
【标题】Robust Reinforcement Learning using Offline Data
【作者团队】Kishan Panaganti, Zaiyan Xu, Dileep Kalathil, Mohammad Ghavamzadeh
【发表日期】2022.8.10
【论文链接】https://arxiv.org/pdf/2208.05129.pdf
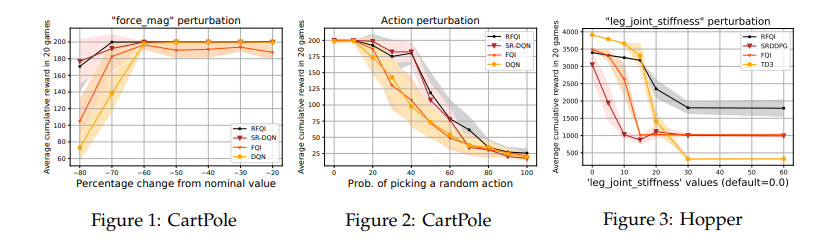
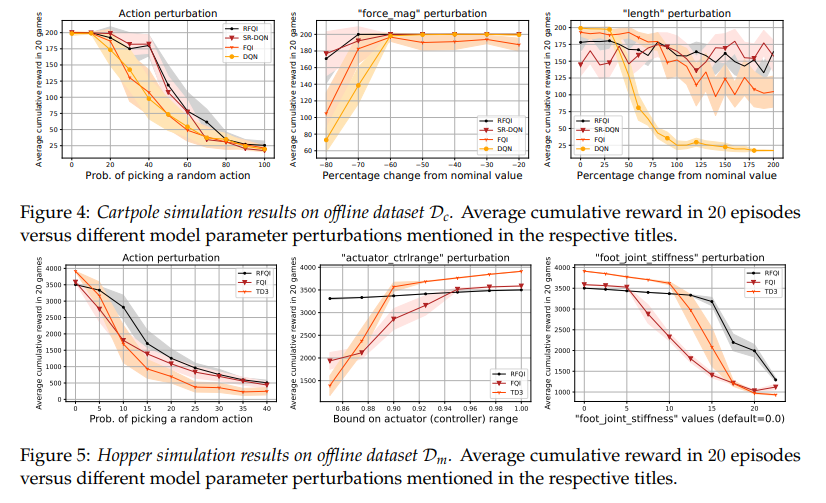
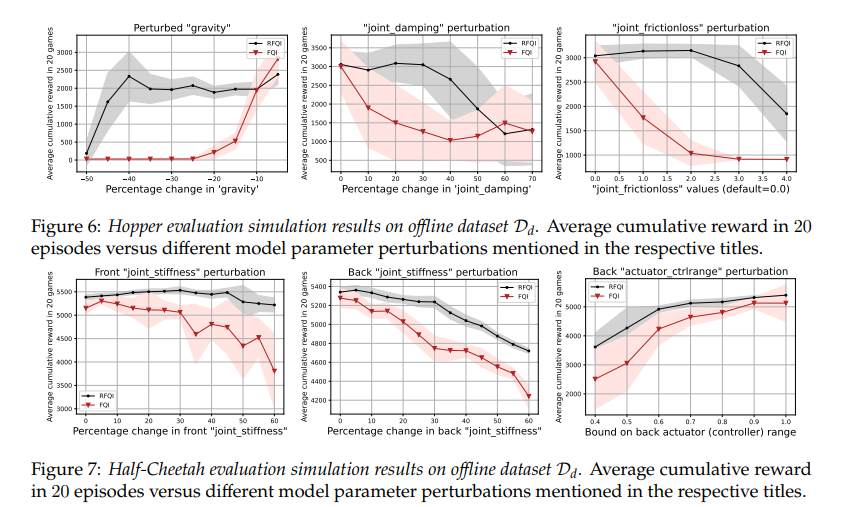
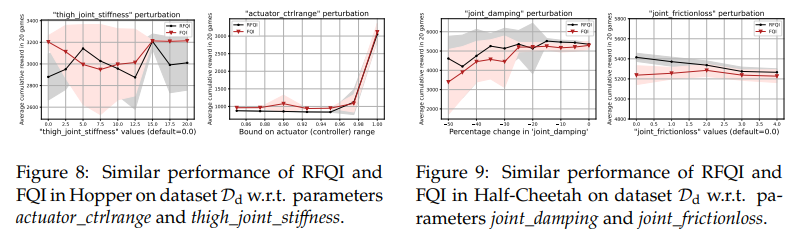
【推荐理由】鲁棒强化学习(RL)的目标是学习对模型参数的不确定性具有鲁棒性的策略。由于模拟器建模误差、真实系统动态随时间的变化以及对抗性干扰,参数不确定性通常出现在许多真实RL应用中。鲁棒RL通常表示为最大-最小问题,其目标是学习针对不确定性集中最差可能模型的最大值策略。本文提出了鲁棒拟合Q迭代(RFQI)的鲁棒RL算法,该算法仅使用离线数据集来学习最优鲁棒策略。由于鲁棒Bellman算子中存在的所有模型的最小化,因此具有离线数据的鲁棒RL比其非鲁棒对手具有更大的挑战性。这给离线数据收集、模型优化和无偏估计带来了挑战。为此,其提出了一种系统的方法来克服这些挑战,从而产生了RFQI算法。研究证明了RFQI在标准假设下学习一个接近最优的鲁棒策略,并在标准基准问题上证明了其优越的性能。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢