
在ECCV 2022上,香港中文大学、香港大学、商汤科技、上海人工智能实验室和悉尼大学共同提出的研究工作Pose for Everything被接收为Oral Presentation (2.7%)。
Pose for Everything定义了一项类别无关的姿态估计 (Category-Agnostic Pose Estimation, CAPE) 任务。该任务要求检测器只根据一张参考图像和对应的关键点定义,检测任意类别物体的姿态,这极大减少了数据标注和模型训练的成本。针对该任务,论文提出了姿态匹配网络 (POse Matching Network, POMNet),将姿态估计任务建模为匹配问题,以适应不同关键点数量和关键点定义。同时,作者贡献了包含多类物体的姿态估计数据集MP-100,可以用于模型的训练和测试。

论文名称:Pose for Everything: Towards Category-Agnostic Pose Estimation
问题和挑战
2D姿态估计任务的目标是在预先人为定义物体关键点的前提下,预测图片中物体的关键点位置。如今,姿态估计已经被广泛应用于各个领域。例如,人体姿态估计有助于实现虚拟现实(VR)和增强现实(AR),车辆姿态估计是自动驾驶中的关键技术,动物姿态估计对于动物学研究和野生动物保护起到重要作用。
由于2D姿态估计的强大作用,现实生活中对于各种新物体进行姿态估计的需求层出不穷。然而,传统的姿态估计任务都是针对特定目标类别的。为了检测一种新物体的姿态,用户必须收集和标注大量此类物体的数据,并设计专门的姿态检测器进行训练。这势必带来很大的工作量和成本,并且对于领域外的研究者很不友好。为了顺应检测各种物体姿态的需求,作者定义了一个重要而困难的问题——类别无关的姿态估计(Category-Agnostic Pose Estimation,CAPE)任务。如图1所示,不同于传统的特定类别姿态估计任务,类别无关的姿态估计任务要求检测任意物体姿态,包括在训练集中没有见过的新类别。只要给定一张参考图像和对应的关键点定义,类别无关的姿态检测器即可在目标图像中检测相应的物体姿态。
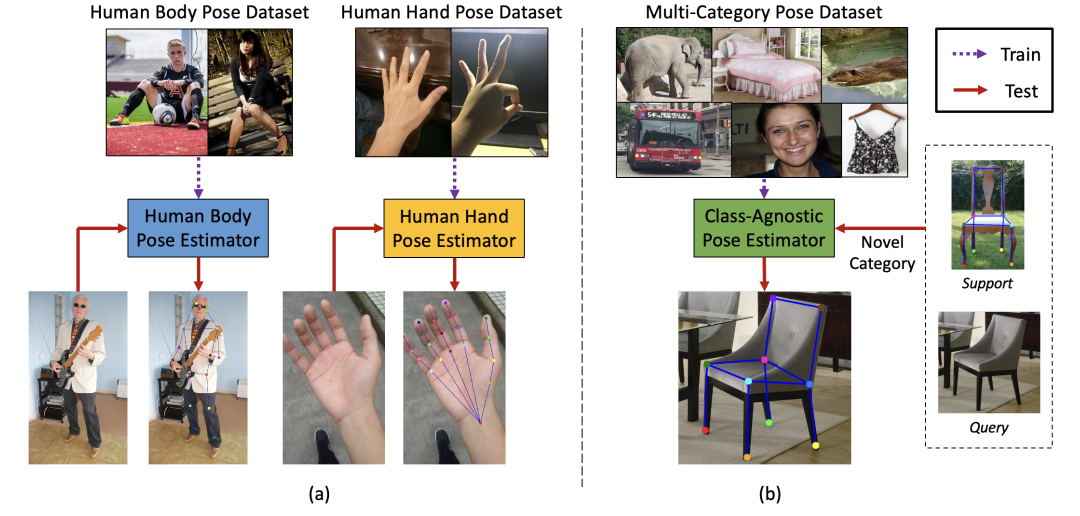
图1:特定类别姿态估计 vs 类别无关姿态估计(CAPE)
传统的2D姿态估计方法往往将姿态估计当作回归任务,利用大量数据学习如何预测特定关键点位置,这使得它们只能处理特定类别的姿态估计任务。对于类别无关的姿态估计任务,由于需要预测具有不同关键点定义和关键点数量的物体,这些方法难以适用。同时,由于缺少包含多类物体的2D姿态估计数据集,类别无关的姿态检测器的研发受到了极大阻碍。因而,作者创新性地提出了姿态匹配网络(Pose Matching Network,POMNet),以匹配的思路解决类别无关的姿态估计问题,并收集了一个大规模数据集MP-100(Multi-category Pose)来训练和测试类别无关的姿态估计模型。
方法介绍
- 类别无关姿态估计(CAPE)
本文提出的类别无关的姿态估计任务旨在对于任意类别物体,检测模型可以根据给定的关键点定义进行姿态预测。具体而言,对于没有见过的类别,只要提供一张或几张支持图像来提供关键点定义(无需大量数据重训网络),模型即可在这种类别上预测对应的关键点。因此,类别无关的姿态估计网络需要在基类上训练,在新类上测试。基类和新类是互斥的,从而保证测试类别没有在训练数据中出现过。
- 姿态匹配网络(Pose Matching Network, POMNet)
传统的姿态估计网络既不能预测没见过的新类,也不能应用于同类物体的不同的关键点定义(例如19点的人脸关键点定义和68点的人脸关键点定义)。为了实现类别无关的姿态估计,作者将其建模成匹配问题,从而提出了姿态匹配网络(Pose Matching Network, POMNet)。如图2所示,姿态匹配网络由特征提取器( 和 ),关键点交互模块(Keypoint Interaction Module,KIM)和匹配头(Matching Head,MH)组成。姿态匹配网络通过计算支持关键点特征和目标图像特征在每个位置的匹配相似度来预测关键点位置,从而实现对于不同种类物体以及不同关键点数量和定义下的姿态估计。
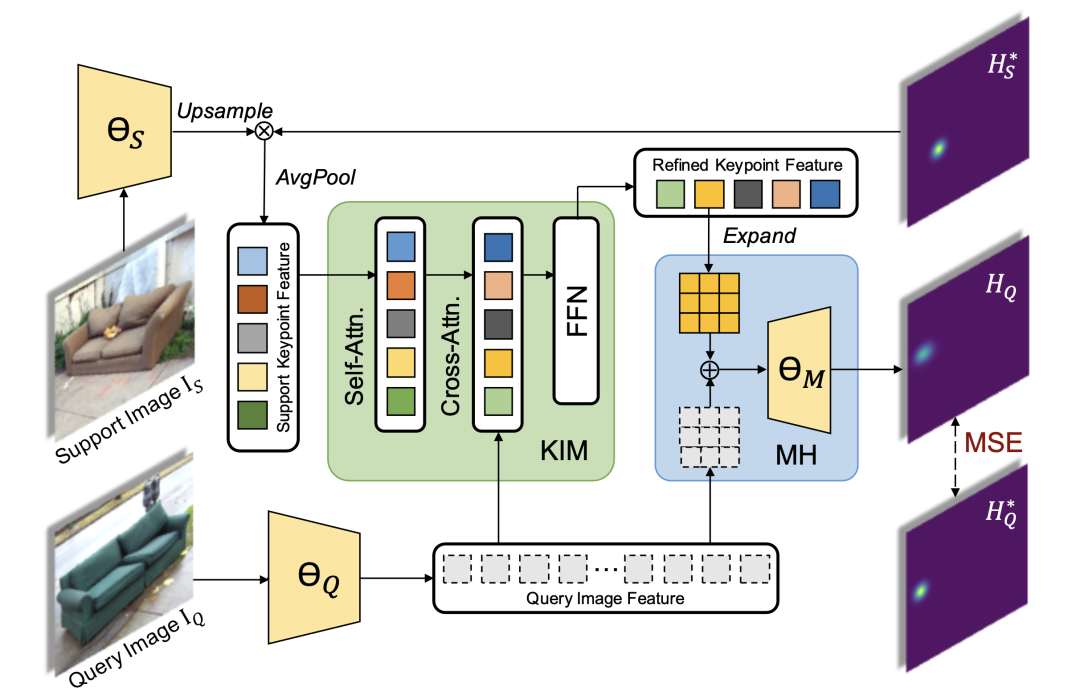
图2:姿态匹配网络示意图。特征提取器 和 分别提取支持关键点特征和目标图像特征,关键点交互模块KIM通过关键点之间的信息交互以及支持和目标图像之间的信息交互提升支持关键点特征的质量,匹配头HM整合支持关键点特征和目标图像特征来预测关键点位置。均方误差(Mean Squared Error, MSE)损失被用以监督姿态匹配网络的学习。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢