
文档智能主要是指对于网页、数字文档或扫描文档所包含的文本以及丰富的排版格式等信息,通过人工智能技术进行理解、分类、提取以及信息归纳的过程。
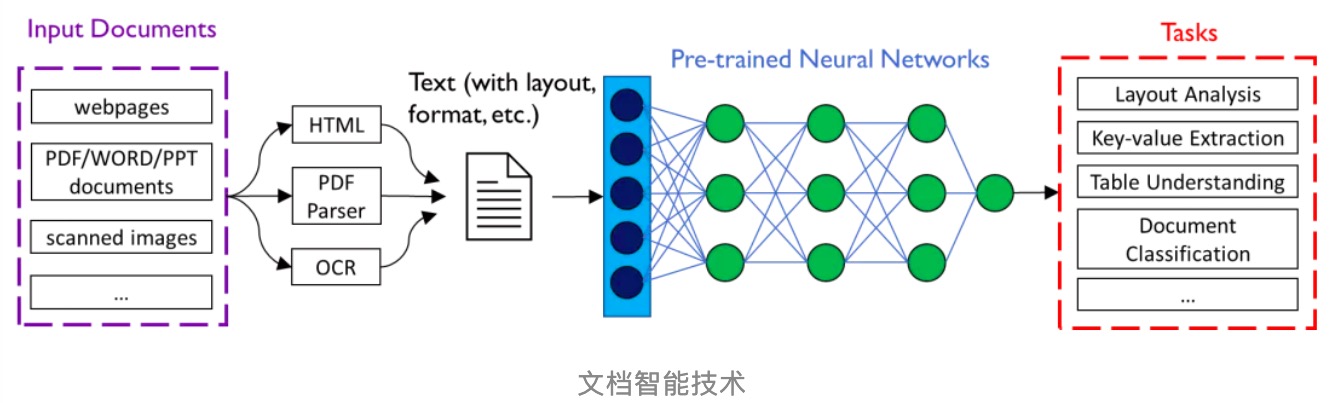 随着各类实际业务和产品的出现,文档智能领域的基准数据集也百花齐放,这些基准数据集通常包含了基于自然语言文本或图像的标注信息,涵盖了文档布局分析、表格识别、信息抽取等重要的文档智能任务,它们的出现也推动了文档智能技术的进一步发展。
传统的文档理解和分析技术往往基于人工定制的规则或少量标注数据进行学习,这些方法虽然能够带来一定程度的性能提升,但由于定制规则和可学习的样本数量不足,其通用性往往不尽如人意,而且针对不同类别文档的分析迁移成本较高。随着深度学习预训练技术的发展,以及大量无标注电子文档的积累,文档分析与识别技术进入了一个全新的时代。
微软亚洲研究院提出的 LayoutLM (论文链接:https://arxiv.org/abs/1912.13318)便是一个全新的文档理解模型,通过引入预训练技术,同时利用文本布局的局部不变性特征,可有效地将未标注文档的信息迁移到下游任务中。同时,为了解决文档理解领域现有的数据集标注规模小、标注粒度大、多模态信息缺失等缺陷,微软亚洲研究院的研究员们还提出了大规模表格识别数据集 TableBank和大规模文档布局标注数据集 DocBank(论文链接:https://arxiv.org/abs/2006.01038),利用弱监督的方法,构建了高质量的文档布局细粒度标注。
随着各类实际业务和产品的出现,文档智能领域的基准数据集也百花齐放,这些基准数据集通常包含了基于自然语言文本或图像的标注信息,涵盖了文档布局分析、表格识别、信息抽取等重要的文档智能任务,它们的出现也推动了文档智能技术的进一步发展。
传统的文档理解和分析技术往往基于人工定制的规则或少量标注数据进行学习,这些方法虽然能够带来一定程度的性能提升,但由于定制规则和可学习的样本数量不足,其通用性往往不尽如人意,而且针对不同类别文档的分析迁移成本较高。随着深度学习预训练技术的发展,以及大量无标注电子文档的积累,文档分析与识别技术进入了一个全新的时代。
微软亚洲研究院提出的 LayoutLM (论文链接:https://arxiv.org/abs/1912.13318)便是一个全新的文档理解模型,通过引入预训练技术,同时利用文本布局的局部不变性特征,可有效地将未标注文档的信息迁移到下游任务中。同时,为了解决文档理解领域现有的数据集标注规模小、标注粒度大、多模态信息缺失等缺陷,微软亚洲研究院的研究员们还提出了大规模表格识别数据集 TableBank和大规模文档布局标注数据集 DocBank(论文链接:https://arxiv.org/abs/2006.01038),利用弱监督的方法,构建了高质量的文档布局细粒度标注。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢