

论文地址:https://arxiv.org/abs/2207.05557
代码地址:https://github.com/hunto/LightViT
导读
一些轻量级的ViTs工作为增强架构性能,常将卷积操作集成于Transformer模块中。本文为探讨卷积对轻量级ViTs的必要性,设计了一种无卷积的轻量级ViTs架构LightViT,提出一种全局而高效的信息聚合方案。除了在局部窗口内执行自注意计算之外,还在self-attention中引入额外的可学习标记来捕捉全局依赖性,在FFN中引入双维注意机制。LightViT-T在ImageNet上仅用0.7G FLOPs就实现了78.7%的准确率,比PVTv2-B0高出8.2%。代码已开源。
贡献
ViTs模型DeiT-Ti和PVTv2-B0在ImageNet上可以达到72.2%和70.5%的准确率,而经典CNN模型RegNetY-800M在类似的FLOPs下达到了76.3%的准确率。这一现象表明某些轻量级的ViTs性能反而不如同级别CNNs。
作者等人将这一现象的原因归咎于CNNs固有的归纳偏置(inductive bias),同时现有很多工作试图将卷积集成于ViTs中来提高模型性能。然而不管是宏观上直接将卷积与self-attention集成/混合,还是微观上将卷积计算纳入self-attention计算之中,都说明了卷积对于轻量级ViTs的性能提升是至关重要的存在。
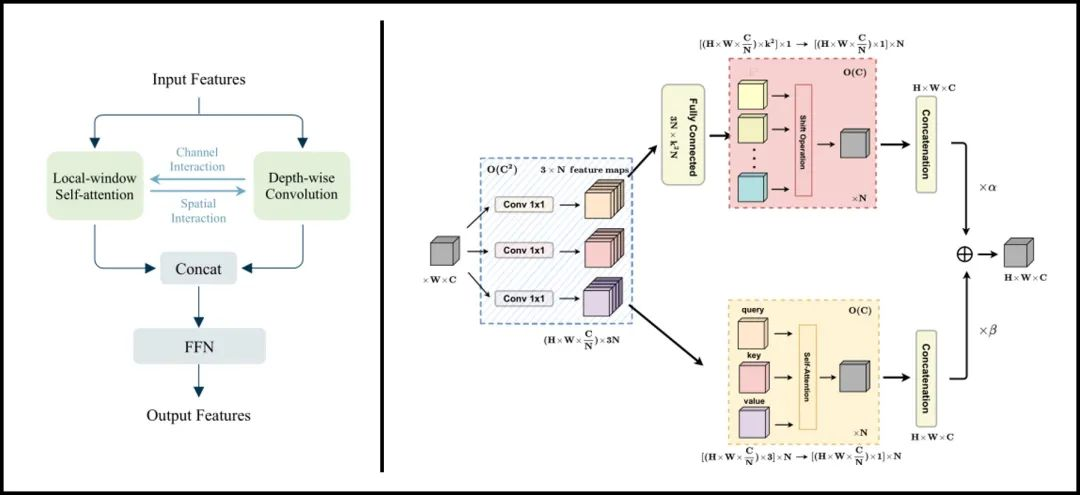
图1:宏观、微观举例。左图为MixFormer,右图为ACmix。
作者等人认为,在ViTs中混合卷积操作,是一种信息聚合的方式,卷积通过共享内核建立了所作用token之间的明确联系。基于这一点,作者等人提出“如果这种明确的聚合能以更均匀的方式发挥作用,那么它们对于轻量级的ViTs来说实际上是不必要的”。
至此LightViT油然而生,除了继续在局部窗口内执行自注意计算之外,对架构的主要修改针对self-attention和FFN部分。在self-attention中引入可学习的全局标记来对全局依赖关系进行建模,并被广播到局部token中,因此每一个token除了拥有局部窗口注意计算带来的局部依赖关系外,还获得了全局依赖关系。在FFN中,作者等人注意到轻量级模型的通道尺寸较小,因此设计一种双维注意模块来提升模型性能。其性能对比简图如下所示:
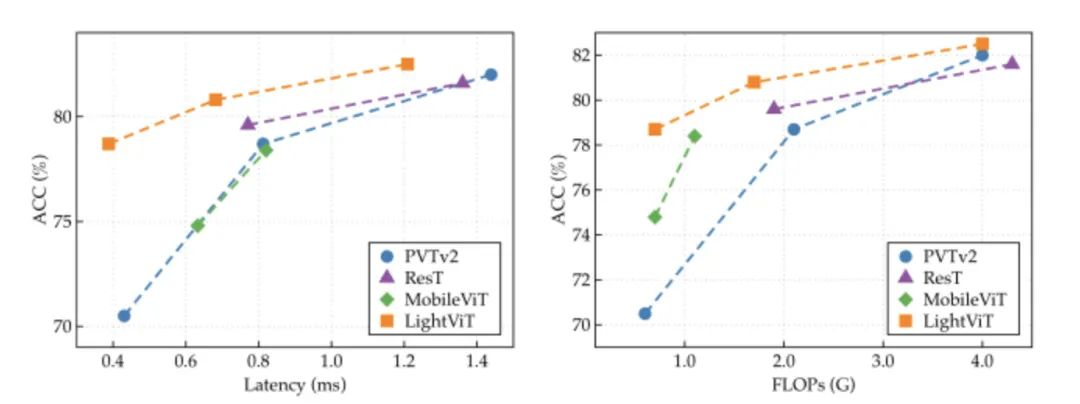
图2:LightViT和其他高效ViT在ImageNet上的比较。
方法
下面将对LightViT的两处架构细节进行详细阐述。
self-attention中的局部-全局广播机制
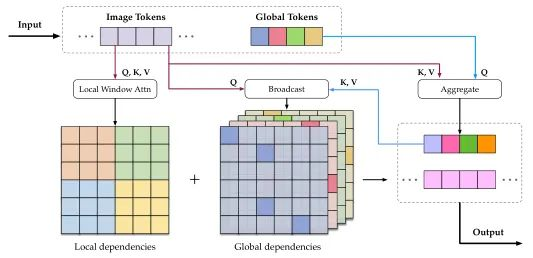
图3:自注意计算中的局部-全局广播。
如图3中Local Window Attn部分,输入特征X∈RH*W*C,与Swin中类似,将X划分为不重叠的小窗S*S,其形状变为(H/S*H/S,S*S,C),之后在每个小窗中执行self-attention,其计算过程可用如下公式表达:
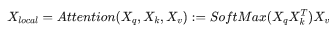
此时Xlocal通过局部窗口注意建立起局部依赖,然而局部窗口注意的明显不足是感受野以及长距离依赖的缺失。因此本文提出一种成本较低的弥补方式:先将全局依赖关系聚集到一个小的特征空间,然后广播于局部特征。其具体过程如下:
首先在划分小窗口的同时计算一个可学习的全局标记G∈RT*C(T远小于H×W或S×S),在执行上述局部窗口自注意计算的同时,利用G、k、v来收集全局信息,如图3最右侧Aggregate部分,其计算可用如下公式表示:
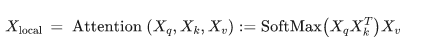
其次将通过自注意计算的方式广播于局部特征,以弥补其全局依赖信息的不足,计算过程可用如下公式表达:
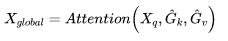
最后如图3所示,将Xlocal与Xglobal执行逐元素相加以获得最终的图像标记,一份可视化特征图如下所示:

图4:自注意计算中的局部-全局广播可视化结果。
在图中可以很明显的看到,可学习标记G将全局信息聚合到一个小的特征空间,保留了关键信息(狗的鼻子、眼睛等),其次广播机制将全局信息传递给相关像素,使其特征得到关键增强。
FFN中的双维注意机制
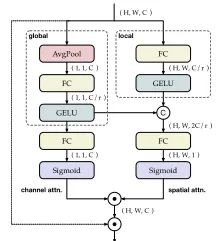
图5:FFN中的双维注意机制。
在轻量级ViTs模型的FFN部分中有两个常见的不足:一个是为了尽可能的减少计算成本,通道维度被大幅限制,导致模型性能不足;另一个便是一般的FFN结构忽视了对特征空间层次上的依赖性建模。
或许空间特征聚合可以通过token间的权重共享隐式进行,但对于轻型ViTs来说(通道受限),仍存在一定不足。
如图5,左边为通道注意分支,用于捕捉全局信息。类似于SE的结构,先进行平均池化,再经过两个FC层,其中r代表缩减率,即将通道维度先减小至C/r,再还原为C,这样做一方面可以在小通道维度获得较轻的计算负担,另一方面便是增加了跨通道的信息交互。右侧的分支为空间注意分支,用于捕捉局部信息,在利用FC将通道数调整至1之前,作者等人将左侧分支的全局信息输出与右侧分支的局部信息输出拼接在一起,由此全局信息可以作用于每一个token(局部信息),进一步提高了模型性能。最后将空间、通道注意想融合后作用于FFN模块输入特征。
LightViT的整体架构
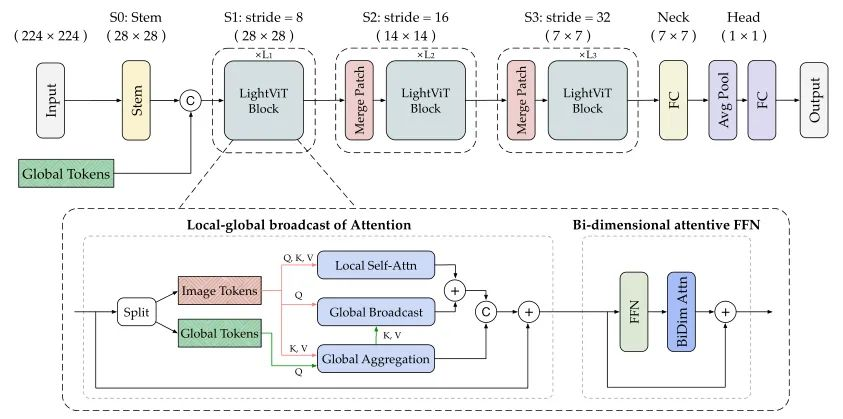
图6:LightViT的架构示意图。
有读者可能会疑惑为什么LightViT仅由“三阶段”的堆叠块构成,下采样步长分别为{8,16,32},少了一个4。其实作者等人对一些分层的ViTs进行推理速度/FLOPs的测量(如下图7),结果发现早期阶段的效率低于后期阶段。作者将这一现象的原因归咎于在早期阶段token更多,因此效率低下。在删除stride = 4的早期阶段后,在ImageNet上Top-1提升0.8%,在COCO检测中mAP提升0.3。
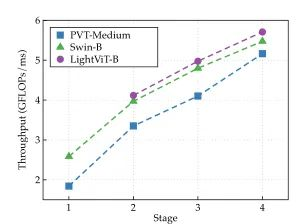
图7:分层ViTs的各阶段效率对比。
实验
下表首先给出了模型在ImageNet数据集上训练时使用的配置。
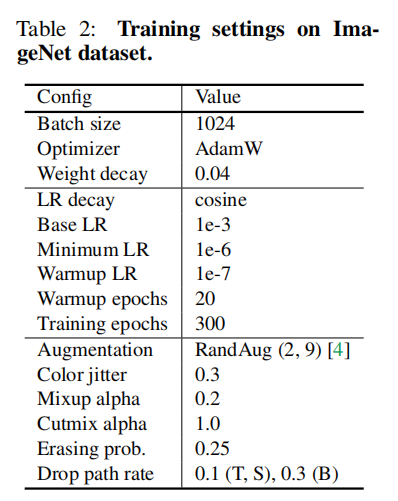
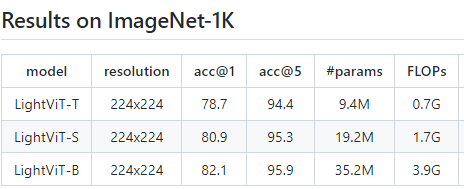
表3总结了LightViT在ImageNet验证集上的表现。在基本的224×224分辨率下,LightViT优于最近的高效ViTs,特别是在轻量级(小于2G流量)上有很大的改进。例如,LightViT-T在0.7GFLOPs下获得了创纪录的78.7%的准确率,显著优于那些具有注意卷积混合块的ViT变体

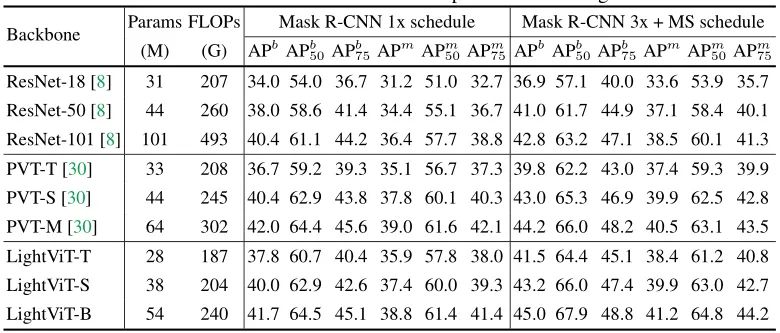
作者在下表中报告了MS-COCO数据集的结果。LightViT的表现与最近的4级ViTs的流量相当。具体来说,LightViT-S使用1×计划实现了40.0%的APb和37.4%的APm,优于使用∼200GFLOPs的混合方法PVT-T。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢