

由于 BERT-like 模型在 NLP 领域上的成功,研究者们开始尝试将其应用到更为复杂的 多模态 任务上。要求模型除文本数据以外,还要接收其他模态的数据(比如图像、声音等),在理解和关联多模态数据的基础上,完成更加复杂也更贴近实际的跨模态任务。
而 视觉常识推理 (Visual Commonsense Reasoning,VCR)[1]就是一个非常具有挑战性的多模态任务,需要在理解文本的基础上结合图片信息,基于常识进行推理。给定一张图片、图中一系列有标签的 bounding box,VCR 实际上是两个子任务:{Q->A} 根据问题选择答案;{QA->R} 根据问题和答案进行推理,解释为什么选择该答案。
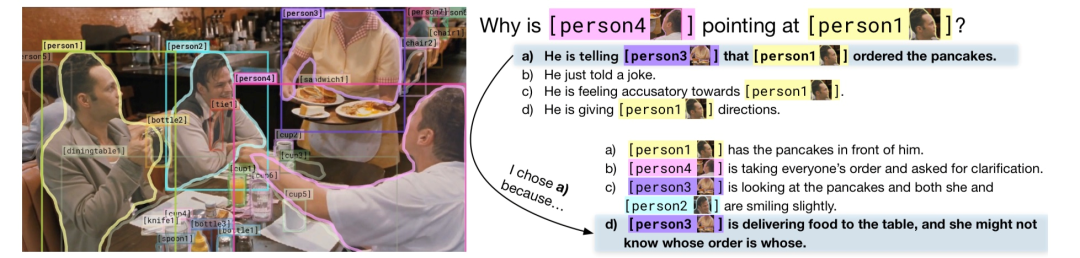
例如,图片中三个朋友聚餐,一名服务员在上菜。Q: 为什么 person 4 指着 person 1?A: 为了告诉 person 3,person 1 点了烤薄饼。R: 之所以这么认为是因为 person 3 是服务员正在上菜,基于常识,服务员通常不知道每道菜是谁点的。
而 VCR 就是由十几万这样的“图片-问答”对组成的数据集,主要考察模型对跨模态的语义理解和常识推理能力。由于该任务非常具有挑战性,所以引来了很多的学术界工业界的大佬前来刷榜参赛[2],包括百度、微软、谷歌、Facebook、UCLA、佐治亚理工学院等等。现在榜单上 TOP2 模型分别为百度 ERNIE 团队的 ERNIE-ViL-large 和微软 D365 AI 团队的 ViLLA-large。下面就来分别看看这两个模型是如何登顶榜单,利用 BERT 跨界解决多模态问题~
论文链接: ERNIE-ViL https://arxiv.org/pdf/2006.16934.pdf
ViLLA https://arxiv.org/pdf/2006.06195.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢