
今天给大家带来一篇北航和微软出品的稠密向量检索模型Dual-Cross-Encoder,结合Query生成和对比学习技术,将文档与生成的不同伪query进行深度交互学习构建文档的不同视角的表征向量,再与Query向量进行稠密向量检索。论文名为《Learning Diverse Document Representations with Deep Query Interactions for Dense Retrieval》。
Paper:https://arxiv.org/pdf/2208.04232.pdf
Github:https://github.com/jordane95/dual-cross-encoder
介绍
目前,稠密向量检索已经在信息检索中起着至关重要的地位,相较于传统的BM25,它可以更好地获取问题与文档之间的语义信息。针对query和document的相关性评分主要有Dual-Encoder和Cross-Encoder两种框架:
- Cross-Encoder,由于计算量太大,无法在召回阶段使用;
- Dual-Encoder,由于query和document没有相互,并且无法很好地表现长文档中的多主题内容。
一些研究(Poly-Encoder、ColBERT等)致力于用后期交互体系结构,权衡模型的速度与效果,但「无法直接使用ANN进行排序」。与之前的工作不同,我们主要使用生成的query来学习查询通知的文档表示。
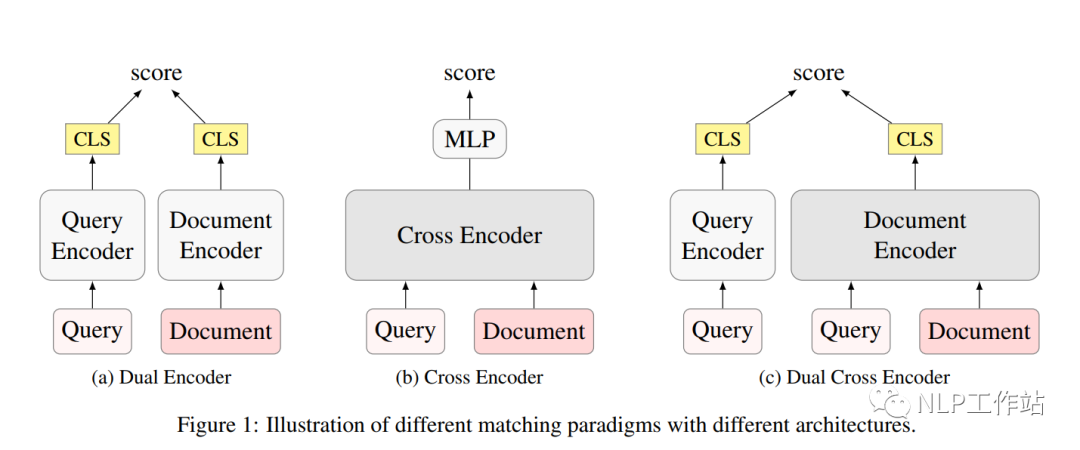
我们提出了一种新的稠密检索模型,使用生成的伪query与每个文档进行深度交互编码,以获得融合query信息的多视角文档表示,并单独编码query向量,使得该模型不仅像普通的Dual-Encoder模型一样具有很高的推理效率,而且在文档编码中与query深度交互,提供多视角表示,以更好地匹配不同的查询query。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢