
【标题】Distributionally Robust Model-Based Offline Reinforcement Learning with Near-Optimal Sample Complexity
【作者团队】Laixi Shi, Yuejie Chi
【发表日期】2022.8.11
【论文链接】https://arxiv.org/pdf/2208.05767.pdf
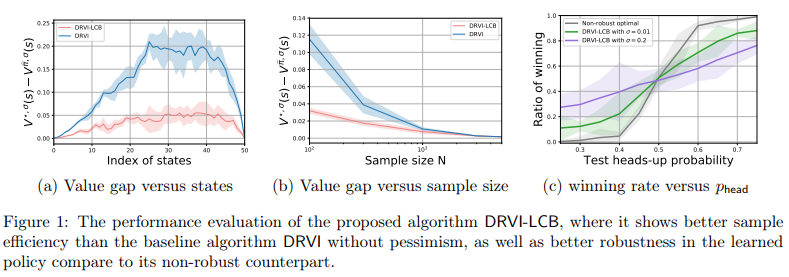
【推荐理由】本文关注离线强化学习 (RL) 中模型鲁棒性和样本效率的核心问题,其旨在学习在不主动探索的情况下从历史数据中执行决策。由于环境的不确定性和易变性,学习一个稳健的策略至关重要。通过考虑离线 RL 的分布式鲁棒公式,重点关注具有由 Kullback-Leibler 散度指定的不确定性集的表格非平稳有限范围鲁棒马尔可夫决策过程。为应对样本稀缺,提出基于模型的算法将分布鲁棒的值迭代与面对不确定性的悲观原则相结合,通过精心设计的数据驱动的惩罚项来惩罚鲁棒的值估计。在不需要完全覆盖状态-动作空间的情况下测量分布变化的历史数据集的温和和量身定制的假设下,建立了所提出算法的有限样本复杂度,并表明它几乎是不可改进的将信息论下界匹配到水平长度的多项式因子。这提供了首个可证明接近最优的鲁棒离线 RL 算法,该算法在模型不确定性和部分覆盖下进行学习。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢