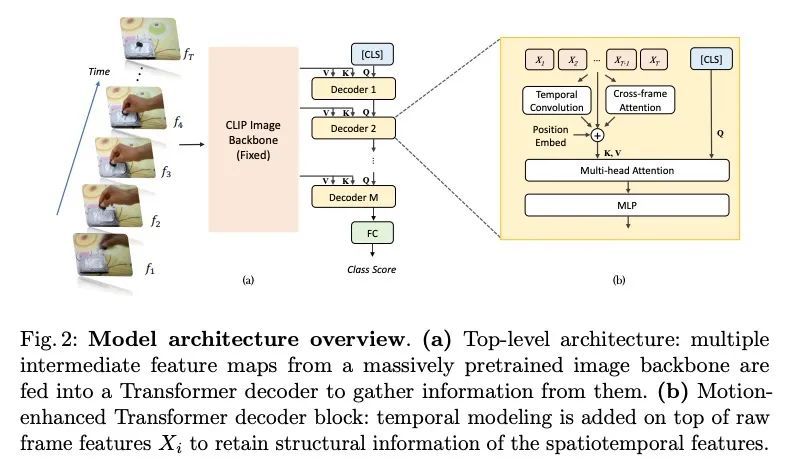
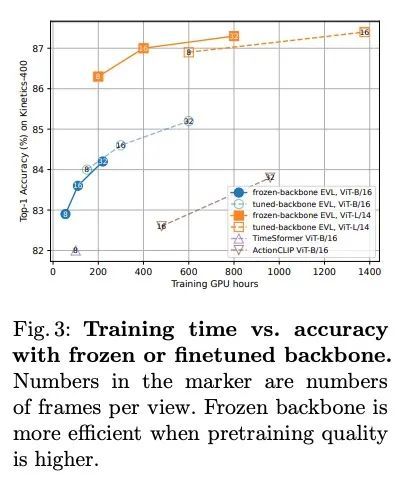
[CV] Frozen CLIP Models are Efficient Video Learners
Frozen CLIP模型是高效的视频学习器
Z Lin, S Geng, R Zhang, P Gao...
[The Chinese University of Hong Kong & Shanghai AI Laboratory & Rutgers University & Hasso Plattner Institute & SenseTime Research]
https://arxiv.org/abs/2208.03550

[LG] Sampling algorithms in statistical physics: a guide for statistics and machine learning
统计物理学采样算法:统计和机器学习指南
M F. Faulkner, S Livingstone
[University of Bristol]
https://arxiv.org/abs/2208.04751

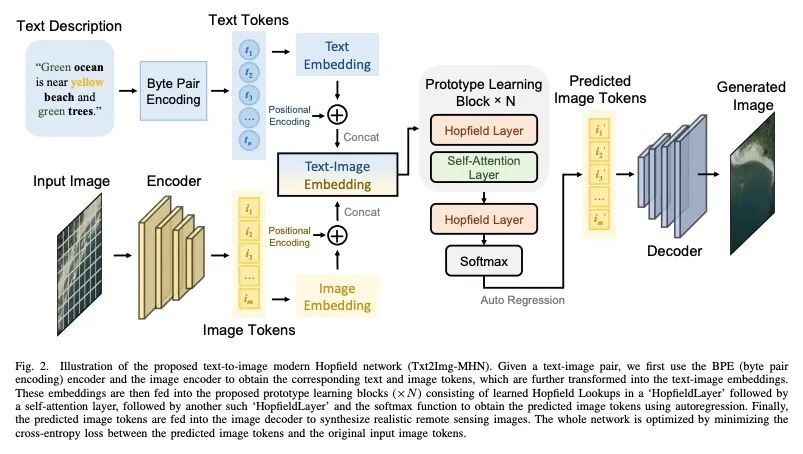
[CV] Txt2Img-MHN: Remote Sensing Image Generation from Text Using Modern Hopfield Networks
Txt2Img-MHN:基于现代Hopfield网络用文本生成遥感图像
Y Xu, W Yu, P Ghamisi, M Kopp, S Hochreiter
[IARAI]
https://arxiv.org/abs/2208.04441


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢