
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:将ViT架构整合到DDPM的混合判别-生成扩散模型、基于社交媒体词汇分析绘制美国文化区域图、用无模型强化学习在20分钟内学会走路、域不变表示学习的统一因果观、问答模型随时间推移自适应新知识的基准、将Python程序表示为机器学习图的库、基于大型语言模型的Ad-hoc任务自适应交互式视觉提示工程、基于预训练StyleGAN3分解重组的人脸视频生成、简单差分隐私线性回归
1、[CV] Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
X Yang, S Shih, Y Fu, X Zhao, S Ji
[Georgia State University & Etsy Inc.]
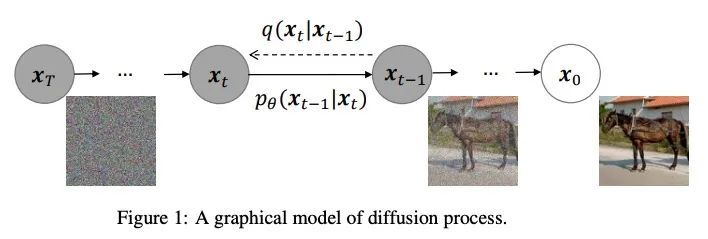
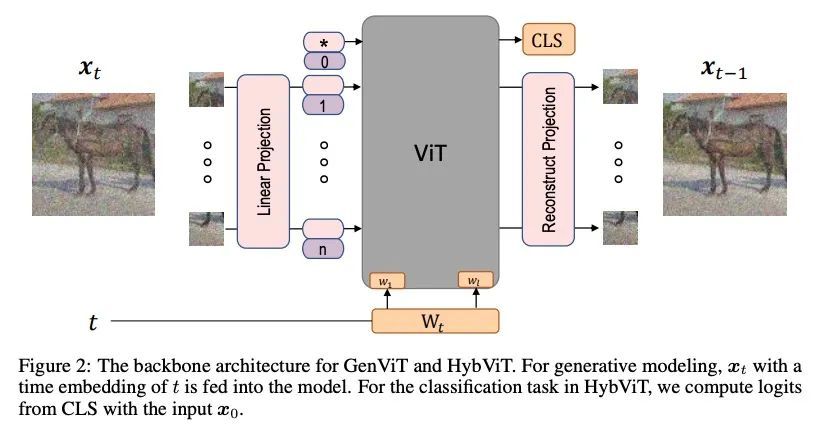
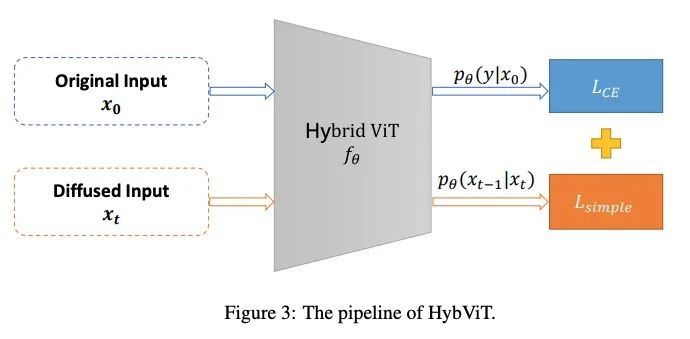
将ViT架构整合到DDPM的混合判别-生成扩散模型。扩散去噪概率模型(DDPM)和视觉Transformer(ViT)分别在生成式任务和判别式任务方面取得了重大进展,到目前为止,这些模型基本上都是在各自的领域内发展的。在本文中,我们通过将ViT架构整合到DDPM中,建立了DDPM和ViT之间的直接联系,并引入了一种新的生成模型,即生成式ViT(GenViT)。ViT的建模灵活性使得能进一步将GenViT扩展到混合判别生成模型,并引入混合ViT(HybViT)。本文是最早探索单个ViT用于图像生成和分类的工作之一。本文进行了一系列的实验来分析所提出的模型的性能,并证明了它们在生成和判别任务中都比之前的最先进水平要高。
Diffusion Denoising Probability Models (DDPM) [31] and Vision Transformer (ViT) [14] have demonstrated significant progress in generative tasks and discriminative tasks, respectively, and thus far these models have largely been developed in their own domains. In this paper, we establish a direct connection between DDPM and ViT by integrating the ViT architecture into DDPM, and introduce a new generative model called Generative ViT (GenViT). The modeling flexibility of ViT enables us to further extend GenViT to hybrid discriminativegenerative modeling, and introduce a Hybrid ViT (HybViT). Our work is among the first to explore a single ViT for image generation and classification jointly. We conduct a series of experiments to analyze the performance of proposed models and demonstrate their superiority over prior state-of-the-arts in both generative and discriminative tasks. Our code and pre-trained models can be found in https://github.com/sndnyang/Diffusion_ViT.
https://arxiv.org/abs/2208.07791

2、[CL] American cultural regions mapped through the lexical analysis of social media
T Louf, B Gonçalves, J J. Ramasco, D Sanchez, J Grieve
[UIB-CSIC & New York City & University of Birmingham]
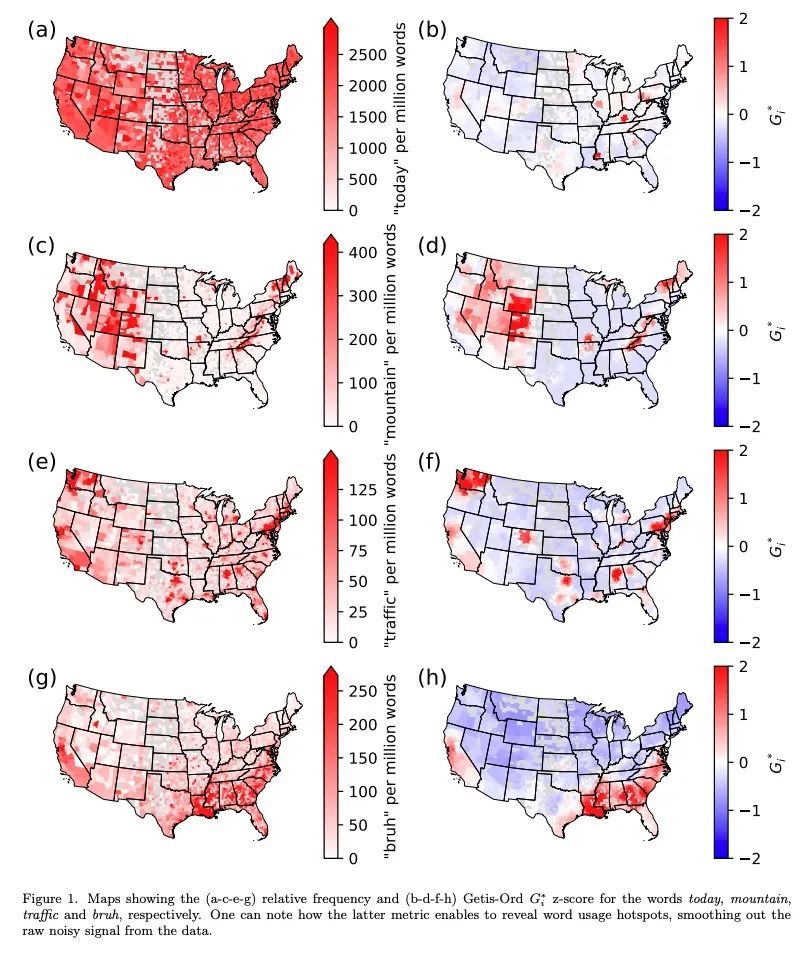
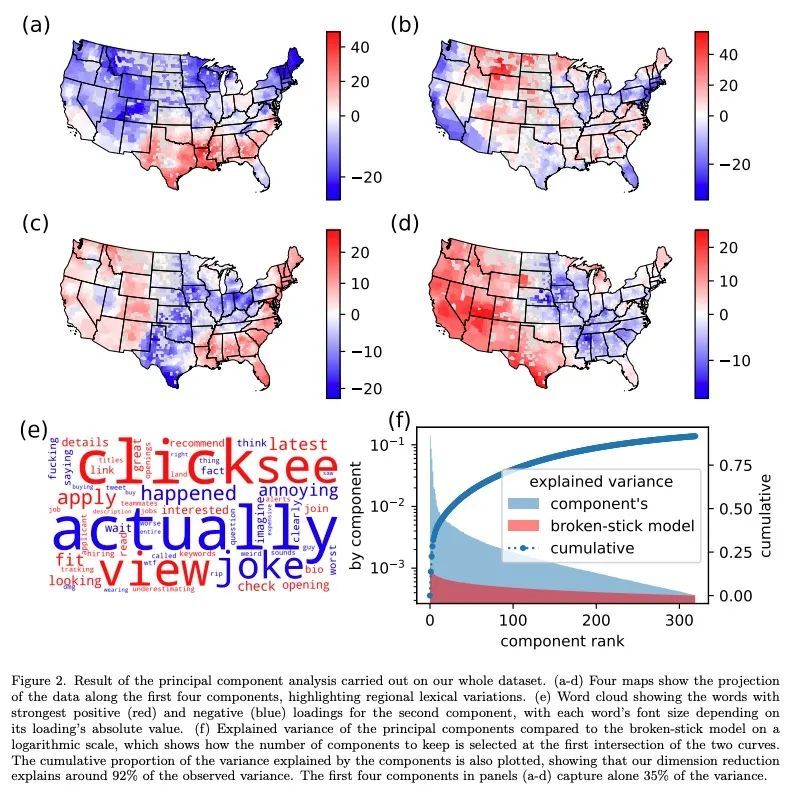
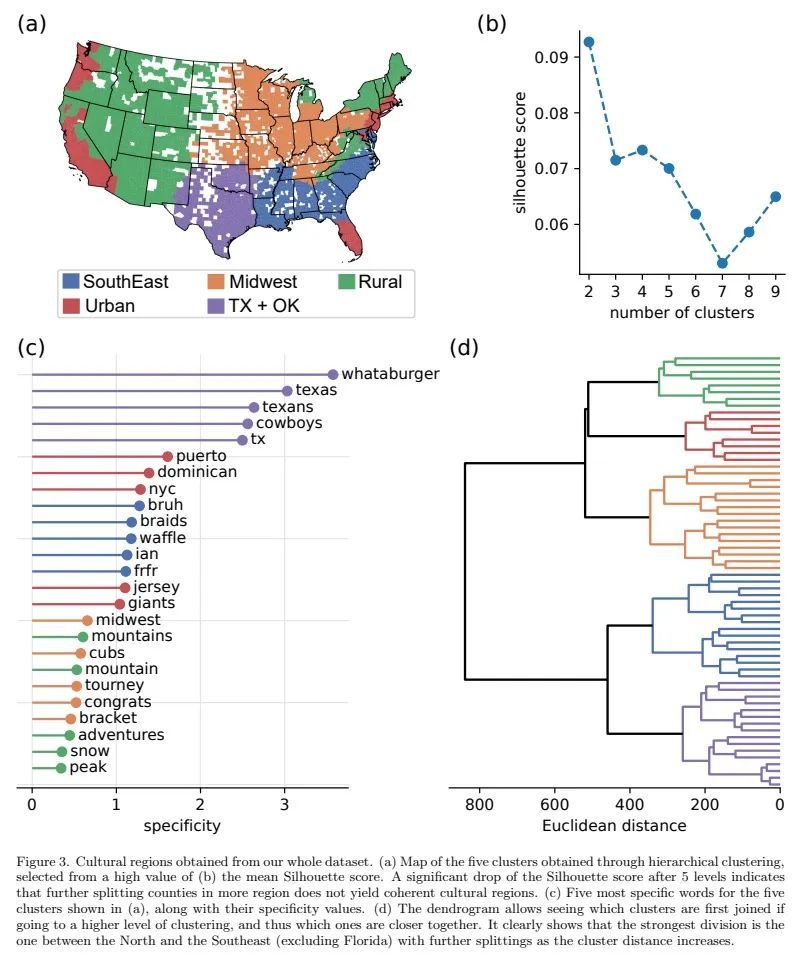
基于社交媒体词汇分析绘制美国文化区域图。文化区域代表了一种有用的概念,使社会科学的不同领域交叉融合。有关人类如何在一个社会中组织和联系他们的思想和行为的知识,有助于理解他们对不同问题的行动和态度。然而,选择塑造一个文化区域的共同特征是有些随意的。现在需要一种方法,可以利用网上的大量数据,特别是通过社交媒体,来识别文化区域,而不需要临时的假设、偏见或预判。本文朝着这个方向迈出了关键的一步,引入了一种基于微博帖子的大型数据集自动分析的方法来推断文化区域。该方法基于这样的原则:文化归属可以从人们之间讨论的话题中推断出来。具体来说,衡量美国社交媒体中产生的书面话语的区域差异。从有地理标记的推文中的内容词的频率分布中,找到这些词的使用区域热点,并从中得出了区域变化的主成分。通过在这个低维空间中对数据进行层次聚类,所提出方法产生了明确的文化区域和定义这些区域的讨论主题。最终得到了明显的南北分离,这主要是受非裔美国人文化的影响,以及进一步的毗连(东西)和非毗连(城市-农村)的划分,提供了当今美国文化区域的全面概况。
Cultural areas represent a useful concept that cross-fertilizes diverse fields in social sciences. Knowledge of how humans organize and relate their ideas and behavior within a society helps to understand their actions and attitudes towards different issues. However, the selection of common traits that shape a cultural area is somewhat arbitrary. What is needed is a method that can leverage the massive amounts of data coming online, especially through social media, to identify cultural regions without ad-hoc assumptions, biases or prejudices. In this work, we take a crucial step towards this direction by introducing a method to infer cultural regions based on the automatic analysis of large datasets from microblogging posts. Our approach is based on the principle that cultural affiliation can be inferred from the topics that people discuss among themselves. Specifically, we measure regional variations in written discourse generated in American social media. From the frequency distributions of content words in geotagged Tweets, we find the words’ usage regional hotspots, and from there we derive principal components of regional variation. Through a hierarchical clustering of the data in this lower-dimensional space, our method yields clear cultural areas and the topics of discussion that define them. We obtain a manifest North-South separation, which is primarily influenced by the African American culture, and further contiguous (East-West) and non-contiguous (urban-rural) divisions that provide a comprehensive picture of today’s cultural areas in the US.
https://arxiv.org/abs/2208.07649
3、[RO] A Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning
L Smith, I Kostrikov, S Levine
[UC Berkeley]
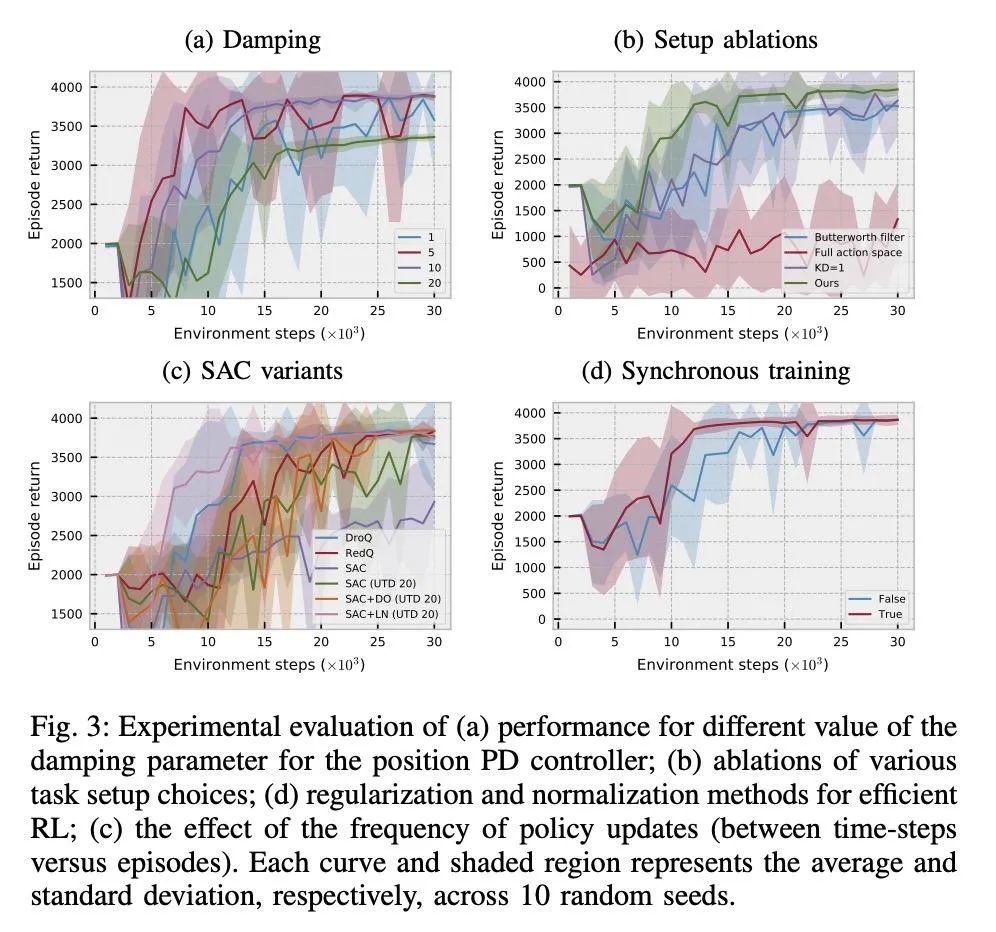
公园漫步:用无模型强化学习在20分钟内学会走路。深度强化学习是在不需要领域知识的不可控环境中学习策略的一种有前途的方法。不幸的是,由于样本的低效率,深度强化学习的应用主要集中在模拟环境中。本文证明了机器学习算法和库的最新进展与精心调整的机器人控制器相结合,在现实世界中只需20分钟就能学会四足动物的运动。在几个室内和室外的地形上评估了所提出的方法,这些地形对于经典的基于模型的控制器来说是具有挑战性的。可以观察到机器人能够在所有这些地形上持续学习行走步态。最后,在一个模拟环境中评估了所做的设计决定。
Deep reinforcement learning is a promising approach to learning policies in uncontrolled environments that do not require domain knowledge. Unfortunately, due to sample inefficiency, deep RL applications have primarily focused on simulated environments. In this work, we demonstrate that the recent advancements in machine learning algorithms and libraries combined with a carefully tuned robot controller lead to learning quadruped locomotion in only 20 minutes in the real world. We evaluate our approach on several indoor and outdoor terrains which are known to be challenging for classical modelbased controllers. We observe the robot to be able to learn walking gait consistently on all of these terrains. Finally, we evaluate our design decisions in a simulated environment. We provide videos of all real-world training and code to reproduce our results on our website: https://sites.google.com/ berkeley.edu/walk-in-the-park
https://arxiv.org/abs/2208.07860



4、[LG] A Unified Causal View of Domain Invariant Representation Learning
Z Wang, V Veitch
[University of Chicago & Google Research]
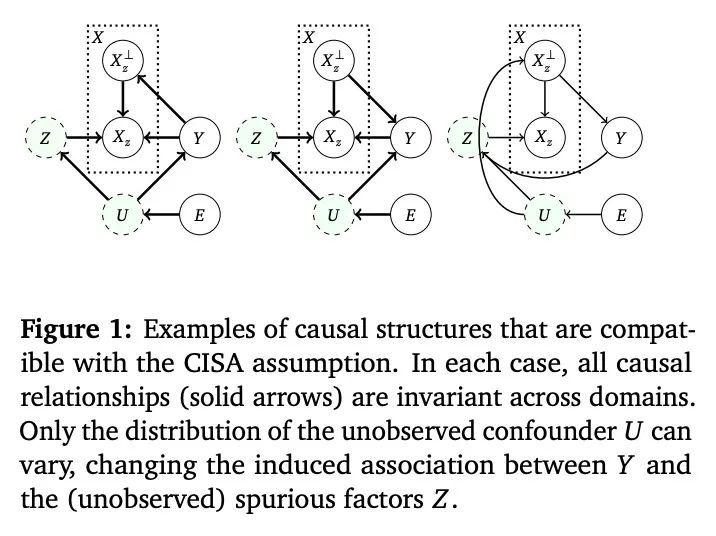
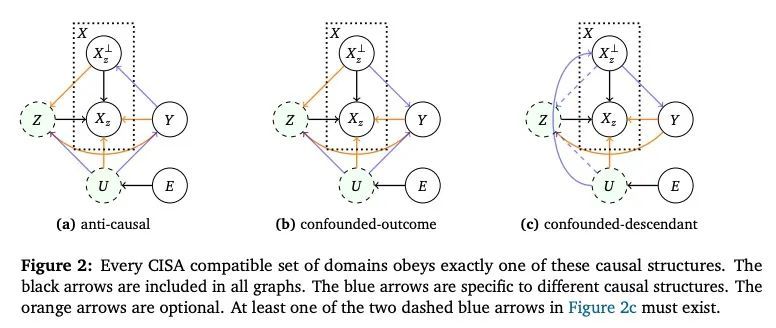
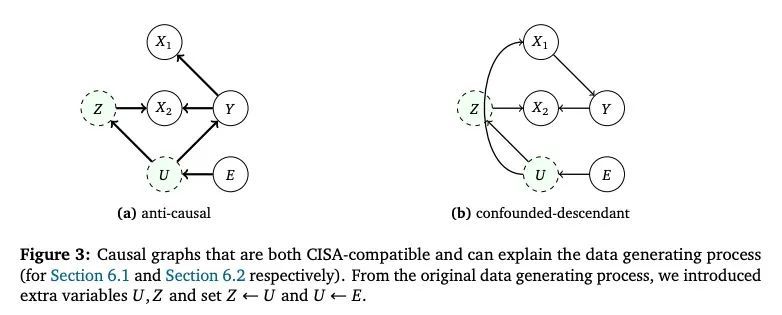
域不变表示学习的统一因果观。当机器学习方法部署在与它们所训练域不同的域时,可能是不可靠的。为解决这个问题,可能希望学习数据域不变的表示,也就是说,保留了跨领域稳定的数据结构,但扔掉了虚假变化的部分。这种类型的表示学习方法有很多,包括基于数据增强、分布不变量和风险不变量的方法。不幸的是,当面对任何特定的现实世界的域转变时,不清楚这些方法中哪一个(如果有的话)可能会期望发挥作用。本文的目的是展示不同方法之间的关系,并澄清在现实世界中每种方法有望成功的情况。关键工具是一种新的域迁移概念,它依赖于因果关系是不变的,但非因果关系(例如,由于混杂)可能会变化。
Machine learning methods can be unreliable when deployed in domains that differ from the domains on which they were trained. To address this, we may wish to learn representations of data that are domain-invariant in the sense that we preserve data structure that is stable across domains, but throw out spuriously-varying parts. There are many representation-learning approaches of this type, including methods based on data augmentation, distributional invariances, and risk invariance. Unfortunately, when faced with any particular real-world domain shift, it is unclear which, if any, of these methods might be expected to work. The purpose of this paper is to show how the different methods relate to each other, and clarify the real-world circumstances under which each is expected to succeed. The key tool is a new notion of domain shift relying on the idea that causal relationships are invariant, but non-causal relationships (e.g., due to confounding) may vary.
https://arxiv.org/abs/2208.06987

5、[CL] StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models
A Liška, T Kočiský, E Gribovskaya, T Terzi, E Sezener, D Agrawal...
[DeepMind & Glyphic AI]
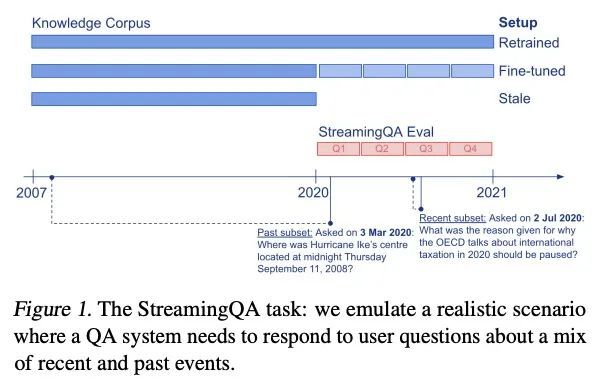
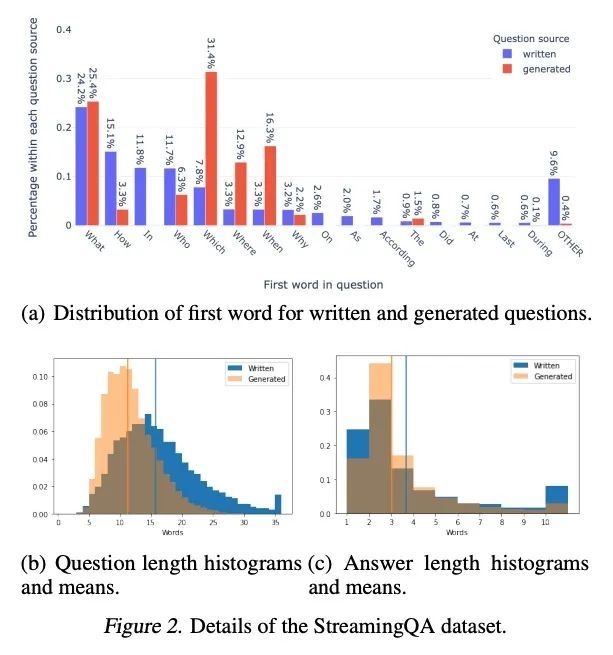
StreamingQA:问答模型随时间推移自适应新知识的基准。通过问答(QA)评估的模型知识及语言理解通常是在静态知识快照上研究的,如维基百科。然而,世界是动态的,随着时间的推移而演变,模型的知识也会变得过时。为了研究半参数QA模型及其基础参数语言模型(LM)如何自适应不断变化的知识,本文构建了一个新的大规模数据集——StreamingQA,其中包括在特定日期提出的人工撰写和生成的问题,并从14年的时间戳新闻文章中进行回答。每季度对模型进行评估,因为其阅读了预训练中没有看到的新文章。参数模型可以在没有完全重新训练的情况下进行更新,同时避免灾难性遗忘。对于半参数模型来说,在搜索空间中添加新的文章可以快速自适应,然而,具有过时的基础LM的模型比具有重新训练的LM的模型表现差。对于频率较高的命名实体的问题,参数化更新尤其有益。在所述动态世界中,StreamingQA数据集能够对QA模型进行更真实的评估。
Knowledge and language understanding of models evaluated through question answering (QA) has been usually studied on static snapshots of knowledge, like Wikipedia. However, our world is dynamic, evolves over time, and our models’ knowledge becomes outdated. To study how semiparametric QA models and their underlying parametric language models (LMs) adapt to evolving knowledge, we construct a new large-scale dataset, StreamingQA, with human written and generated questions asked on a given date, to be answered from 14 years of time-stamped news articles. We evaluate our models quarterly as they read new articles not seen in pre-training. We show that parametric models can be updated without full retraining, while avoiding catastrophic forgetting. For semi-parametric models, adding new articles into the search space allows for rapid adaptation, however, models with an outdated underlying LM under-perform those with a retrained LM. For questions about higher-frequency named entities, parametric updates are particularly beneficial. In our dynamic world, the StreamingQA dataset enables a more realistic evaluation of QA models, and our experiments highlight several promising directions for future research.
https://arxiv.org/abs/2205.11388

另外几篇值得关注的论文:
[LG] A Library for Representing Python Programs as Graphs for Machine Learning
将Python程序表示为机器学习图的库
D Bieber, K Shi, P Maniatis, C Sutton, V Hellendoorn, D Johnson, D Tarlow
[Google Research & CMU]
https://arxiv.org/abs/2208.07461



[CL] Interactive and Visual Prompt Engineering for Ad-hoc Task Adaptation with Large Language Models
基于大型语言模型的Ad-hoc任务自适应交互式视觉提示工程
H Strobelt, A Webson, V Sanh...
[IBM Research & Brown University & Huggingface & Harvard SEAS & Cornell Tech]
https://arxiv.org/abs/2208.07852



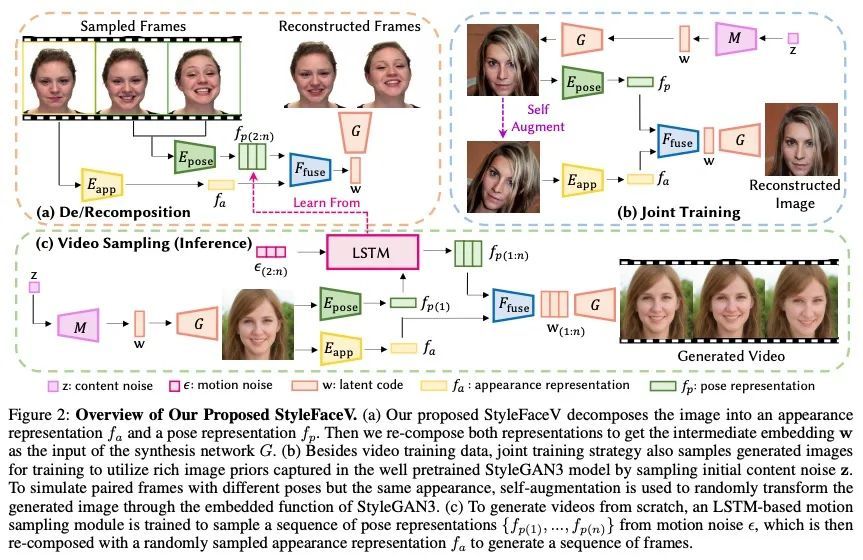
[CV] StyleFaceV: Face Video Generation via Decomposing and Recomposing Pretrained StyleGAN3
StyleFaceV:基于预训练StyleGAN3分解重组的人脸视频生成
H Qiu, Y Jiang, H Zhou...
[Nanyang Technological University & The Chinese University of Hong Kong & SenseTime Research]
https://arxiv.org/abs/2208.07862



[LG] Easy Differentially Private Linear Regression
简单差分隐私线性回归
K Amin, M Joseph, M Ribero, S Vassilvitskii
[Google]
https://arxiv.org/abs/2208.07353

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢