


本文是对快手和浙大联合研究的视频OCR领域工作的简要介绍,包括 CoTex【Real-time End-to-End Video Text Spotter with Contrastive Representation Learning】和 SVRep【Contrastive Learning of Semantic and Visual Representations for Text Tracking】,其中CoText被ECCV2022录用,SVRep作为前作未出版,本文后续统一用CoText作为简称。这篇文章介绍的基于对比学习和多信息融合的视频OCR模型,主要特点是能够准确、高效的跟踪和识别视频中的文字,目前在ICDAR2015-Video in Text 等多个开源数据集实现SOTA。完整的代码已经开源,我们会在文本附上链接。
一、背景
视频作为移动互联网时代飞速发展的新媒体形式,已经超越了图片、文本等传统媒体形式,正在成为互联网的主要应用,其中视频文字作为高级语义载体,是视频感知、内容理解等方面的重要基础信息。
传统的光学字符识别(OCR)研究工作集中在图像领域,主要包含文本检测和识别过程,且在很多应用场景下都取得了较高的精度。然而,近年来视频OCR(Video Text Spotting, 端到端视频文字识别,需要模型同时去完成检测,跟踪,和识别的任务)作为新的挑战,社区的关注较低,研究工作也不多,导致很多基于视频OCR的应用难以成熟落地,如视频理解,视频检索等。
先前存在的一些视频OCR研究工作,都存在以下几点问题:
- 仅利用视觉特征做视频前后帧的文字的表征,而忽略了文字的语义特征;● 文字跟踪仅基于相邻帧,忽略了视频的长时序列依赖● 现有的端到端模型,多使用多个独立子模型处理检测、跟踪、识别三个子任务,并使用手动策略(IOU等)整合结果,模型复杂,推理速度慢
为此,本文提出了一个基于对比学习和多信息表征的端到端视频OCR模型CoText,与现有的方法相比,CoText主要有4点贡献:
- 实现了一个统一的轻量级的框架,同时处理检测、跟踪、识别三个子任务,做到端到端可训练● 提出了三种轻量级特征编码结构:Visual Encoder、Semantic Encoder和Position Encoder去学习文字的视觉表示、语义表示和位置表示,让模型 “像人类一样“ 去跟踪和识别文字● 不同于先前工作(只利用两帧,做前后关联比对),CoText基于对比学习,在多信息特征空间同时学习多帧的时序信息● CoText在4个开源数据集实现SOTA,并具有更快的推理速度。其中,在ICDAR2015 Video数据集下,CoText到达了72.0%的IDF1,相比先前的SOTA算法提升10.5%的同时,推理速度为其4倍
二、方法
2.1 算法框架
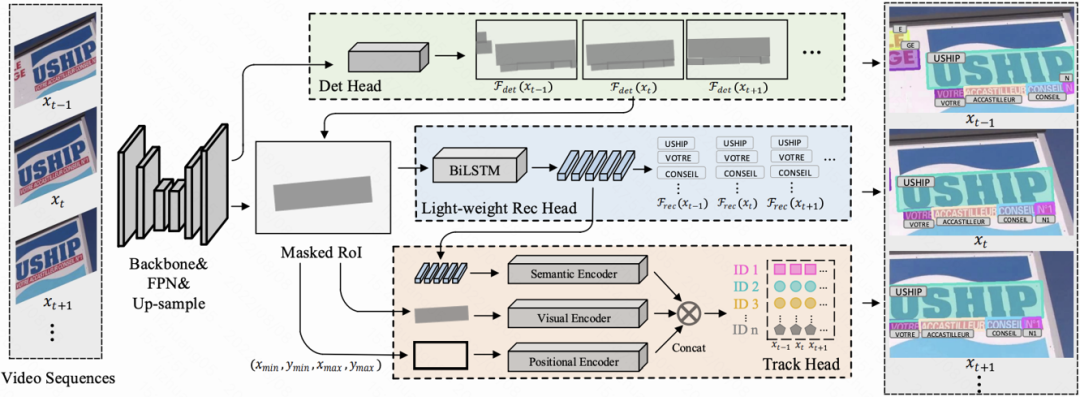
图1 CoText 算法架构
如图1所示,本文的网络框架主要包括Backbone(如Resnet18),FPN、上采样,Maked-roi和三个Head,包括检测头、识别头和跟踪头。其中检测头和Masked-Roi继承自PAN++[1];为了获得高性能的推理速度,识别头采用轻量级CRNN;对于跟踪头,我们将识别头输出的文字的语义序列特征和从Masked-roi获取的视觉特征、位置特征三种特征融合在一起,获得文字的最终特征表示R。最后通过基于余弦距离的Kuhn-Munkres(KM算法/匈牙利匹配)进行相邻帧文字的比对关联,获得最终的跟踪结果。通过这个架构,CoText可以同时获得文字的检测框、跟踪id和文字的识别内容。
在训练阶段,三种损失函数各自优化三哥任务头,其中跟踪头基于对比学习,将持续不同帧的相同文字对象视为同类,不同文本对象视作不同类,以此学习视频文字的时序信息。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢