

论文地址:https://arxiv.org/abs/2203.11684
代码地址:https://github.com/zju-vipa/MEAT-TIL
摘要
持续学习是一个长期的研究课题,因为它在处理不断到达的任务中起着至关重要的作用。到目前为止,计算机视觉中持续学习的研究主要局限于卷积神经网络(CNN)。然而,最近有一种趋势是新兴的视觉Transformer(ViTs)逐渐主导计算机视觉领域,这使得基于 CNN 的持续学习落后,因为如果直接应用于 ViTs,它们可能会遭受严重的性能下降。
在本文中,作者研究了 ViT 支持的持续学习,以利用 ViT 的最新进展争取更高的性能。受 CNN 中基于mask的持续学习方法的启发,作者提出了 MEta-ATtention (MEAT),即基于自注意力的注意力,以适应对新任务进行预训练的 ViT,而不会牺牲已学习任务的性能。与以前的基于mask的方法(如 Piggyback)不同,其中所有参数都与相应的mask相关联,而 MEAT 则利用了 ViT 的特性,并且只mask了它的一部分参数。它以更少的开销和更高的准确性使 MEAT 更加高效和有效。
大量实验表明,与最先进的CNN同类模型相比,MEAT 具有显着的优势,准确度绝对提高了 4.0 ∼ 6.0%。
Motivation
在开放世界场景中,能够处理不断变化的任务是一个有利的优点。人类擅长将不断出现的任务与先前学到的知识联系起来,从而解决不断出现的任务。然而,如果由于数据偏置任务之间的差异而简单地适应新任务,深度神经网络 (DNN) 通常会遭受灾难性遗忘。
在过去几年中,大量文献致力于解决灾难性遗忘问题,以使 DNN 能够按顺序掌握新到达的任务。现有的持续学习方法可以大致分为三类:重放方法(replay methods),正则化方法(regularization methods)和掩码方法(mask methods)。重放方法重放以前的任务样本,这些样本以原始格式存储或使用生成模型生成,以减轻学习新任务时的遗忘。为了避免存储原始输入、优先考虑隐私和减轻内存需求,正则化方法引入了一个正则化项,以在学习新任务的同时巩固先前的知识。掩码方法为每个任务学习一个掩码,以使预训练的模型适应新任务,以防止任何可能的遗忘。
尽管在计算机视觉方面取得了显着进展,但上述大多数方法都是为 CNN 量身定制的,因为它们在过去十年中在该领域的主导性能。然而,由于更通用的架构(即弥合自然语言处理和计算机视觉之间的架构差距)和 ViT 的卓越性能,CNN 在计算机视觉中的首要地位最近受到视觉Transformer (ViTs) 的挑战。与 ViT 的快速发展相比,先前基于 CNN 的持续学习方法似乎有点过时,因为直接将它们应用于 ViT 并没有充分利用Transformer的特性。
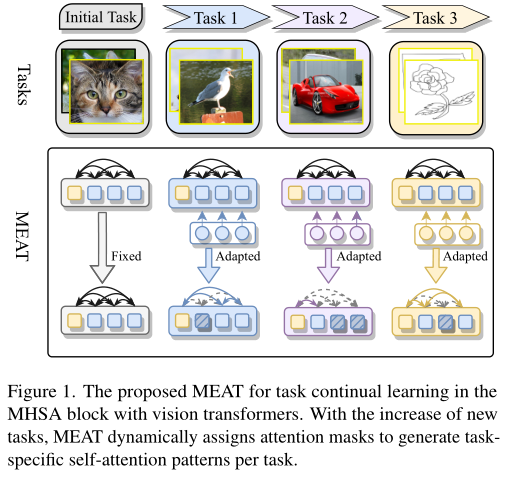
在这项工作中,作者致力于 ViT 支持的持续学习,以跟上 ViT 的进步。
具体来说,作者提出的方法基于掩模方法,主要有以下三个原因:
- 掩码方法实际上为每个任务分配了不同的参数,从而完美地绕过了灾难性的遗忘问题;
- 掩码方法对任务顺序不敏感,这在持续学习中是一个非常有利的优点;
- 掩码方法避免了昂贵的数据存储,并表现出更大的容量来处理更多的任务,这使它们比重放和正则化方法具有突出的优势。
受这些吸引人的优势的启发,作者提出了 ViT 支持的基于掩码的持续学习方法,称为MEta-ATtention (MEAT), 以进一步提高持续学习性能,如上图所示。
MEAT继承了上述所有优点,同时引入了以下与之前的掩码方法不同的创新:
- MEAT充分利用了 ViT 的架构特性,并将注意力引入到 self-attention(元注意力的来源)机制,这是为基于Transformer的架构量身定制的,使 MEAT 更加有效。
- 先前的方法,如 Piggyback,需要手动设置阈值超参数以对掩码进行二值化。MEAT 采用 Gumbel-softmax 技巧来解决离散掩码值的优化困难,从而减轻了超参数搜索的负担。
- 与先前所有参数都分配给掩码的基于掩码的方法不同,MEAT 仅将掩码引入其部分参数,这使其比先前的方法更高效。
为了验证所提出方法的优越性,在一组不同的图像分类基准和具有各种 ViT 变体上进行了广泛的实验,包括基准比较和消融研究。实验结果表明,MEAT与最先进的 CNN 同类模型相比具有显着的优势,其准确度绝对提高了 4.0 ∼ 6.0%,同时为保存特定任务的掩码而消耗的存储成本要低得多。
本文的贡献如下:
- 作者提出了MEAT,这是第一个 ViT 支持的持续学习方法,以促进 ViT 持续学习的发展。
- 作者在 MEAT 中引入了三项创新,包括mask部分参数、避免手动超参数设置和元注意机制以提高 MEA T 的性能。
- 大量实验表明,MEAT 比其最先进的 CNN 同类模型具有显着优势,同时为保存任务掩码消耗的存储成本要低得多。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢