
作者:Bolin Ni, Houwen Peng, Minghao Chen,等
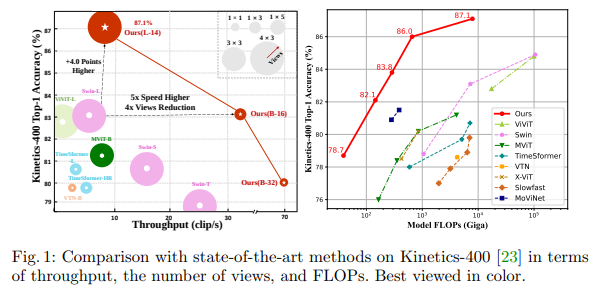
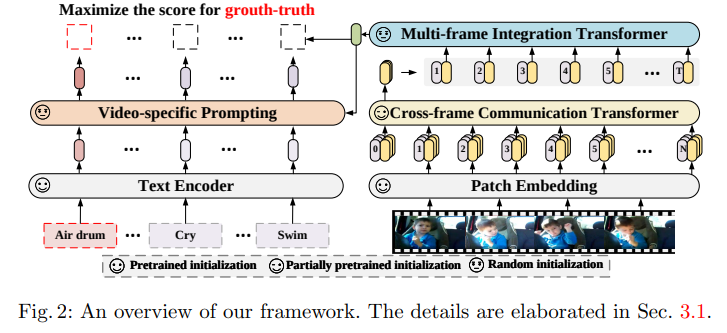
简介:本文研究语言-图像预训练模型在视频识别中跨帧注意机制与提示调优的创新。对比语言-图像预训练在从网络规模数据中学习视觉-文本联合表示方面取得了巨大成功,展示了对各种图像任务的显着“零样本”泛化能力。然而,如何将这种新的语言-图像预训练方法有效地扩展到视频领域仍然是一个悬而未决的问题。在这项工作中,作者提出了一种简单而有效的方法,将预训练的语言图像模型直接应用于视频识别,而不是从头开始预训练一个新模型。更具体地说,为了捕捉帧在时间维度上的长期依赖关系,作者提出了一种跨帧注意机制,可以显式地跨帧交换信息。这样的模块是轻量级的,可以无缝地插入到预训练的语言图像模型中。而且,作者提出了一种特定于视频的提示方案,该方案利用视频内容信息来生成有区别的文本提示。大量实验表明:作者的方法是有效的,并且可以推广到不同的视频识别场景。特别是,在完全监督的设置下,作者的方法在 Kinectics-400 上实现了 87.1% 的 top-1 准确率,而与 Swin-L 和 ViViT-H 相比,使用的 FLOP 减少了 12 倍。在零样本实验中,作者的方法在两种流行协议下的 top-1 准确度方面超过了当前最先进的方法 +7.6% 和 +14.9%。在少样本场景中:当标记的数据极其有限时,作者的方法比以前的最佳方法好 +32.1% 和 +23.1%。
论文下载:https://arxiv.org/pdf/2208.02816.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢