

SdAE: Self-distillated Masked Autoencoder
论文:https://arxiv.org/abs/2208.00449
代码:https://github.com/AbrahamYabo/SdAE
1. 论文动机
介绍了BEIT和PECO的弊端,是需要一个预先训练好的dVAE来提供最后的预测目标。这种tokenizer需要pretrain。
介绍了MAE和splitmask的弊端,就是重建目标和语义理解可能有较大的鸿沟。
文章基于这两个点提出了改进:
a.引入根据EMA更新权重的教师模型,来产生预测目标。
b.其次是通过分析学生分支和教师分支之间的information bottleneck,从而提出一个新的重建的策略。
2. 具体做法
2-1.整体结构
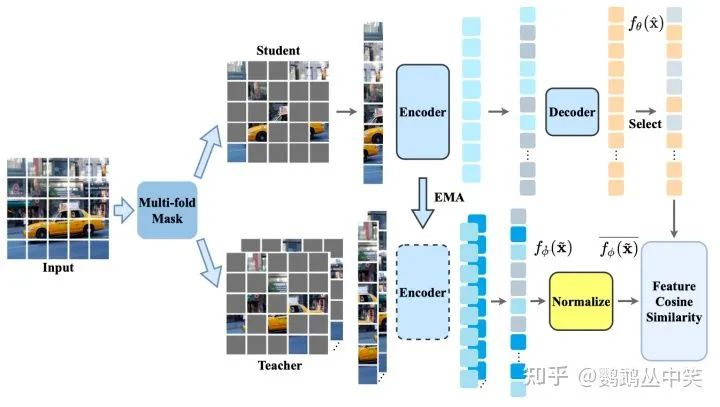
模型结构图
相比于还原像素等low-level的特征,论文采用了教师分支输出特征的方法。并且对教师分支的特征进行Patch内部的归一化。
这部分预测目标的修改,在最近的工作其实比较多,不展开。
2-2. 教师模型的输入
文章通过分析学生分支和教师分支的输入之间的互信息,得出了三个结论。
- 学生分支和教师分支的输入要尽量减少共享的信息,即输入的token避免重叠。
- 学生分支和教师分支的输入的互信息量应该相等,因此文章设计了新的策略使得两个分支输入的patch数量接近。
- 为了保留更多信息,要利用上更多的被遮掩的图像块。
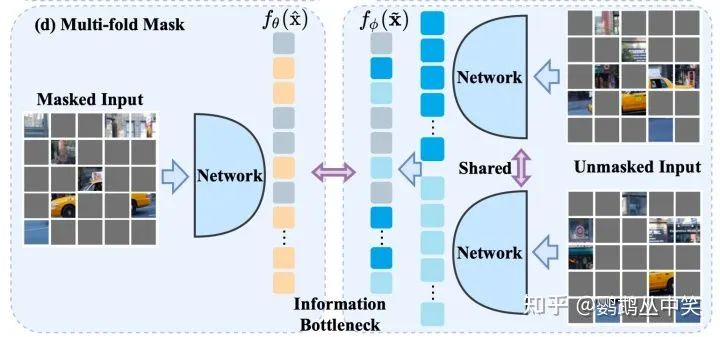
教师模型输入的策略
因此文章提出了新的策略——先将被遮掩的块进行分组,保证每一组的图像块的数量和学生分支输入的数量接近,然后每一组图像块分别通过共享的教师分支的模型,得到相应的特征,作为被预测的对象。
这种新的策略相比于全图输入和被遮掩的块一次性输入,计算速度能有些许提升。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢