
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:视觉模型强化学习基于赋权的信息优先化、面向纯相机3D检测的水平容错3D平均精度、基于层次条件变分自编码器的声学异常检测、面向不确定性估计的集成方法、基于谱扩散的多乐器音乐合成、实际场景单目标概率相对旋转预测、更低保真度模拟实现导航中更高的Sim2Real迁移、深度图块视觉里程计、面向规范化流的更好的反向和正向KL散度估计器
1、[RO] INFOrmation Prioritization through EmPOWERment in Visual Model-Based RL
H Bharadhwaj, M Babaeizadeh, D Erhan, S Levine
[CMU & Google Research]
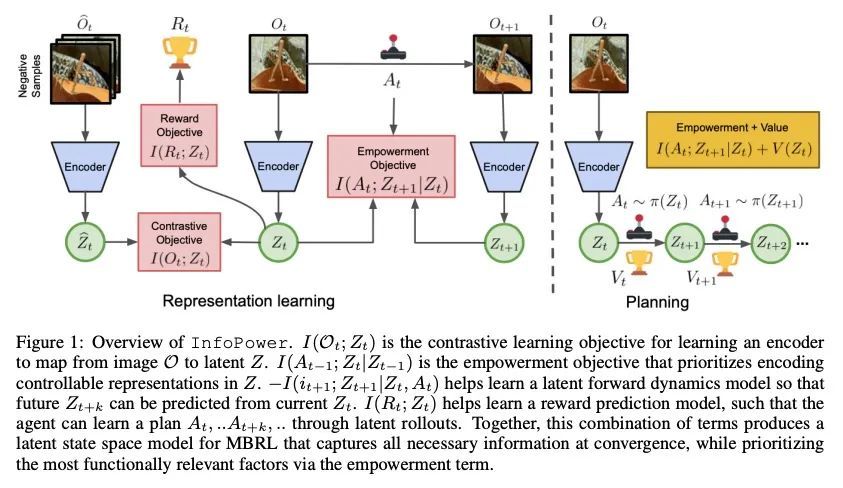
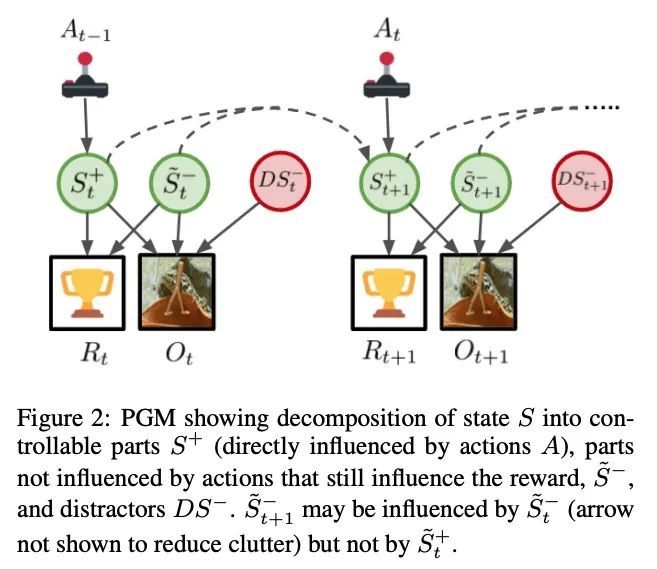
视觉模型强化学习基于赋权的信息优先化。为处理复杂的视觉观察而设计的基于模型的强化学习(RL)算法通常会学习某种潜在的状态表示,无论是显式的还是隐式的。这类标准方法不区分状态的功能相关方面和不相关的干扰因素,而是旨在平等地表示所有可用的信息。本文为基于模型的强化学习提出一修正目标,结合互信息最大化,能以明确优先考虑功能相关因素的方式学习基于视觉模型的强化学习的表示和动态,而无需重建。设计背后的关键原则是将一个受变分赋权启发的思想整合到基于互信息的状态空间模型中,优先考虑与行动相关的信息,从而确保功能相关的因素被首先捕获。此外,同一赋权项还能在强化学习过程中促进更快的探索,特别是对于稀疏奖励任务,奖励信号不足以在学习的早期阶段推动探索。在一套具有自然视频背景的基于视觉的机器人控制任务上对该方法进行了评估,结果表明,所提出的优先信息目标以更高的样本效率和偶发性回报胜过了最先进的基于模型的强化学习方法。
Model-based reinforcement learning (RL) algorithms designed for handling complex visual observations typically learn some sort of latent state representation, either explicitly or implicitly. Standard methods of this sort do not distinguish between functionally relevant aspects of the state and irrelevant distractors, instead aiming to represent all available information equally. We propose a modified objective for model-based RL that, in combination with mutual information maximization, allows us to learn representations and dynamics for visual model-based RL without reconstruction in a way that explicitly prioritizes functionally relevant factors. The key principle behind our design is to integrate a term inspired by variational empowerment into a state-space model based on mutual information. This term prioritizes information that is correlated with action, thus ensuring that functionally relevant factors are captured first. Furthermore, the same empowerment term also promotes faster exploration during the RL process, especially for sparse-reward tasks where the reward signal is insufficient to drive exploration in the early stages of learning. We evaluate the approach on a suite of vision-based robot control tasks with natural video backgrounds, and show that the proposed prioritized information objective outperforms state-of-the-art model based RL approaches with higher sample efficiency and episodic returns. https://sites.google.com/view/information-empowerment
https://arxiv.org/abs/2204.08585


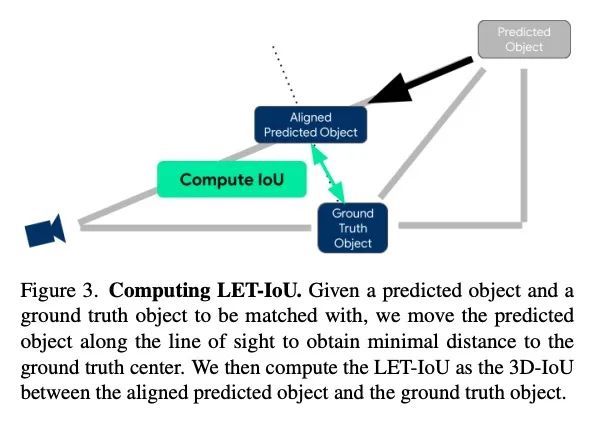
2、[CV] LET-3D-AP: Longitudinal Error Tolerant 3D Average Precision for Camera-Only 3D Detection
W Hung, H Kretzschmar, V Casser, J Hwang, D Anguelov
[Waymo LLC]
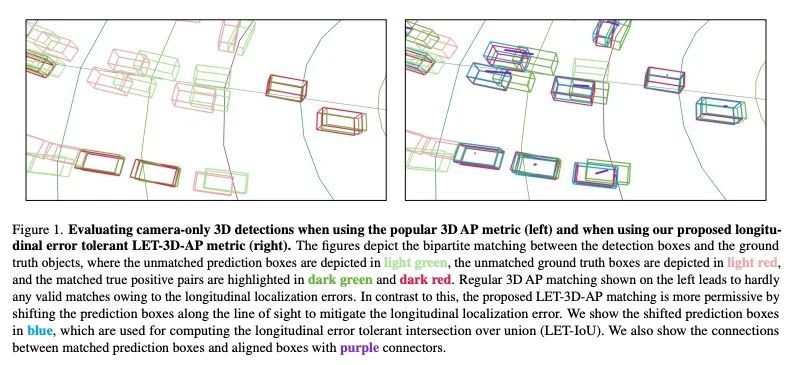
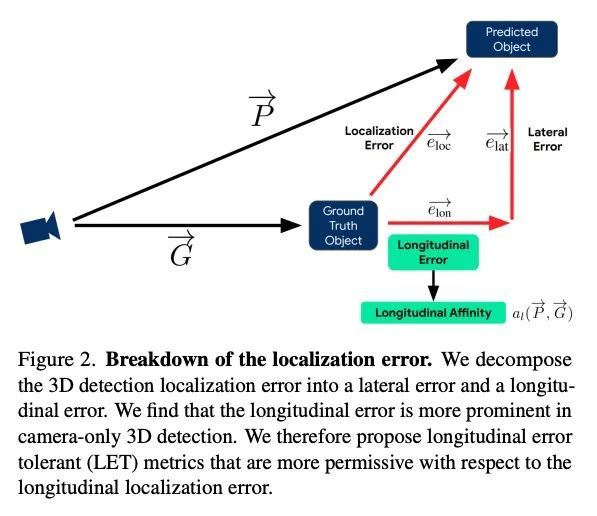
LET-3D-AP: 面向纯相机3D检测的水平容错3D平均精度。流行的目标检测指标3D平均精度(3D AP)依赖于预测边框和真实边框之间的交集。然而,基于相机的深度估计的精度有限,可能导致原本合理的预测受到这种水平定位错误的影响,被视为假阳性和假阴性。因此,本文提出流行的3D AP度量的变体,其目的是对深度估计错误更加宽容。新的水平容错度量,LET-3D-AP和LET-3D-APL,允许预测的边框的水平定位误差达到一定的容差。所提出的指标已用于Waymo开放数据集的3D纯相机检测挑战。相信新指标将通过提供更多信息的性能信号,促进纯相机3D检测领域的进步。
The popular object detection metric 3D Average Precision (3D AP) relies on the intersection over union between predicted bounding boxes and ground truth bounding boxes. However, depth estimation based on cameras has limited accuracy, which may cause otherwise reasonable predictions that suffer from such longitudinal localization errors to be treated as false positives and false negatives. We therefore propose variants of the popular 3D AP metric that are designed to be more permissive with respect to depth estimation errors. Specifically, our novel longitudinal error tolerant metrics, LET-3D-AP and LET-3D-APL, allow longitudinal localization errors of the predicted bounding boxes up to a given tolerance. The proposed metrics have been used in the Waymo Open Dataset 3D Camera-Only Detection Challenge. We believe that they will facilitate advances in the field of camera-only 3D detection by providing more informative performance signals.
https://arxiv.org/abs/2206.07705

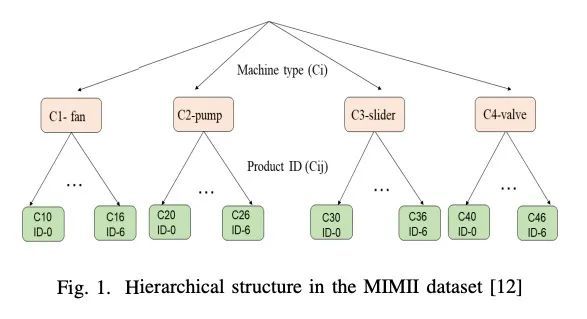
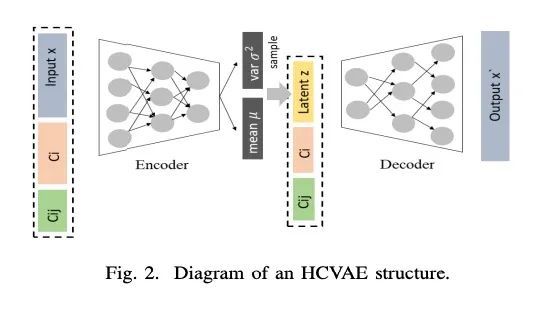
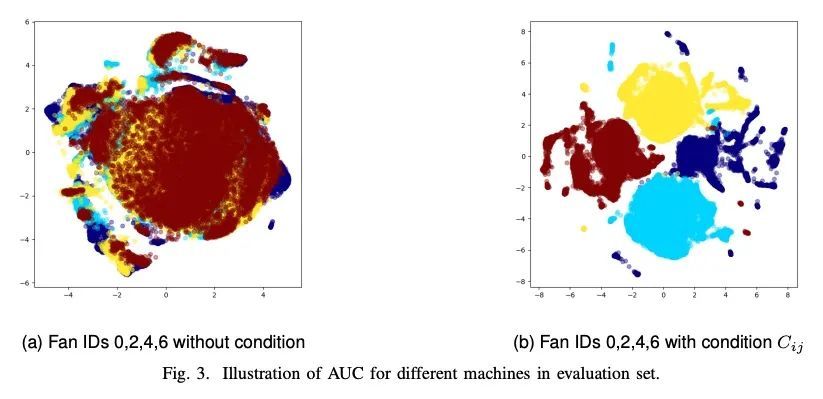
3、[LG] Hierarchical Conditional Variational Autoencoder Based Acoustic Anomaly Detection
H Purohit, T Endo, M Yamamoto, Y Kawaguchi
[Hitachi Ltd.]
基于层次条件变分自编码器的声学异常检测。本文旨在开发一种基于声学信号的无监督的异常检测方法,用于自动机器监测。现有的方法,如深度自编码器(DAE)、变分自编码器(VAE)、条件变分自编码器(CVAE)等,潜空间表示能力有限,异常检测性能并不高。必须为每一种不同的机器训练不同的模型,以准确执行异常检测任务。为解决该问题,本文提出一种新方法,即层次条件变分自编码器(HCVAE),利用关于工业设施的现有分类层次知识来完善潜空间的表示。这些知识也有助于模型提高异常检测性能。通过使用适当的条件,证明了单一HCVAE模型对不同类型机器的通用能力。此外,为了显示所提出方法的实用性,(i)在不同的领域评估了HCVAE模型;(ii)检查了部分层次知识的效果。实验结果表明,HCVAE方法验证了这两点,在异常检测任务上比基线系统的AUC分数指标高出了近15%。
This paper aims to develop an acoustic signalbased unsupervised anomaly detection method for automatic machine monitoring. Existing approaches such as deep autoencoder (DAE), variational autoencoder (VAE), conditional variational autoencoder (CVAE) etc. have limited representation capabilities in the latent space and, hence, poor anomaly detection performance. Different models have to be trained for each different kind of machines to accurately perform the anomaly detection task. To solve this issue, we propose a new method named as hierarchical conditional variational autoencoder (HCVAE). This method utilizes available taxonomic hierarchical knowledge about industrial facility to refine the latent space representation. This knowledge helps model to improve the anomaly detection performance as well. We demonstrated the generalization capability of a single HCVAE model for different types of machines by using appropriate conditions. Additionally, to show the practicability of the proposed approach, (i) we evaluated HCVAE model on different domain and (ii) we checked the effect of partial hierarchical knowledge. Our results show that HCVAE method validates both of these points, and it outperforms the baseline system on anomaly detection task by utmost 15 % on the AUC score metric.
https://arxiv.org/abs/2206.05460

4、[LG] Ensembles for Uncertainty Estimation: Benefits of Prior Functions and Bootstrapping
V Dwaracherla, Z Wen, I Osband, X Lu, S M Asghari, B V Roy
[DeepMind]
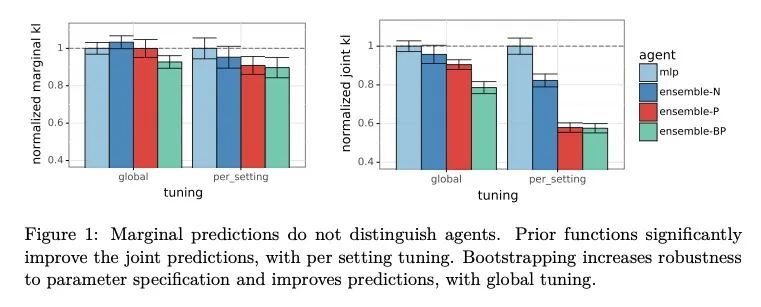
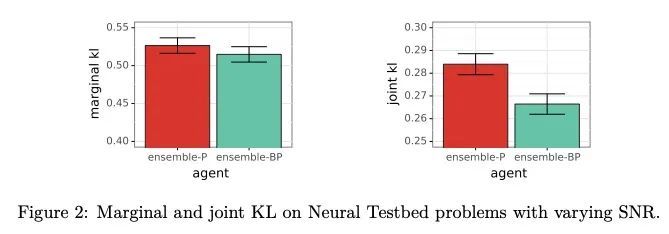
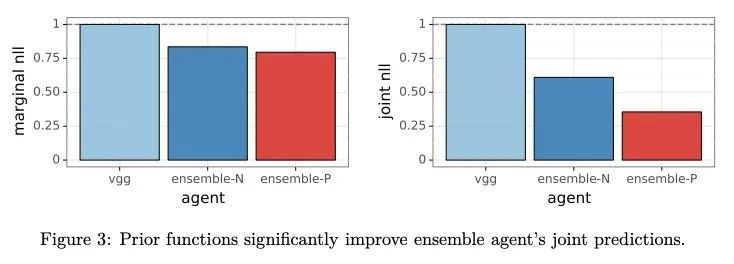
面向不确定性估计的集成方法:先验函数和Bootstrapping的收益。在机器学习中,智能体需要估计不确定性以有效地探索和自适应,并做出有效的决策。一个常见的不确定性估计方法是维护一个模型的集成。近年来,人们提出了几种训练集成的方法,而对于这些方法中各种成分的重要性,人们的看法也是相互矛盾的。本文旨在解决两个成分——先验函数和Bootstrapping——的收益,这两个成分已经受到了质疑。本文表明,先验函数可以极大地改善集成智能体对不同输入的联合预测,如果不同输入的信噪比不同,那么Bootstrapping可以带来额外的收益。所提出的主张在理论和实验结果中都得到了证明。
In machine learning, an agent needs to estimate uncertainty to efficiently explore and adapt and to make effective decisions. A common approach to uncertainty estimation maintains an ensemble of models. In recent years, several approaches have been proposed for training ensembles, and conflicting views prevail with regards to the importance of various ingredients of these approaches. In this paper, we aim to address the benefits of two ingredients – prior functions and bootstrapping – which have come into question. We show that prior functions can significantly improve an ensemble agent’s joint predictions across inputs and that bootstrapping affords additional benefits if the signal-to-noise ratio varies across inputs. Our claims are justified by both theoretical and experimental results.
https://arxiv.org/abs/2206.03633

5、[AS] Multi-instrument Music Synthesis with Spectrogram Diffusion
C Hawthorne, I Simon, A Roberts, N Zeghidour, J Gardner, E Manilow, J Engel
[Google Research]
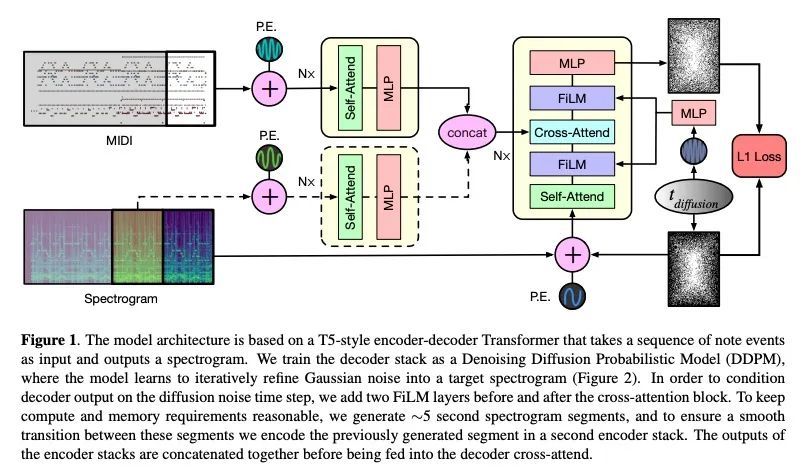
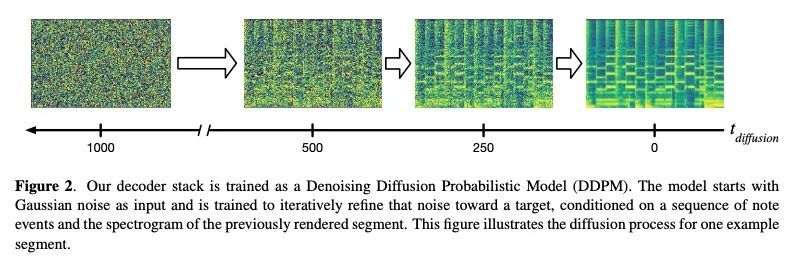
基于谱扩散的多乐器音乐合成。理想的音乐合成应该既是交互式的,且具有表现力,能为任意的乐器和音符组合实时生成高保真的音频。最近的神经合成器在特定领域的模型和原始波形模型之间进行了权衡,前者只提供对特定乐器的详细控制,后者可以对所有的音乐进行训练,但控制力最小,生成速度慢。本文专注于神经合成器的中间地带,可以从MIDI序列中实时生成具有任意乐器组合的音频,能用单一的模型对广泛的转录数据集进行训练,反过来又提供了对各种乐器的组成和配器的音符级控制。用一个简单的两阶段过程。用编-解码器转换MIDI到频谱图,然后用生成式对抗网络(GAN)频谱图逆变器将频谱图转换成音频。本文比较了将解码器训练成自回归模型和去噪扩散概率模型(DDPM),发现DDPM方法在质量上以及在音频重建和Fréchet距离指标上都更胜一筹。
An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on all of music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers notelevel control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
https://arxiv.org/abs/2206.05408

另外几篇值得关注的论文:
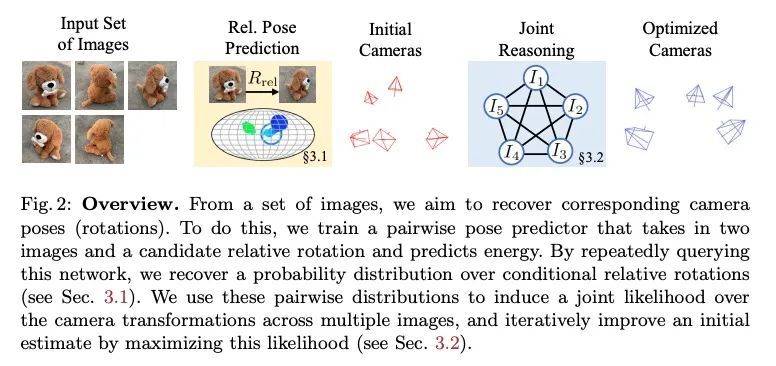
[CV] RelPose: Predicting Probabilistic Relative Rotation for Single Objects in the Wild
RelPose:实际场景单目标概率相对旋转预测
J Y. Zhang, D Ramanan, S Tulsiani
[CMU]
https://arxiv.org/abs/2208.05963



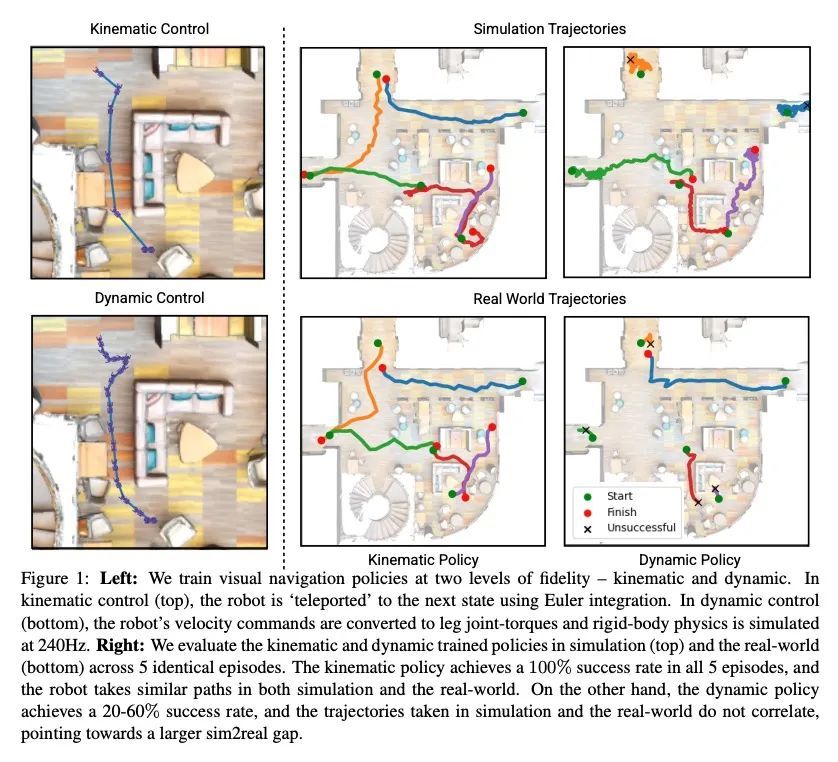
[RO] Rethinking Sim2Real: Lower Fidelity Simulation Leads to Higher Sim2Real Transfer in Navigation
重新思考Sim2Real:更低保真度模拟实现导航中更高的Sim2Real迁移
J Truong, M Rudolph, N Yokoyama, S Chernova, D Batra, A Rai
[Georgia Institute of Technology & Meta AI]
https://arxiv.org/abs/2207.10821



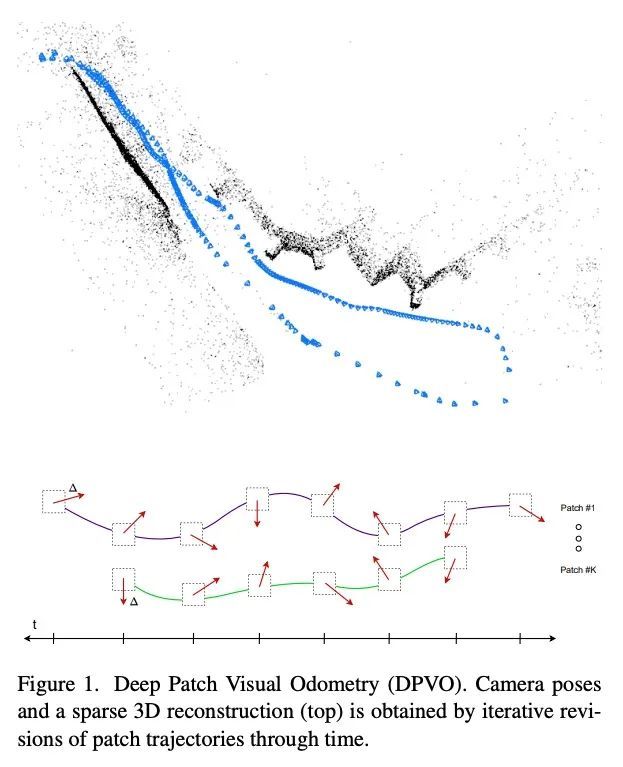
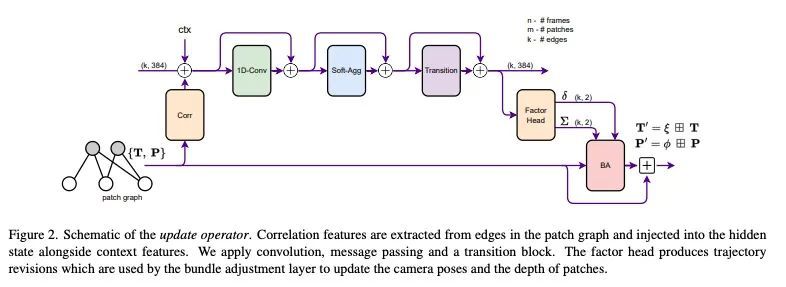
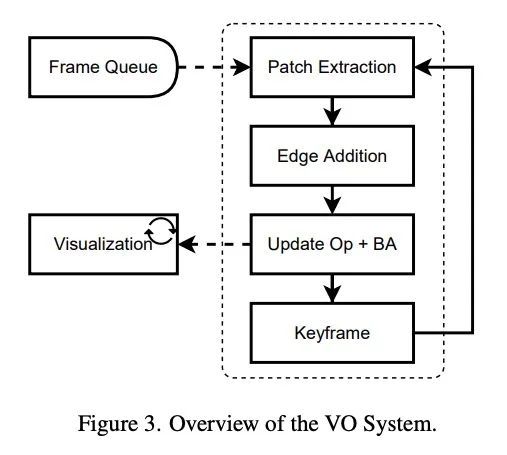
[CV] Deep Patch Visual Odometry
深度图块视觉里程计
Z Teed, L Lipson, J Deng
[Princeton University]
https://arxiv.org/abs/2208.04726

[LG] Gradients should stay on Path: Better Estimators of the Reverse- and Forward KL Divergence for Normalizing Flows
梯度应留在路径上:面向规范化流的更好的反向和正向KL散度估计器
L Vaitl, K A. Nicoli, S Nakajima, P Kessel
[Technische Universitat Berlin]
https://arxiv.org/abs/2207.08219

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢