
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:面向大规模Transformer的8比特矩阵乘法、面向视频补全的流引导Transformer、皮肤病学AI在多样化经策划临床图像集上的表现差异、基于初级射线的隐函数、教师指导训练:高效知识迁移框架、基于可微渲染的自适应联合优化3D重建、强化学习技能迁移的分层启动、3D场景神经辐射场的通用逼真风格迁移、基于2D图像的3D场景几何分解与操纵
1、[LG] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
T Dettmers, M Lewis, Y Belkada, L Zettlemoyer
[University of Washington & Facebook AI Research & Hugging Face]
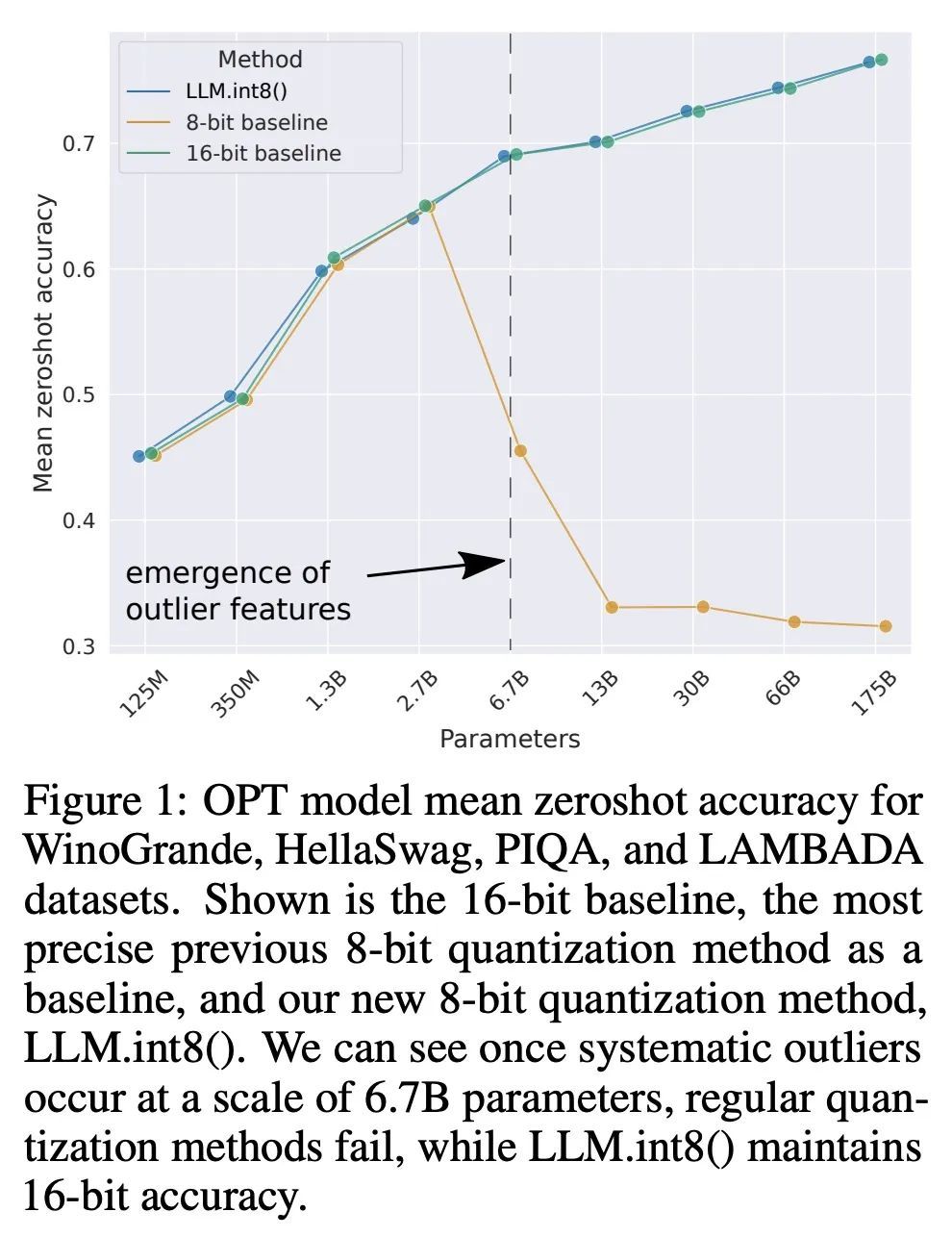
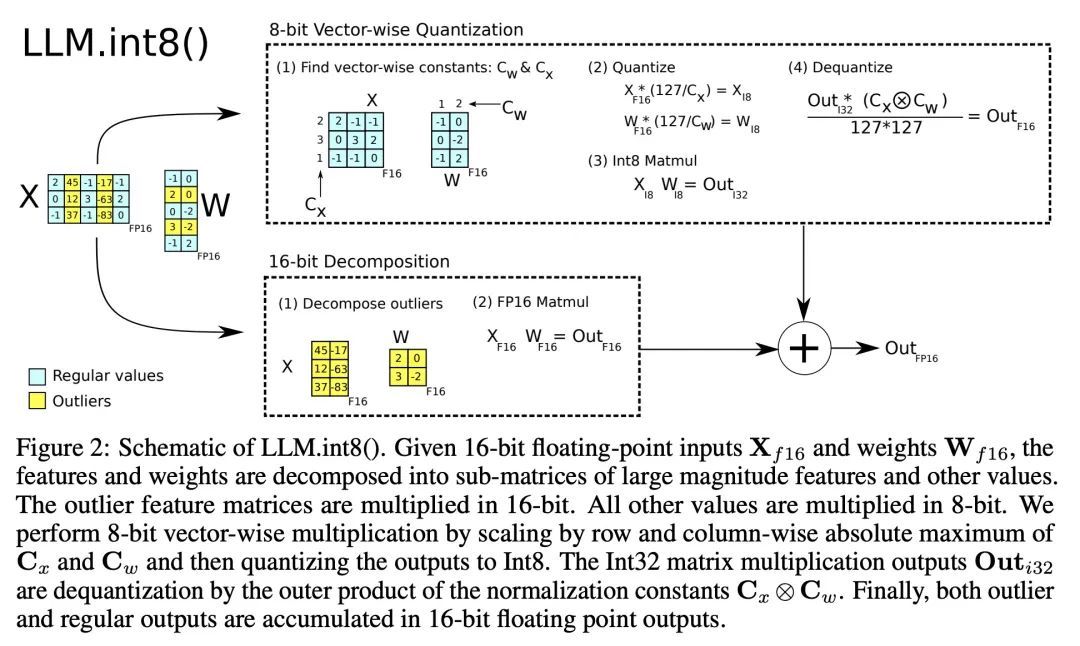
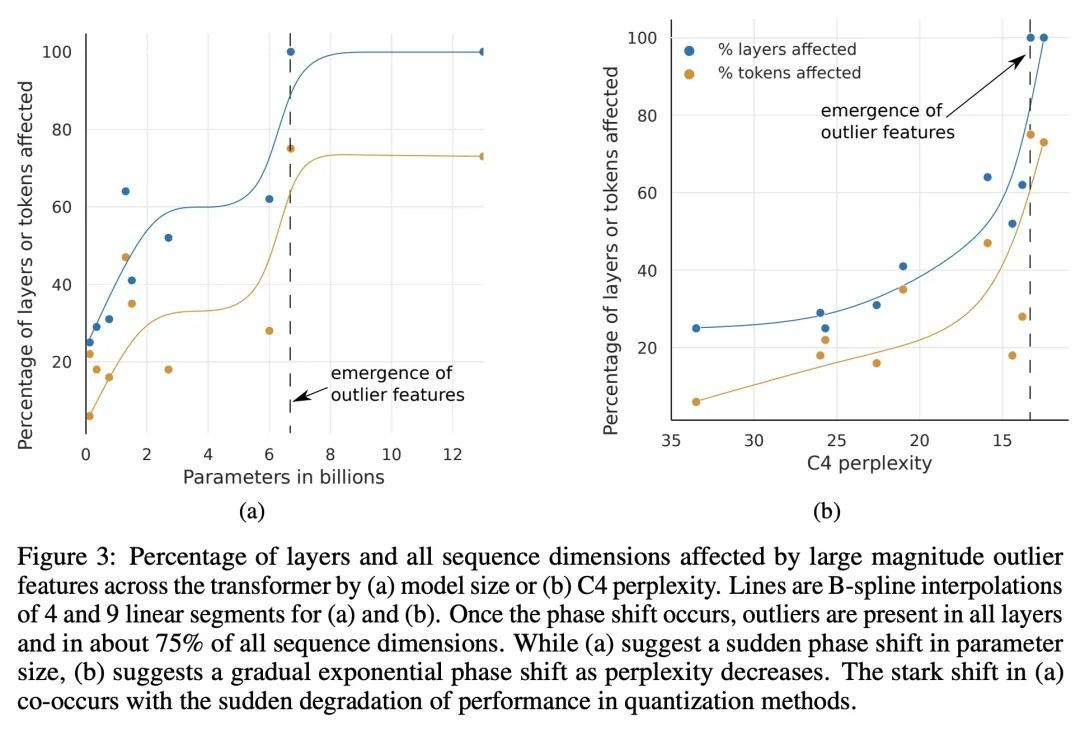
LLM.int8():面向大规模Transformer的8比特矩阵乘法。大型语言模型被广泛采用,但需要大量GPU内存进行推理。本文为Transformer中的前馈和注意力投影层开发了一种Int8矩阵乘法程序,将推理所需内存减少了一半,同时保留了全精度性能。使用该方法,一个175B参数的16/32位检查点可被加载,转换为Int8,并立即使用,不会出现性能下降。这一点是通过理解和绕过Transformer语言模型中高度系统化的突发特征的特性而实现的,这些特征主导着注意力和Transformer的预测性能。为了应对这些特征,开发了一个由两部分组成的量化程序:LLM.int8()。首先用矢量量化,对矩阵乘法中每个内积单独使用归一化常数,对大多数特征进行量化。对于出现的异常值,采用一种新的混合精度分解方案,将异常值特征维度隔离到16位的矩阵乘法中,同时仍有超过99.9%的值是以8位乘法的。使用LLM.int8(),根据经验表明有可能在参数高达175B的LLM中进行推理,而不会出现任何性能下降。这一结果使这种模型更容易获得,例如,使OPT-175B/BLOOM有可能在配置消费级GPU的单个服务器上使用。
Large language models have been widely adopted but require significant GPU memory for inference. We develop a procedure for Int8 matrix multiplication for feed-forward and attention projection layers in transformers, which cut the memory needed for inference by half while retaining full precision performance. With our method, a 175B parameter 16/32-bit checkpoint can be loaded, converted to Int8, and used immediately without performance degradation. This is made possible by understanding and working around properties of highly systematic emergent features in transformer language models that dominate attention and transformer predictive performance. To cope with these features, we develop a two-part quantization procedure, LLM.int8(). We first use vector-wise quantization with separate normalization constants for each inner product in the matrix multiplication, to quantize most of the features. However, for the emergent outliers, we also include a new mixed-precision decomposition scheme, which isolates the outlier feature dimensions into a 16-bit matrix multiplication while still more than 99.9% of values are multiplied in 8-bit. Using LLM.int8(), we show empirically it is possible to perform inference in LLMs with up to 175B parameters without any performance degradation. This result makes such models much more accessible, for example making it possible to use OPT-175B/BLOOM on a single server with consumer GPUs. We open source our software.
https://arxiv.org/abs/2208.07339

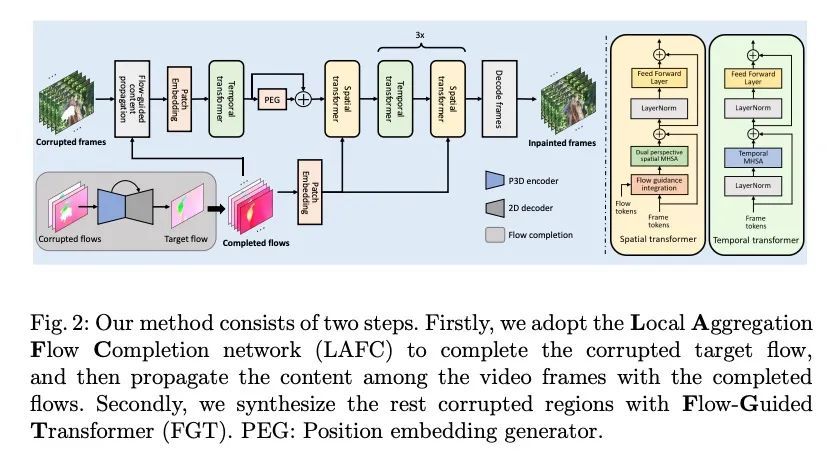
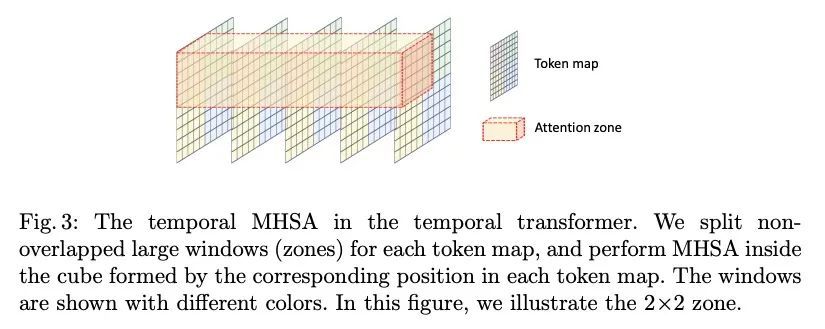
2、[CV] Flow-Guided Transformer for Video Inpainting
K Zhang, J Fu, D Liu
[University of Science and Technology of China & Microsoft Research Asia]
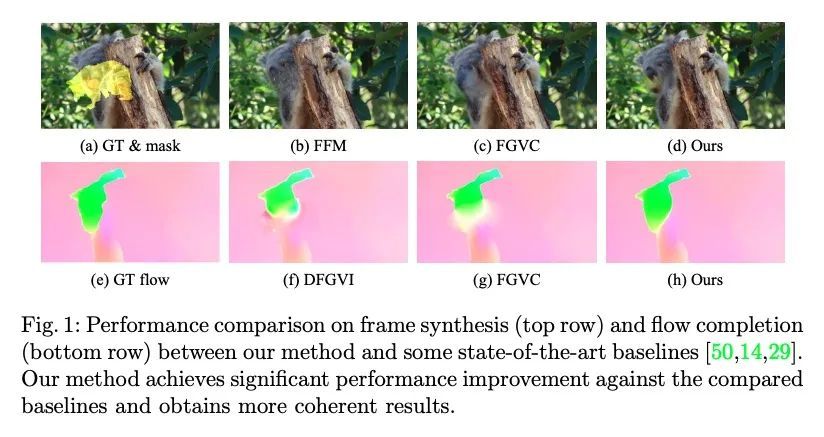
面向视频补全的流引导Transformer。本文提出一种流引导Transformer,创新性地利用光流暴露的运动差异来指导Transformer中的注意力检索,以实现高保真的视频补全。特别是,设计了一种新的流补全网络,通过利用局部时间窗口的相关流特征来补完被破坏的流。有了补完的流,在视频帧中传播内容,并采用流引导Transformer来合成其余的损坏区域。沿时间和空间维度对Transformer进行解耦,这样就可以很容易地整合局部相关的已补完的流,只指示空间注意力。此外,本文设计了一个流加权模块,以精确控制已补完的流对每个空间Transformer的影响。为提高效率,在空间和时间Transformer中都引入了窗口划分策略。特别是在空间Transformer中,设计了一种双视角空间MHSA,将全局标记整合到基于窗口的注意力中。大量的实验从质量和数量上证明了所提方法的有效性。
We propose a flow-guided transformer, which innovatively leverage the motion discrepancy exposed by optical flows to instruct the attention retrieval in transformer for high fidelity video inpainting. More specially, we design a novel flow completion network to complete the corrupted flows by exploiting the relevant flow features in a local temporal window. With the completed flows, we propagate the content across video frames, and adopt the flow-guided transformer to synthesize the rest corrupted regions. We decouple transformers along temporal and spatial dimension, so that we can easily integrate the locally relevant completed flows to instruct spatial attention only. Furthermore, we design a flow-reweight module to precisely control the impact of completed flows on each spatial transformer. For the sake of efficiency, we introduce window partition strategy to both spatial and temporal transformers. Especially in spatial transformer, we design a dual perspective spatial MHSA, which integrates the global tokens to the window-based attention. Extensive experiments demonstrate the effectiveness of the proposed method qualitatively and quantitatively. Codes are available at https://github.com/hitachinsk/FGT.
https://arxiv.org/abs/2208.06768

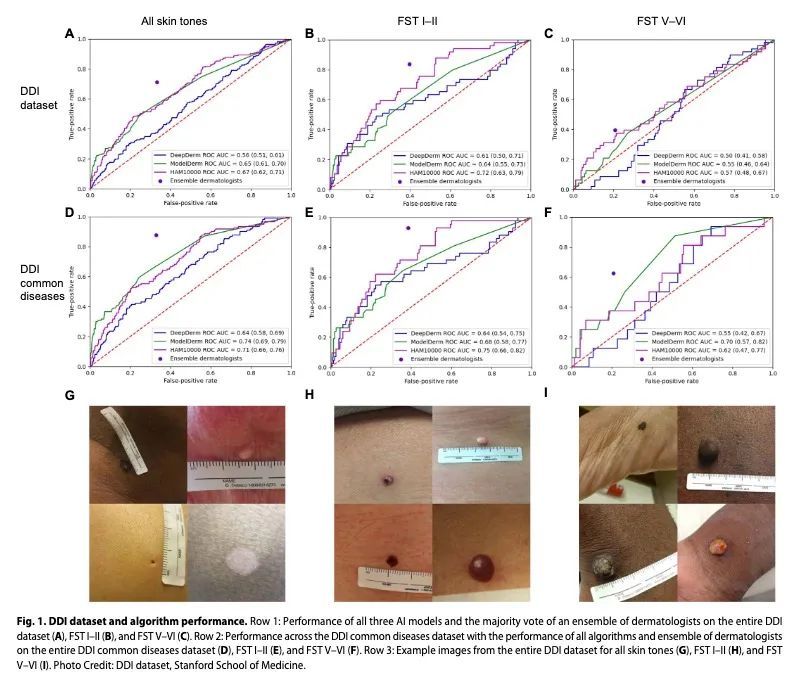
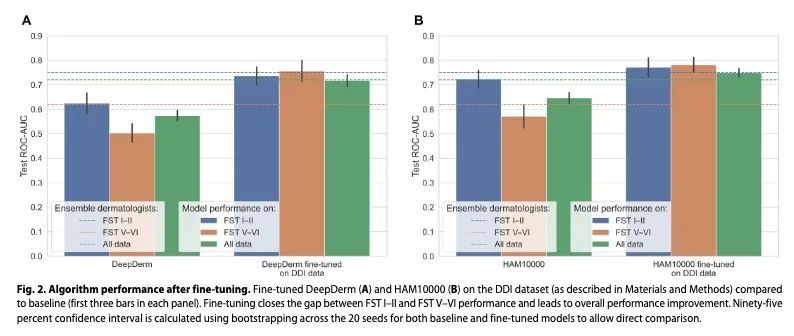
3、[CV] Disparities in Dermatology AI Performance on a Diverse, Curated Clinical Image Set
R Daneshjou, K Vodrahalli, R A Novoa, M Jenkins...
[Stanford School of Medicine & Stanford University]
皮肤病学AI在多样化经策划临床图像集上的表现差异。据估计,全球有30亿人无法获得皮肤病护理。人工智能(AI)可以帮助辨别皮肤病、识别恶性肿瘤。然而,大多数AI模型尚未对不同肤色或不常见疾病的图像进行评估。因此,本文创建了多样化皮肤病图像(DDI)数据集——第一个公开可用的、经专家策划的、经病理学证实的具有不同肤色的图像数据集。最先进的皮肤病学AI模型在DDI数据集上表现出很大的局限性,特别是在深肤色和不常见疾病上。经常给AI数据集贴标签的皮肤科医生在深色肤色和不常见疾病的图像上的表现也更差。在DDI图像上对AI模型进行微调可以缩小浅色和深色肤色间的性能差距。这些发现确定了皮肤病学AI的重要弱点和偏差,为了可靠地应用于不同的病人和疾病,应加以解决。
An estimated 3 billion people lack access to dermatological care globally. Artificial intelligence (AI) may aid in triag-ing skin diseases and identifying malignancies. However, most AI models have not been assessed on images of di-verse skin tones or uncommon diseases. Thus, we created the Diverse Dermatology Images (DDI) dataset—the first publicly available, expertly curated, and pathologically confirmed image dataset with diverse skin tones. We show that state-of-the-art dermatology AI models exhibit substantial limitations on the DDI dataset, particularly on dark skin tones and uncommon diseases. We find that dermatologists, who often label AI datasets, also perform worse on images of dark skin tones and uncommon diseases. Fine-tuning AI models on the DDI images closes the perfor-mance gap between light and dark skin tones. These findings identify important weaknesses and biases in derma-tology AI that should be addressed for reliable application to diverse patients and diseases
https://science.org/doi/epdf/10.1126/sciadv.abq6147

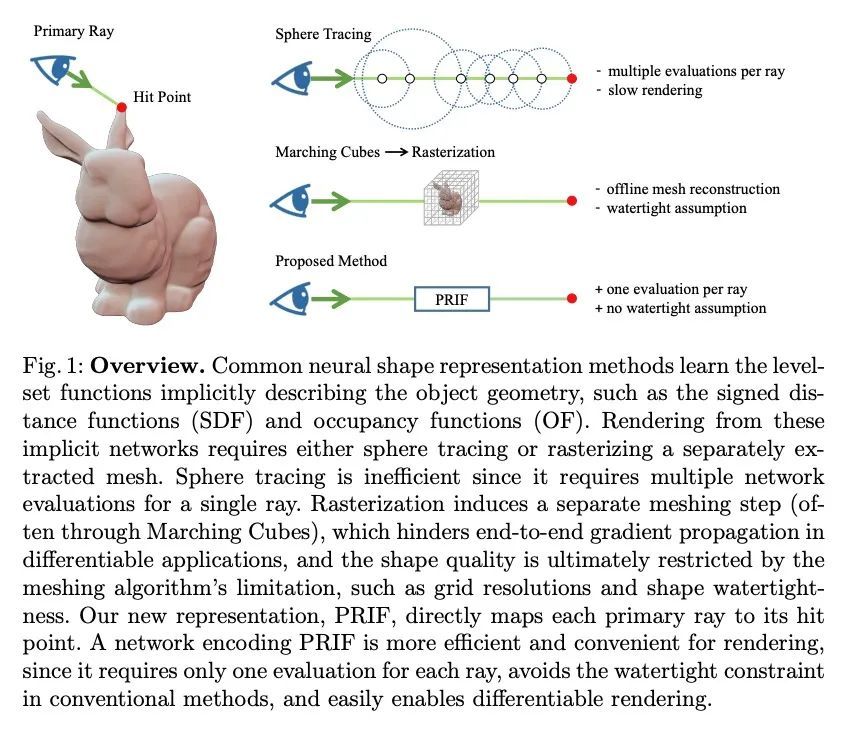
4、[CV] PRIF: Primary Ray-based Implicit Function
B Y Feng, Y Zhang, D Tang, R Du, A Varshney
[University of Maryland & Google Research]
PRIF: 基于初级射线的隐函数。本文提出一种新的隐性形状表示,即基于初级射线的隐函数(PRIF)。与大多数现有的基于有符号距离函数(SDF)的处理空间位置的方法相比,所提出的表示方法是对定向射线进行操作。PRIF被制定为直接产生给定输入射线的表面命中点,而不需要昂贵的球体追踪操作,因此能实现高效的形状提取和可微渲染。实验证明了为编码PRIF而训练的神经网络在各种任务中取得了成功,包括单一形状表示、分类形状生成、从稀疏或噪声观测中补全形状、用于相机姿态估计的逆向渲染,以及带颜色的神经渲染。
We introduce a new implicit shape representation called Primary Ray-based Implicit Function (PRIF). In contrast to most existing approaches based on the signed distance function (SDF) which handles spatial locations, our representation operates on oriented rays. Specifically, PRIF is formulated to directly produce the surface hit point of a given input ray, without the expensive sphere-tracing operations, hence enabling efficient shape extraction and differentiable rendering. We demonstrate that neural networks trained to encode PRIF achieve successes in various tasks including single shape representation, category-wise shape generation, shape completion from sparse or noisy observations, inverse rendering for camera pose estimation, and neural rendering with color.
https://arxiv.org/abs/2208.06143



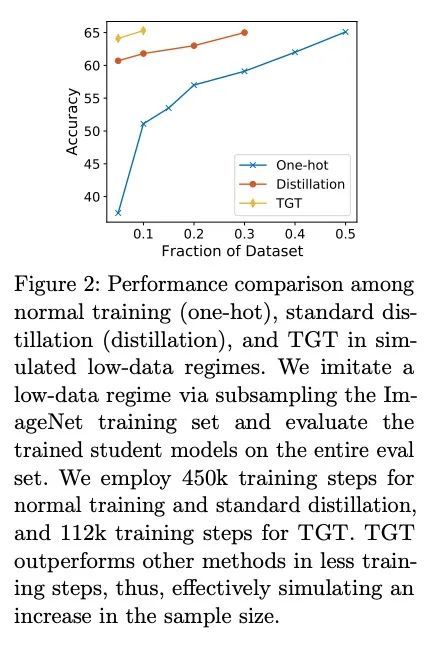
5、[LG] Teacher Guided Training: An Efficient Framework for Knowledge Transfer
M Zaheer, A S Rawat, S Kim, C You, H Jain, A Veit, R Fergus, S Kumar
[Google Research]
教师指导训练:一种高效知识迁移框架。大型预训练模型(如GPT-3)所实现的显著性能提升,取决于它们在训练期间所接触的大量数据。同样,将这种大型模型蒸馏成紧凑的模型以实现高效部署,也需要大量的(有标签或无标签的)训练数据。本文提出了教师指导训练(TGT)框架,用于训练高质量紧凑模型,利用预训练生成模型获得的知识,同时避免对大量数据的需要。TGT利用了这样一个事实,即教师已经获得了底层数据域的良好表示,这通常对应于比输入空间更低维的流形。此外,可以利用教师通过采样或基于梯度的方法更有效地探索输入空间;因此,使TGT对有限的数据或长尾设置特别有吸引力。在泛化界正式捕捉到了所提数据域探索的这种好处。TGT可提高几个图像分类基准以及一系列文本分类和检索任务的精度。
The remarkable performance gains realized by large pretrained models, e.g., GPT-3, hinge on the massive amounts of data they are exposed to during training. Analogously, distilling such large models to compact models for efficient deployment also necessitates a large amount of (labeled or unlabeled) training data. In this paper, we propose the teacher-guided training (TGT) framework for training a high-quality compact model that leverages the knowledge acquired by pretrained generative models, while obviating the need to go through a large volume of data. TGT exploits the fact that the teacher has acquired a good representation of the underlying data domain, which typically corresponds to a much lower dimensional manifold than the input space. Furthermore, we can use the teacher to explore input space more efficiently through sampling or gradient-based methods; thus, making TGT especially attractive for limited data or long-tail settings. We formally capture this benefit of proposed data-domain exploration in our generalization bounds. We find that TGT can improve accuracy on several image classification benchmarks as well as a range of text classification and retrieval tasks.
https://arxiv.org/abs/2208.06825


另外几篇值得关注的论文:
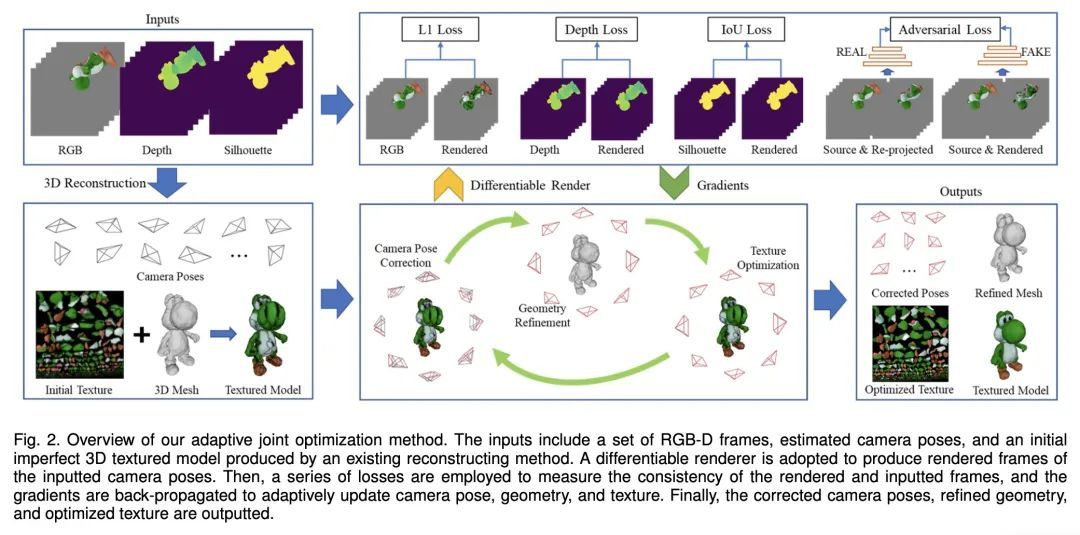
[CV] Adaptive Joint Optimization for 3D Reconstruction with Differentiable Rendering
基于可微渲染的自适应联合优化3D重建
J Zhang, Z Wan, J Liao
[City University of Hong Kong]
https://arxiv.org/abs/2208.07003



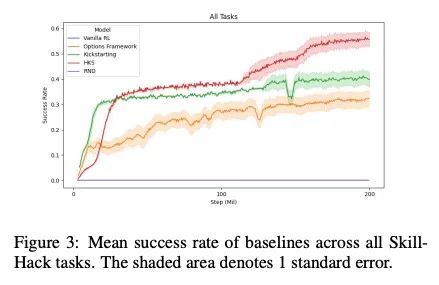
[LG] Hierarchical Kickstarting for Skill Transfer in Reinforcement Learning
强化学习技能迁移的分层启动
M Matthews, M Samvelyan, J Parker-Holder, E Grefenstette, T Rocktäschel
[University College London & University of Oxford]
https://arxiv.org/abs/2207.11584



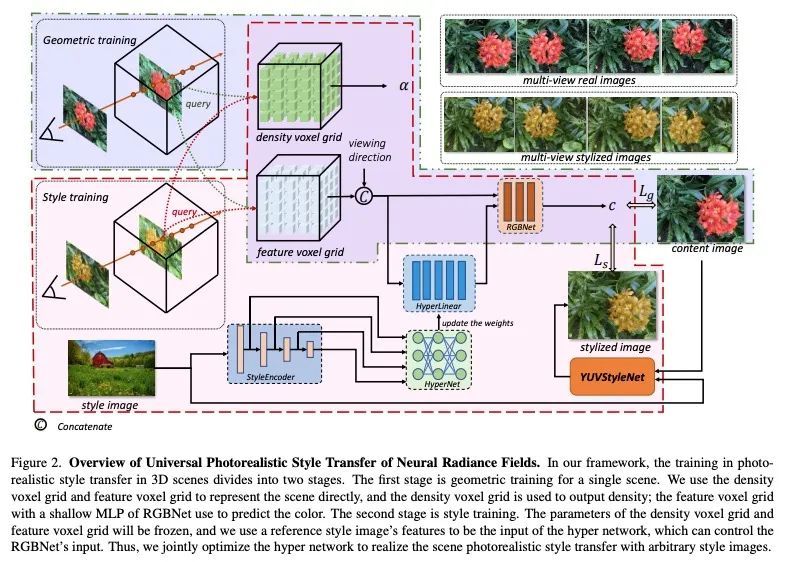
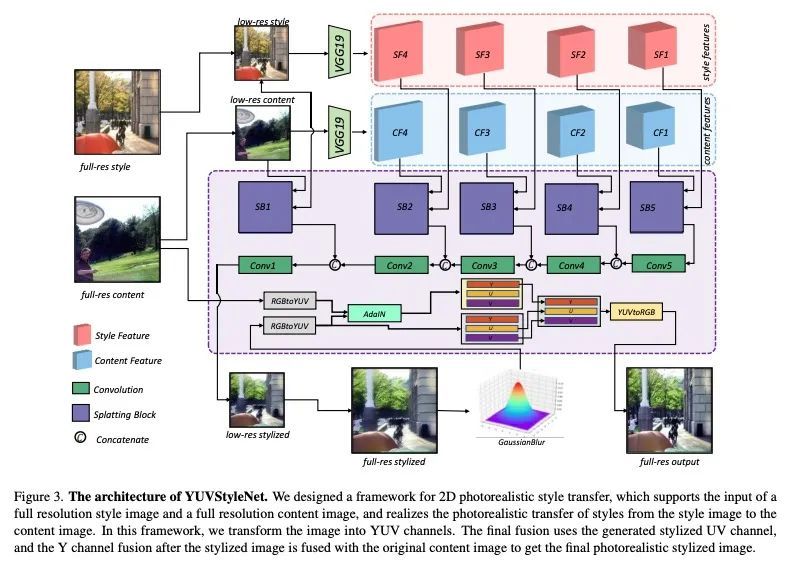
[CV] UPST-NeRF: Universal Photorealistic Style Transfer of Neural Radiance Fields for 3D Scene
UPST-NeRF:3D场景神经辐射场的通用逼真风格迁移
Y Chen, Q Yuan, Z Li, Y L W W C Xie, X Wen, Q Yu
[ChengDu Sobey Digital Technology Co., Ltd & Sichuan University]
https://arxiv.org/abs/2208.07059


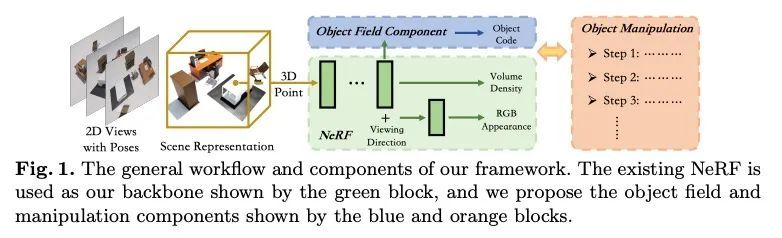
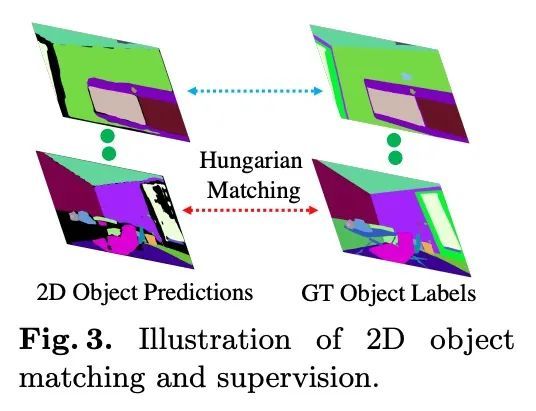
[CV] DM-NeRF: 3D Scene Geometry Decomposition and Manipulation from 2D Images
DM-NeRF:基于2D图像的3D场景几何分解与操纵
B Wang, L Chen, B Yang
[The Hong Kong Polytechnic University]
https://arxiv.org/abs/2208.07227


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢