

论文链接:
https://arxiv.org/pdf/2207.12572.pdf
代码链接:
https://github.com/Relento/lego_release
项目主页:
https://cs.stanford.edu/~rcwang/projects/lego_manual/
相信大家都有过按照纸质说明书一步一步组装机器或其他手工品的经历,例如乐高积木,在这个组装过程中,我们需要认真阅读说明书上的每一步,并且具备一定的空间想象能力,才能将2D的操作指引应用到实际的3D物件上,尽管这样,还是会遇见零件组装错误或压根找不到当前零件应该装到哪的情况。这有可能是因为人类视觉系统的一些视觉错觉导致的,尤其是在二维空间到三维空间进行转换时。
最近来自斯坦福大学,麻省理工学院和谷歌研究院的一项工作尝试使用人工智能工具将二维说明书直接映射成三维动画,使组装过程更加清晰明了。为了获得动态的组装过程,本文作者尝试将问题转换为一个序列预测任务,在模型预测的每一步都先将二维的平面指示与当前的3D模型进行匹配,并提出了一个可执行的计划网络(MEPNet)来将一系列的二维操作图像转换为机器可识别的操作码,随后生成3D的操作动画。
此外,由于序列任务本身的可预测性,使得训练出来的模型天然具有良好的泛化能力,可以很好的适应复杂多样的零件。作者也不仅仅局限在乐高积木等领域,认为本文方法也可以迁移到其他复杂类型的产品安装说明书上,这样更具有使用价值,下面是使用本文方法演示组装一把乐高吉他的示例。
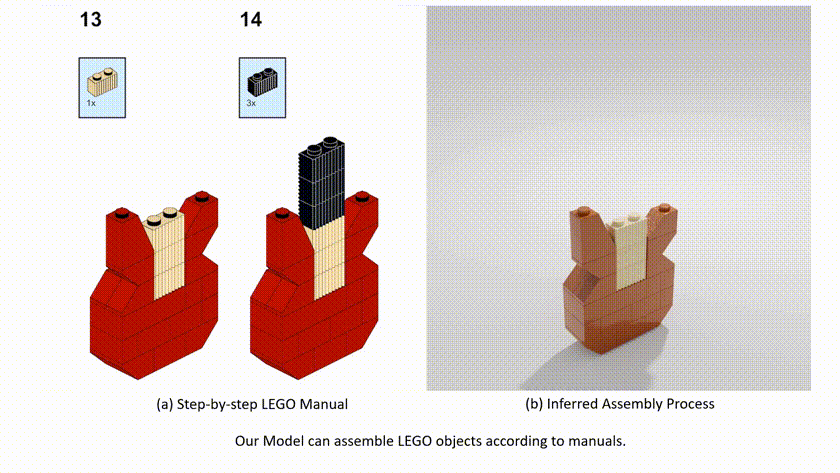
1. 本文方法
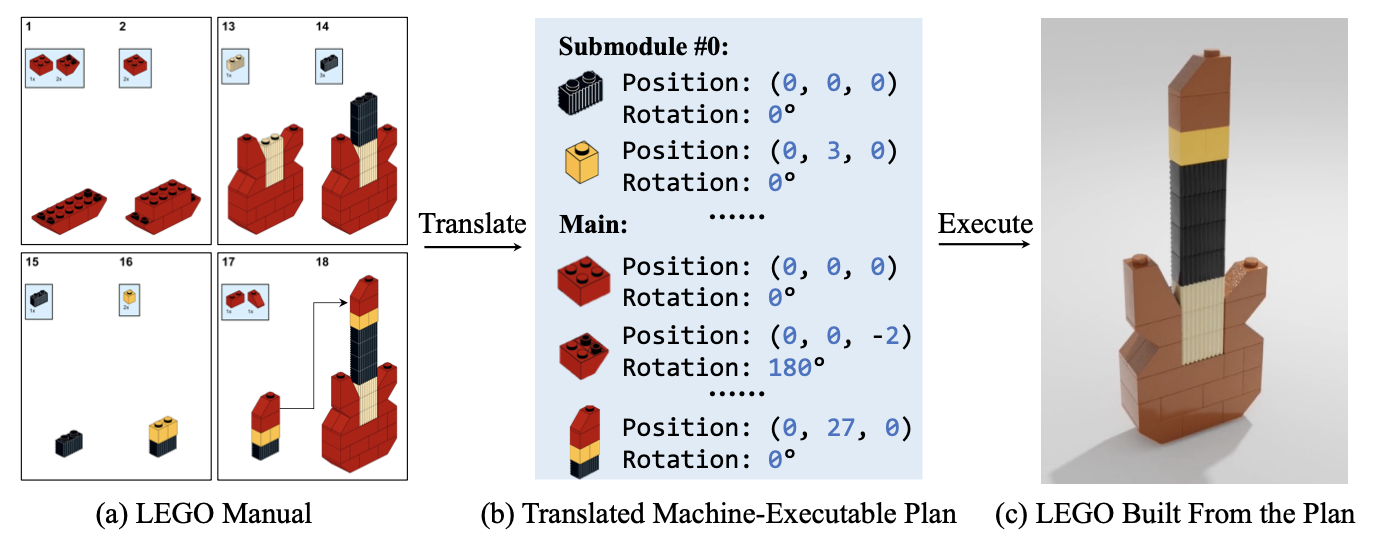
对于工程化组装,小到机密仪器组装,以及本文所关注的乐高积木拼装,大到家具和大型机械的组装任务,都离不开一个详细的操作说明书,而这些说明书往往是由专业的设计人员构建的,他们会将复杂的安装流程分解开来构成一个精简的顺序操作步骤,而本文方法恰好与这一过程相反,即从操作步骤的静态图像出发,从中解析出每一步所需的零件,并将每一个零件安装所需的位置、角度信息进行编码,随后送入模型中进行3D动画推理。如下图展示了本文方法制作乐高吉他动态演示的操作流程,第一步是对2D图像进行编码,目的是为了提取其中每个组件的位置和操作角度,随后将其转换为机器可识别的执行序列。这其中主要涉及到两个技术难点:
- 由于每幅2D图像都是对应3D构件的投影,因此模型需要构建起2D图像到3D模型的精确映射,在映射过程中模型会推理每个构件的3D调整角度,同时还要考虑组件之间的遮挡情况。
- 第二个挑战是零件组合的多样性,以乐高积木为例,虽然大多数乐高模型的组件类型都是有限的,但是这些组件可以灵活的构成多种不同的形状,尤其是将一个细小的零件添加到已经具有雏形的大模型上时,组装的位置会有更多的选择,从而增加了机器理解说明书的难度,这就需要模型具有一定的3D推理能力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢