

Masked image modeling 通过恢复损坏的图像块在自监督表示学习中展示了令人印象深刻的结果。然而,大多数方法仍然对 low-level 图像像素进行操作,这阻碍了对表示模型的 high-level 语义的利用。
在这项研究中,作者建议使用语义丰富的 visual tokenizer 作为 Mask 预测的重建目标,为将 MIM 从像素级提升到语义级提供了一种系统的方法。
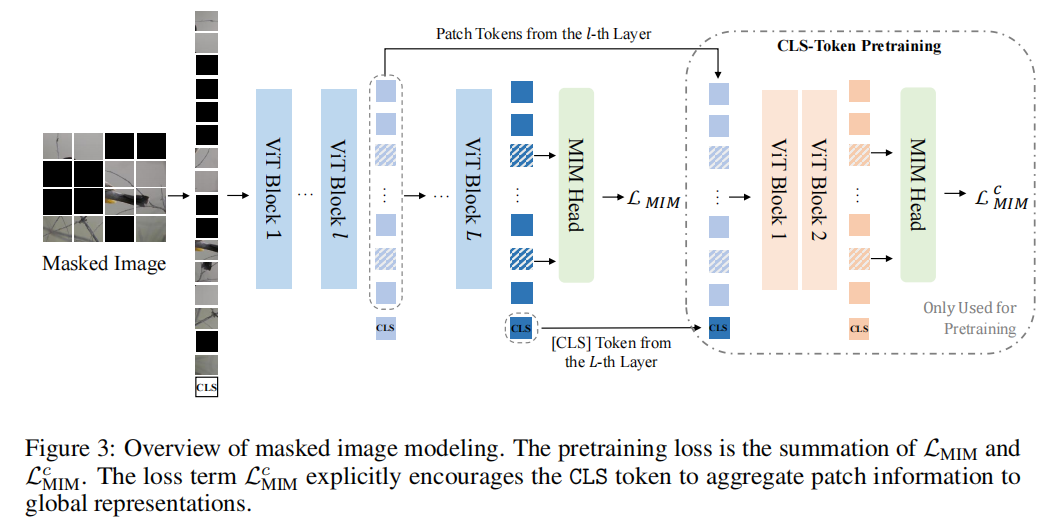
具体来说,引入向量量化知识蒸馏来训练 tokenizer,它将连续的语义空间离散化为 compact codes。然后,通过预测 masked image patches 的原始 visual tokenizer 来预训练 Vision Transformers 。此外,作者鼓励模型将patches信息显式聚合到全局图像表示中,这有助于线性预测。
图像分类和语义分割的实验表明,本文的方法优于所有比较的 MIM 方法。在 ImageNet-1K(224 大小)上,base-size BEIT V2 在微调时达到 85.5% 的 top-1 精度,在线性预测时达到 80.1% 的 top-1 精度。large-size BEIT V2 在 ImageNet-1K(224 大小)微调上获得 87.3% 的 top-1 准确率,在 ADE20K 上获得 56.7% 的 mIoU 用于语义分割。
论文链接:
https://arxiv.org/abs/2208.06366
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢