
作者:Manzil Zaheer , Ankit Singh Rawat , Seungyeon Kim ,等
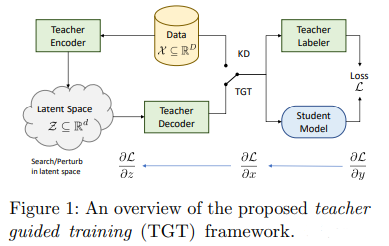
简介:大型预训练模型(例如 GPT-3)实现的显著性能提升,取决于它们在训练期间使用了大量的数据。类似地,将如此大的模型提炼成紧凑模型以进行有效部署也需要大量(标记或未标记)训练数据。在本文中,作者提出了教师指导训练框架 (TGT) ---用于训练一个高质量的紧凑模型,该模型利用预训练生成模型获得的知识,同时避免了处理大量数据的需要。TGT 利用了这样一个事实,即教师已经获得了基础数据域的良好表示,这通常对应于比输入空间低得多的维度流形。此外,作者可以使用教师模型通过采样或基于梯度的方法更有效地探索输入空间;因此,使 TGT 对于有限数据或长尾设置特别有吸引力。作者在泛化范围内正式捕获了提议的数据域探索的这种好处。作者发现 TGT 可以提高多个图像分类基准以及一系列文本分类和检索任务的准确性。
论文下载:https://arxiv.org/pdf/2208.06825.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢