
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:大规模嵌入检索系统的前向兼容训练、半监督学习和域自适应统一方法、从Transformer预训练和微调中得到的启示、视觉表示学习在同域不会显著泛化、基于自适应傅里叶神经算子加速全球高分辨率天气预报、基于上下文感知Transformer的无重影高动态范围成像、图像补全改善的关键、神经机器翻译错觉的综合研究、混合对抗性非对抗案例中的数据学习
1、[CV] Forward Compatible Training for Large-Scale Embedding Retrieval Systems
V Ramanujan, PKA Vasu, A Farhadi…
[University of Washington & Apple]
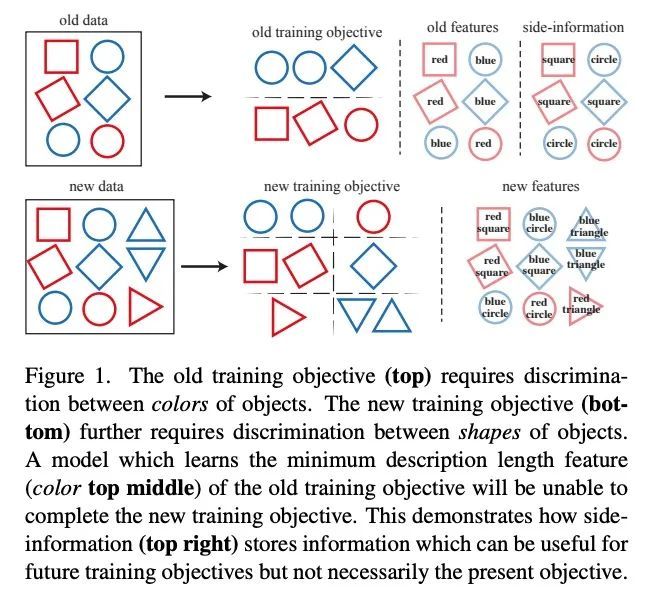
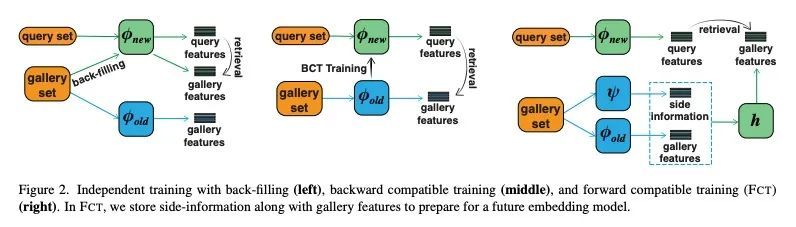
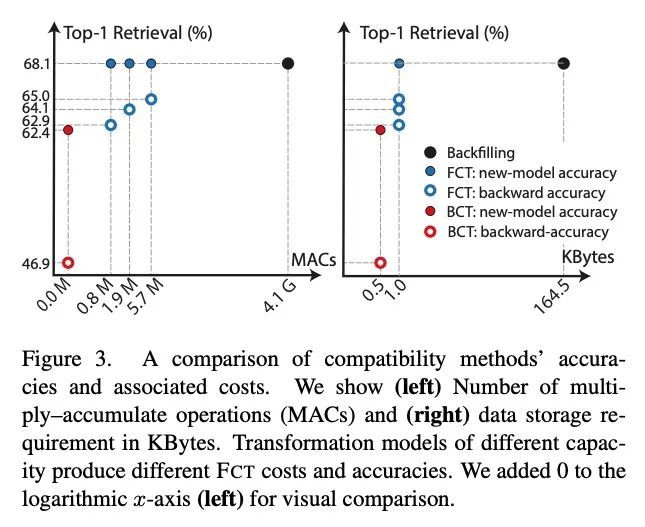
大规模嵌入检索系统的前向兼容训练。在视觉检索系统中,更新嵌入模型需要对每条数据重新计算特征,这个昂贵的过程被称为回填(backfilling)。最近,有人提出了后向兼容训练(BCT)的想法。为避免回填的成本,BCT修改了新模型的训练,使其表示与旧模型的表示兼容。然而,BCT会大大阻碍新模型的性能。本文为表示学习提出一种新的学习范式:前向兼容训练(FCT)。在FCT中,当旧模型被训练时,也为模型的未来未知版本做准备。本文提出side-information学习,即每个样本的辅助特征,这有利于模型的未来更新。为了开发一个强大而灵活的模型兼容性框架,将side-information与从旧嵌入到新嵌入的正向转换结合起来。新模型的训练没有修改,精度也不会降低。实验证明,与BCT相比,各种数据集上的检索精度都有了明显的提高。当新旧模型在不同的数据集、损失和架构上进行训练时,FCT获得了模型的兼容性。
In visual retrieval systems, updating the embedding model requires recomputing features for every piece of data. This expensive process is referred to as backfilling. Recently, the idea of backward compatible training (BCT) was proposed. To avoid the cost of backfilling, BCT modifies training of the new model to make its representations compatible with those of the old model. However, BCT can significantly hinder the performance of the new model. In this work, we propose a new learning paradigm for representation learning: forward compatible training (FCT). In FCT, when the old model is trained, we also prepare for a future unknown version of the model. We propose learning sideinformation, an auxiliary feature for each sample which facilitates future updates of the model. To develop a powerful and flexible framework for model compatibility, we combine side-information with a forward transformation from old to new embeddings. Training of the new model is not modified, hence, its accuracy is not degraded. We demonstrate significant retrieval accuracy improvement compared to BCT for various datasets: ImageNet-1k (+18.1%), Places-365 (+5.4%), and VGG-Face2 (+8.3%). FCT obtains model compatibility when the new and old models are trained across different datasets, losses, and architectures.
https://openaccess.thecvf.com/content/CVPR2022/html/Ramanujan_Forward_Compatible_Training_for_Large-Scale_Embedding_Retrieval_Systems_CVPR_2022_paper.html

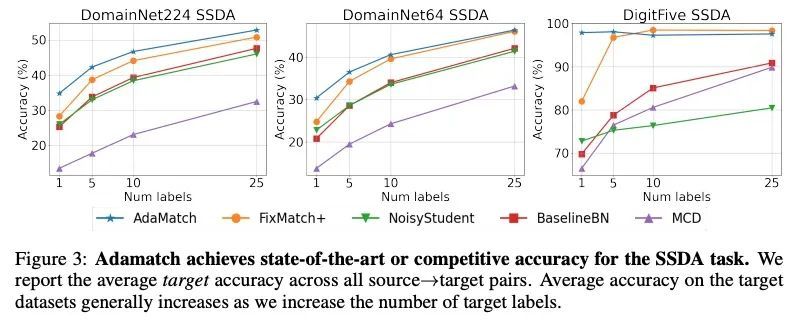
2、[LG] AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation
D Berthelot, R Roelofs, K Sohn, N Carlini, A Kurakin
[Google Research]
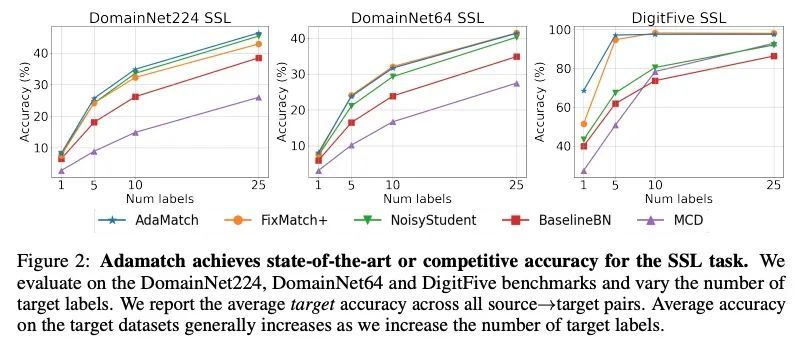
AdaMatch: 半监督学习和域自适应统一方法。本文将半监督学习扩展到域自适应问题上,以学习在一个数据分布上训练在另一个数据分布上测试的明显更高精度的模型。以通用性为目标,本文提出AdaMatch,一种用于无监督域自适应(UDA)、半监督学习(SSL)和半监督域自适应(SSDA)的统一解决方案。在一项广泛的实验研究中,将其行为与SSL、SSDA和UDA的各自最先进的技术进行了比较,发现无论数据集或任务如何,AdaMatch在使用相同超参数的情况下,都与最先进的技术相匹配或大大超过。例如,在DomainNet的UDA任务中,AdaMatch的精度几乎是之前最先进的两倍,当AdaMatch完全从头开始训练时,甚至超过了之前最先进的预训练的精度6.4%。此外,通过为AdaMatch提供来自目标域(即SSDA设置)的每个类别的一个标注的样本,目标精度额外提高了6.1%,如果有5个标注样本,则提高13.6%。
We extend semi-supervised learning to the problem of domain adaptation to learn significantly higher-accuracy models that train on one data distribution and test on a different one. With the goal of generality, we introduce AdaMatch, a unified solution for unsupervised domain adaptation (UDA), semi-supervised learning (SSL), and semi-supervised domain adaptation (SSDA). In an extensive experimental study, we compare its behavior with respective state-of-the-art techniques from SSL, SSDA, and UDA and find that AdaMatch either matches or significantly exceeds the state-of-the-art in each case using the same hyper-parameters regardless of the dataset or task. For example, AdaMatch nearly doubles the accuracy compared to that of the prior state-of-the-art on the UDA task for DomainNet and even exceeds the accuracy of the prior state-of-the-art obtained with pre-training by 6.4% when AdaMatch is trained completely from scratch. Furthermore, by providing AdaMatch with just one labeled example per class from the target domain (i.e., the SSDA setting), we increase the target accuracy by an additional 6.1%, and with 5 labeled examples, by 13.6%.
https://arxiv.org/abs/2106.04732


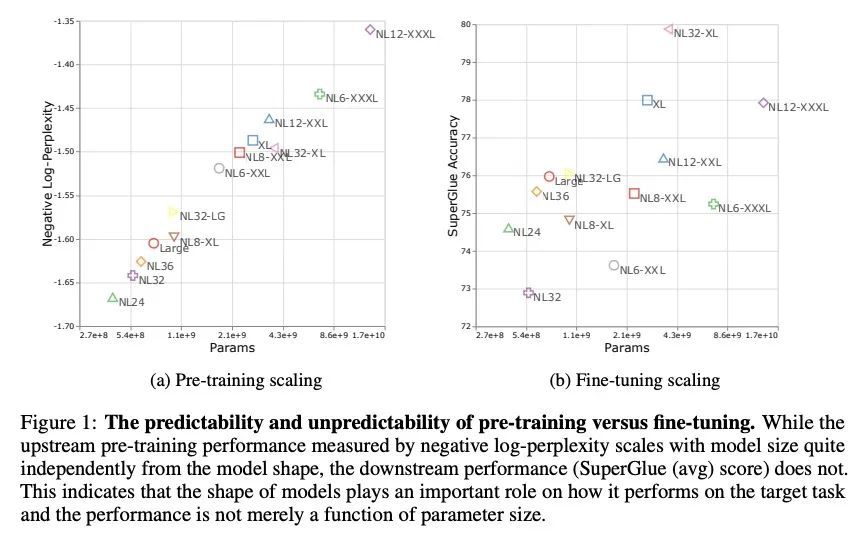
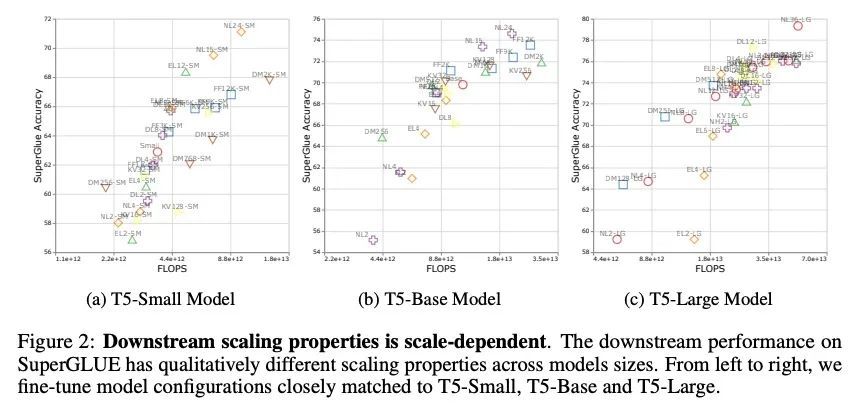
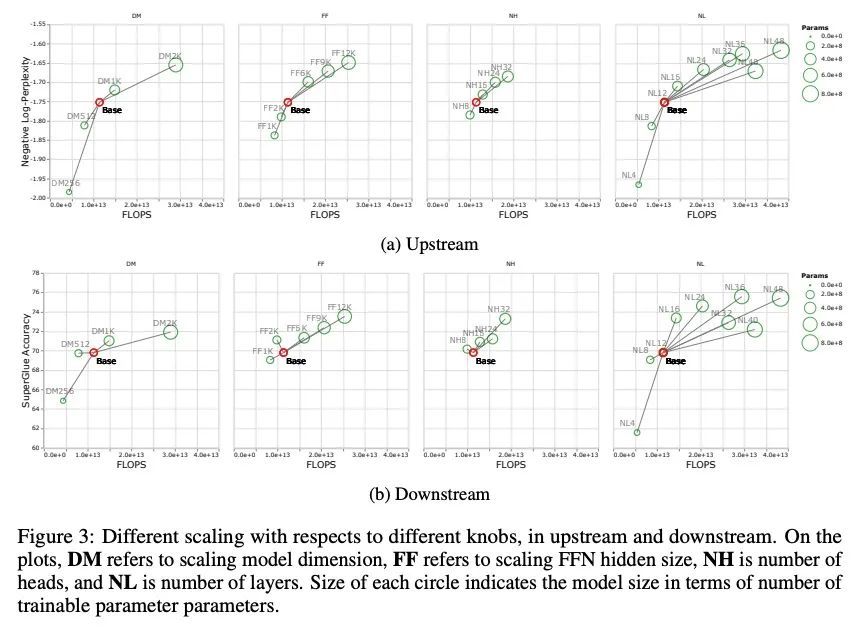
3、[CL] Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
Y Tay, M Dehghani, J Rao, W Fedus, S Abnar, H W Chung, S Narang, D Yogatama, A Vaswani, D Metzler
[Google Research & DeepMind]
高效缩放:从Transformer预训练和微调中得到的启示。关于Transformer架构的缩放行为,仍有许多开放性问题。这些缩放的决定和发现可能是至关重要的,因为进行训练往往伴随着相关的计算成本,这对财务和/或环境都有影响。本文的目的是挖掘从Transformer的预训练和微调中得到的扩展见解。虽然Kaplan等人对Transformer语言模型的扩展行为进行了全面的研究,但其范围只涉及上游(预训练)的损失。因此,在预训练-微调范式的背景下,这组研究结果是否能迁移到下游任务上,目前还不清楚。本文主要发现如下:(1) 除了模型大小之外,模型形状对下游微调也很重要,(2) 缩放协议在不同的计算区域有不同的操作,(3) 广泛采用的T5-base和T5-large大小是帕累托低效的。本文提出改进的缩放协议,与广泛采用的T5-base模型相比,重新设计的模型实现了类似的下游微调质量,同时参数减少50%,训练速度提高40%。
There remain many open questions pertaining to the scaling behaviour of Transformer architectures. These scaling decisions and findings can be critical, as training runs often come with an associated computational cost which have both financial and/or environmental impact. The goal of this paper is to present scaling insights from pretraining and finetuning Transformers. While Kaplan et al. (2020) presents a comprehensive study of the scaling behaviour of Transformer language models, the scope is only on the upstream (pretraining) loss. Therefore, it is still unclear if these set of findings transfer to downstream task within the context of the pretrain-finetune paradigm. The key findings of this paper are as follows: (1) we show that aside from only the model size, model shape matters for downstream fine-tuning, (2) scaling protocols operate differently at different compute regions, (3) widely adopted T5-base and T5-large sizes are Pareto-inefficient. To this end, we present improved scaling protocols whereby our redesigned models achieve similar downstream fine-tuning quality while having 50% fewer parameters and training 40% faster compared to the widely adopted T5-base model. We publicly release over 100 pretrained checkpoints of different T5 configurations to facilitate future research and analysis.
https://arxiv.org/abs/2109.10686
4、[LG] Visual Representation Learning Does Not Generalize Strongly Within the Same Domain
L Schott, J v Kügelgen, F Träuble...
[University of Tübingen & Max Planck Institute for Intelligent Systems & Amazon Web Services]
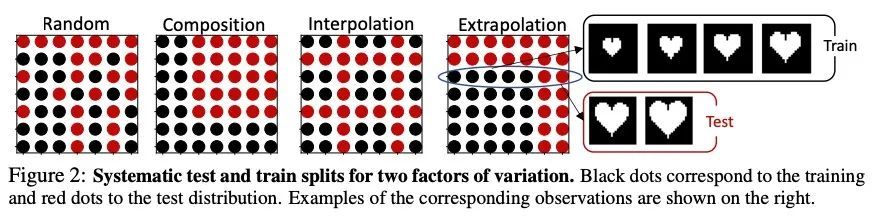
视觉表示学习在同域不会显著泛化。机器学习中泛化的一个重要组成部分是发现潜在的变异因素,以及每个因素在世界中的作用机制。本文测试了17种无监督、弱监督和全监督的表示学习方法是否正确推断了来自受控环境的简单数据集(dSprites、Shapes3D、MPI3D)和本文提出的CelebGlow数据集中的变化生成因素。与之前在测试期间引入新的变化因素(如模糊或其他(非)结构性噪声)的鲁棒性工作相比,这里只对训练数据集的现有变化因素(如训练期间的小型和中型目标及测试期间的大型目标)进行重组、插值或推断。学习了正确机制的模型应该能够泛化到该基准。总共训练和测试了2000多个模型,观察到无论监督信号和架构偏差如何,所有模型都在努力学习基本机制。此外,当从人工数据集向更现实的真实世界数据集移动时,所有测试模型的泛化能力都明显下降。尽管它们无法识别正确的机制,但这些模型是相当模块化的,因为它们推断其他分布内因素的能力仍然相当稳定,只要有一个因素是分布外的。这些结果指出了一个重要的但未被充分研究的问题,即观察机制模型的学习,以促进泛化。
An important component for generalization in machine learning is to uncover underlying latent factors of variation as well as the mechanism through which each factor acts in the world. In this paper, we test whether 17 unsupervised, weakly supervised, and fully supervised representation learning approaches correctly infer the generative factors of variation in simple datasets (dSprites, Shapes3D, MPI3D) from controlled environments, and on our contributed CelebGlow dataset. In contrast to prior robustness work that introduces novel factors of variation during test time, such as blur or other (un)structured noise, we here recompose, interpolate, or extrapolate only existing factors of variation from the training data set (e.g., small and medium-sized objects during training and large objects during testing). Models that learn the correct mechanism should be able to generalize to this benchmark. In total, we train and test 2000+ models and observe that all of them struggle to learn the underlying mechanism regardless of supervision signal and architectural bias. Moreover, the generalization capabilities of all tested models drop significantly as we move from artificial datasets towards more realistic real-world datasets. Despite their inability to identify the correct mechanism, the models are quite modular as their ability to infer other in-distribution factors remains fairly stable, providing only a single factor is out-of-distribution. These results point to an important yet understudied problem of learning mechanistic models of observations that can facilitate generalization.
https://arxiv.org/abs/2107.08221

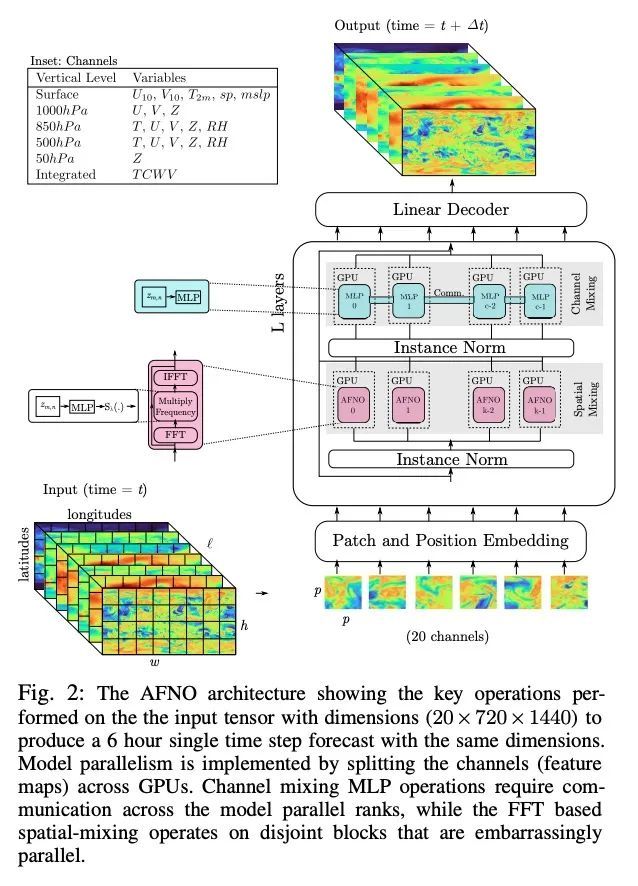
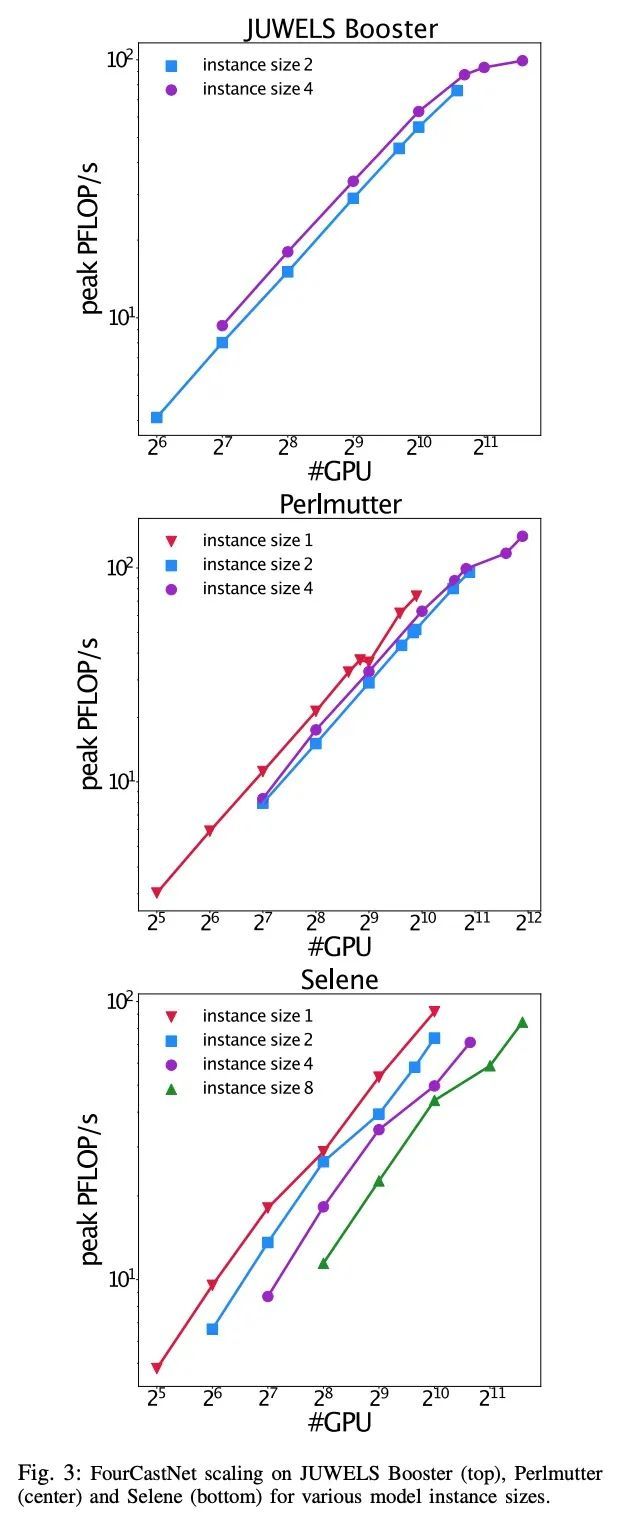
5、[LG] FourCastNet: Accelerating Global High-Resolution Weather Forecasting using Adaptive Fourier Neural Operators
T Kurth, S Subramanian, P Harrington, J Pathak...
[NVIDIA & NERSC]
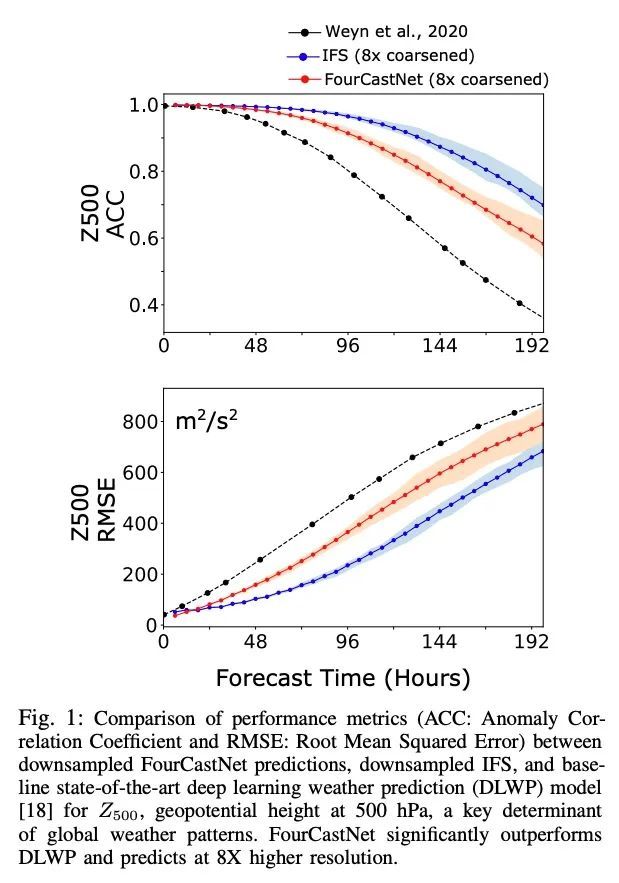
FourCastNet: 基于自适应傅里叶神经算子加速全球高分辨率天气预报。被气候变化放大的极端天气在全球范围内造成了越来越大的破坏性影响。目前使用的基于物理学的数值天气预报(NWP)由于高计算成本和严格的时间-解决方案限制而限制了准确性。一个数据驱动的深度学习地球系统模拟器FourCastNet可以预测全球天气,并产生比NWP快五个数量级的中程预报,同时接近最先进的精度。FourCastNet在三个超级计算系统上进行了优化和有效扩展。Selene、Perlmutter和JUWELS Booster三套超级计算机系统的GPU数量高达3,808个,在混合精度下达到140.8 petaFLOPS(该规模下峰值的11.9%)。在3,072个GPU上的JUWELS Booster测得的FourCastNet的训练时间为67.4分钟,相对于最先进的NWP,在推理方面的训练时间快了80,000倍。FourCastNet可以提前一周进行准确的瞬时天气预测,能更好地捕捉极端天气的巨大集合,并支持更高的全球预测分辨率。
Extreme weather amplified by climate change is causing increasingly devastating impacts across the globe. The current use of physics-based numerical weather prediction (NWP) limits accuracy due to high computational cost and strict timeto-solution limits. We report that a data-driven deep learning Earth system emulator, FourCastNet, can predict global weather and generate medium-range forecasts five orders-of-magnitude faster than NWP while approaching state-of-the-art accuracy. FourCastNet is optimized and scales efficiently on three supercomputing systems: Selene, Perlmutter, and JUWELS Booster up to 3,808 NVIDIA A100 GPUs, attaining 140.8 petaFLOPS in mixed precision (11.9% of peak at that scale). The time-to-solution for training FourCastNet measured on JUWELS Booster on 3,072 GPUs is 67.4 minutes, resulting in an 80,000 times faster time-to-solution relative to state-of-the-art NWP, in inference. FourCastNet produces accurate instantaneous weather predictions for a week in advance, enables enormous ensembles that better capture weather extremes, and supports higher global forecast resolutions.
https://arxiv.org/abs/2208.05419

另外几篇值得关注的论文:
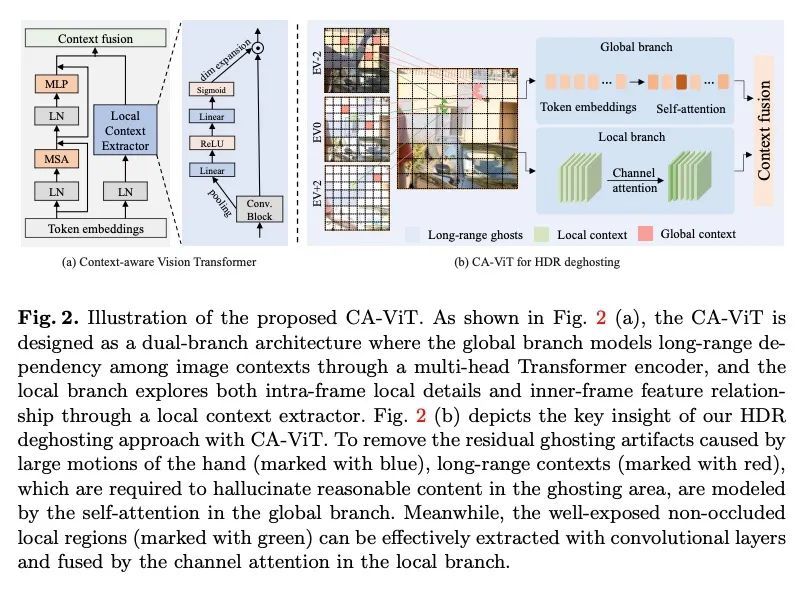
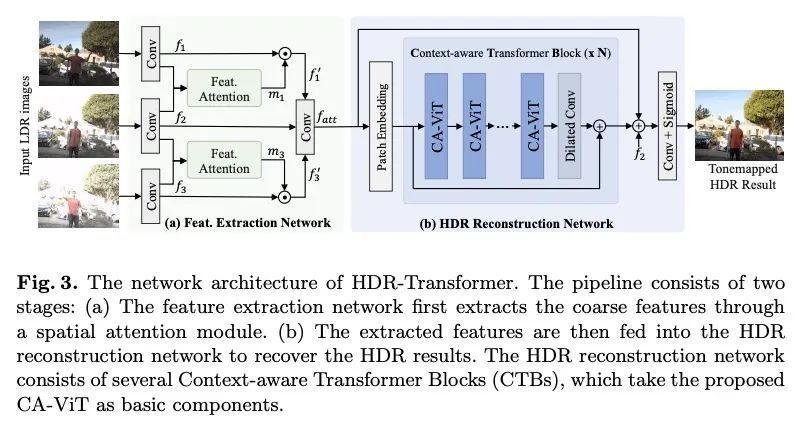
[CV] Ghost-free High Dynamic Range Imaging with Context-aware Transformer
基于上下文感知Transformer的无重影高动态范围成像Z Liu, Y Wang, B Zeng, S Liu
[Megvii Technology & Noah’s Ark Lab, Huawei Technologies & University of Electronic Science and Technology of China]
https://arxiv.org/abs/2208.05114


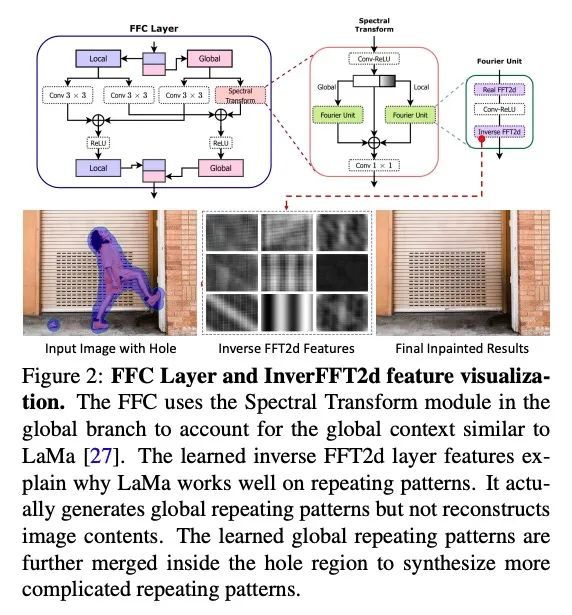
[CV] Keys to Better Image Inpainting: Structure and Texture Go Hand in Hand
图像补全改善的关键:结构纹理两手抓
J Jain, Y Zhou, N Yu, H Shi
[University of Oregon & Adobe & Salesforce Research]
https://arxiv.org/abs/2208.03382


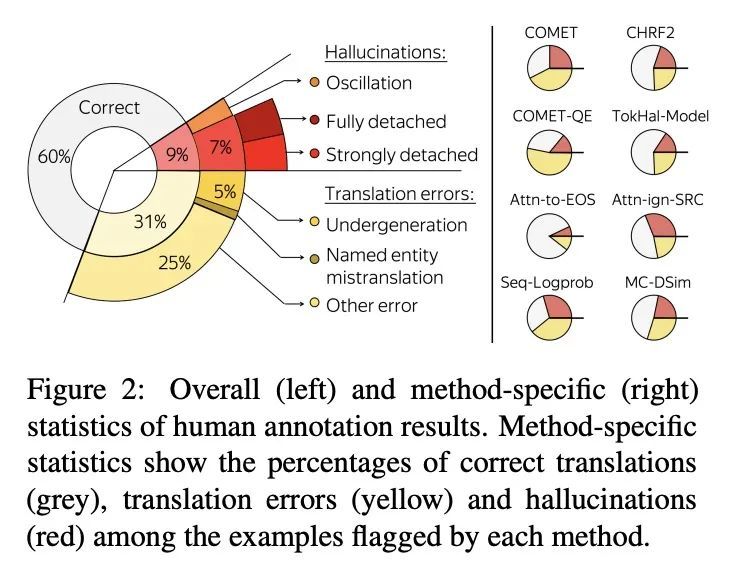
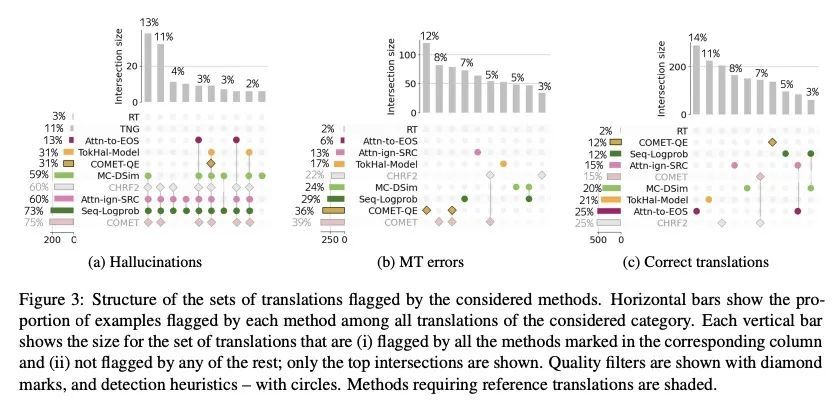
[CL] Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation
大海捞针:神经机器翻译错觉的综合研究
N M. Guerreiro, E Voita, A F.T. Martins
[Instituto de Telecomunicações & University of Edinburgh]
https://arxiv.org/abs/2208.05309


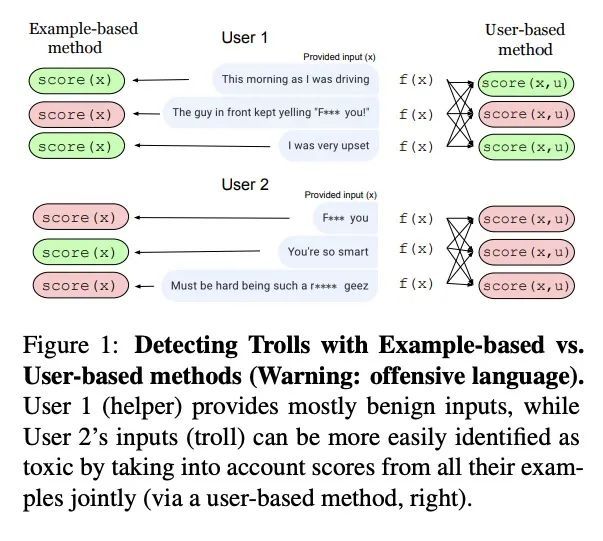
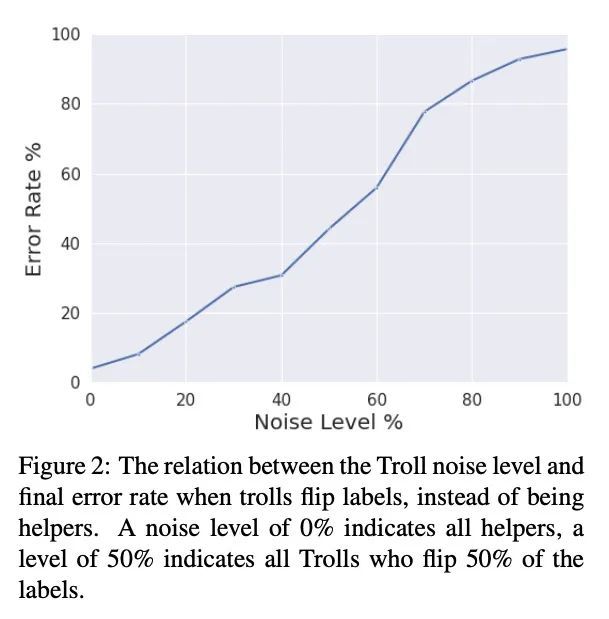
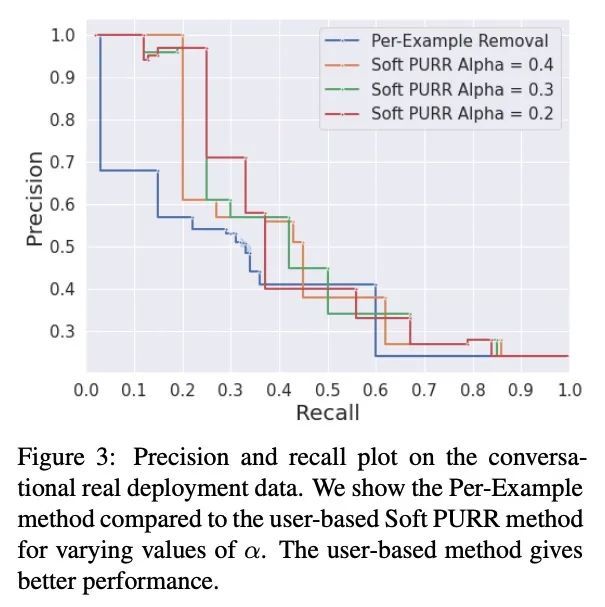
[CL] Learning from data in the mixed adversarial non-adversarial case: Finding the helpers and ignoring the trolls
混合对抗性非对抗案例中的数据学习:趋善避恶
D Ju, J Xu, Y Boureau, J Weston
[Meta AI]
https://arxiv.org/abs/2208.03295

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢