


https://arxiv.org/abs/2202.12165
Transformer 在自然语言处理(NLP)领域占据了很长一段时间。近年来,基于Transformer 的方法被广泛应用于计算机视觉领域,并取得了良好的效果。医学图像分析作为CV领域的一个重要分支,正当地加入了基于Transformer的方法的浪潮。在本文中,我们阐述了注意力机制的原理,Transformer 的详细结构,并描述了Transformer如何被采用到CV领域。我们按照不同的CV任务顺序组织基于Transformer的医学图像分析应用,包括分类、分割、合成、配准、定位、检测、字幕和去噪。对于主流的分类和分割任务,我们根据不同的医学影像方式进一步划分了相应的工作。我们的工作包括13种模式和20多个对象。我们还将每个模态和物体所占的比例可视化,给读者一个直观的印象。希望我们的工作能为未来基于Transformer 的医学图像分析的发展做出贡献。
Transformer[1]是自然语言处理(NLP)领域中应用最广泛的模型之一,在释义生成[2]、文本到语音合成[3]、语音识别[4]等任务中取得了巨大的成功。它被设计用于转导和序列建模在建模远程依赖与数据的显著能力内。Transformer由编码器和解码器组成,其中编码器和解码器是连续相同块的串联。它是无卷积的,完全基于自注意力机制,本文简称为注意力机制。注意力机制是将单个序列的不同位置关联起来,计算序列表示[1]的过程。在语句嵌入[5]、自然语言推理[6]、抽象摘要[7]、机器阅读[8]等NLP任务中取得了很大的成功。
与NLP领域不同,计算机视觉(CV)领域自AlexNet[12]提出以来,长期以来无论是分类[10]、分割[11]、检测[11],还是其他任务,都由卷积神经网络[9](CNN)主导。CNN是一种深度学习(deep learning, DL)模型,用网格模式处理数据,旨在捕捉特征的空间层次[13]。它具有显著的感应能力,由多种块体组成,如卷积层、全连通层等。受transformer在NLP领域取得成功的启发,许多尝试将CNN和attention结合起来[14,15],但这些尝试都没有影响CNN在CV领域的领导地位。在2020年,Dosovitskiy和同事[16]提出了一个将CNN和Transformer 直接结合的革命模型。它们对CV域使用的图像进行修补和嵌入,并将嵌入的图像提供给NLP域使用的改进transformer编码器。他们提出的工作取得了前所未有的成功,开启了用基于transformer的方法解决CV任务的里程碑。到目前为止,基于transformer 的方法已经在许多CV任务中实现,并取得了较好的效果[17,18,19]。
医学图像分析是简历领域的一个重要分支,它也应该参与到这场革命中来。它是一个处理和创建体内[20]视觉表征的过程,能够帮助医生从不同方面进行诊断。医学图像可以分为不同的模式,如MRI、CT、x射线等,这取决于图像捕获的方式。基于transformer的方法在医学图像分析中得到了广泛的应用,无论是单独使用transformer[21]还是将CNN和transformer混合来获取局部和全局信息[22]。尽管如此,仍有研究空白。以往基于transformer的医学图像分析研究都是报告实验结果的原创研究,据我们所知没有相关的发表评论。已有的文献综述[23,24,25,26,27]都集中于使用基于CNN的方法分析医学图像。为了对基于transformer的医学图像分析提供指导,我们写了这篇综述,相信它可以为进一步的研究做出很大的贡献。我们工作的整体工作流程如图1所示。
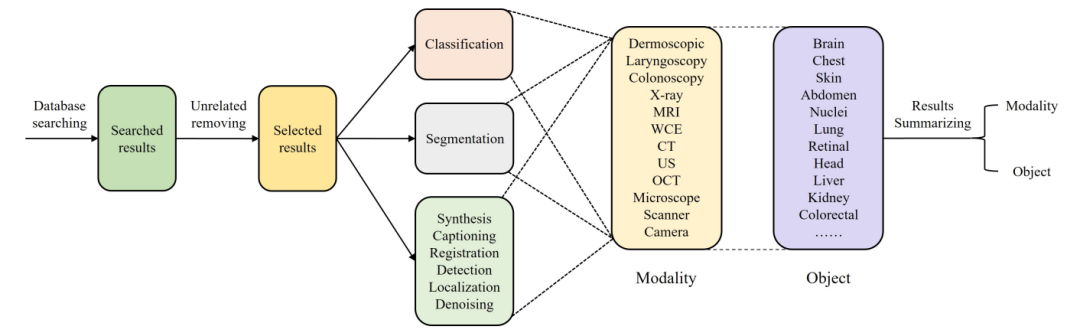
图1 我们工作的整体工作流程。我们首先在数据库中搜索相关的论文,然后删除不相关的论文。精选的论文根据不同的任务配图。在分类和分割方面,由于大量的工作,我们进一步按照模态进行划分。对于所有的任务,有13种模式包括和超过20个对象相关。最后,对模型和对象进行了总结。
本文其余部分的组织如下:在第2章中,我们阐述了注意力机制的原理,transformer 的详细结构,并描述了transformer 如何被引入CV领域。在第三章中,我们从不同的CV任务角度组织基于transformer 的医学图像分析应用,包括分类、分割、合成、配准、定位、检测、字幕和去噪。还列出了使用的相关数据集。为了分类和分割,我们进一步将工作按照模式进行划分。在这项工作中有13种模态和20多个对象。我们还将每个模态和物体所占的比例可视化,给读者一个直观的印象。第四章是结论和存在的挑战。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢