
作者:Yasmin Moslem , Rejwanul Haque , John D. Kelleher ,等
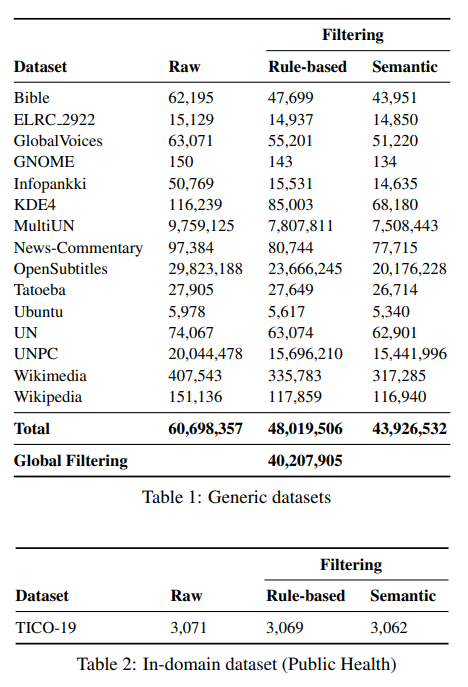
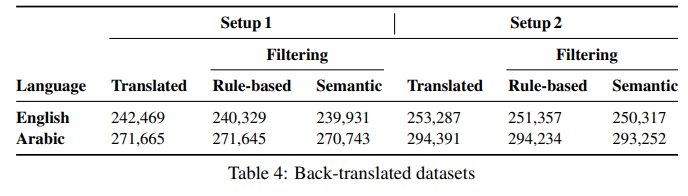
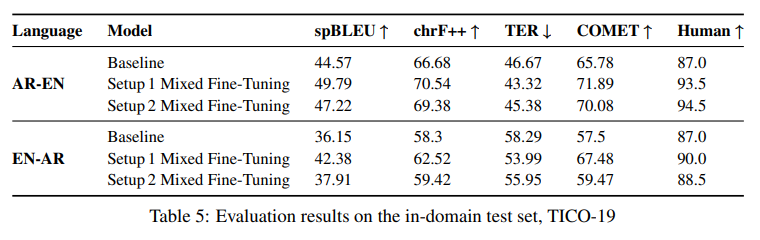
简介:本文研究以预训练语言模型为机器翻译进行特定领域的数据扩充。保存从源到目标的领域知识在任何翻译工作流程中都至关重要。在翻译行业中,接收高度专业化的项目很常见,其中几乎没有任何并行的域内数据。在没有足够的域内数据来微调机器翻译 (MT) 模型的情况下,生成与相关上下文一致的翻译具有挑战性。在这项工作中,作者提出了一种新的域适应方法,该方法利用最先进的预训练语言模型 (LM) 用于 MT 的特定域数据增强,模拟 (a) 小型双语数据集或(b) 待翻译的单语源文本。将这个想法与反向翻译相结合,作者可以为这两个用例生成大量合成的双语域内数据。作者使用最先进的 Transformer 架构,作者采用混合微调来训练模型,显著地改善了域内文本的翻译。具体地说:在上述两种情况下,作者提出的方法在阿拉伯语到英语、和英语到阿拉伯语的语言对上分别实现了大约 5-6 BLEU 和 2-3 BLEU 的改进。此外,人工评估的结果证实了自动评估结果!


论文下载:https://arxiv.org/ftp/arxiv/papers/2208/2208.05909.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢