

论文地址:https://arxiv.org/abs/2207.10741
导读
由于CNN的密集计算特性,在受限资源设备上的部署存在挑战性。本文另辟蹊径,从原始图像输入着手,通过标记任务相关像素来缓解卷积计算压力,并配合本文提出的聚焦卷积来使用标记后的输入图。最后作者等人在嵌入式设备上进行实际测试,在准确率没有损失的情况下,推理延迟、能耗和计算量都减少了约45%。
贡献
卷积具有密集计算的特点,目前的通用矩阵乘法(GEMM)技术将顺序的滑动窗口卷积简化为并行化的矩阵乘法运算,然而GEMM对于低功耗系统来说仍然存在一定挑战。(以ResNet为例,执行一次图像分类,处理参数约3kw)
因此最直接的方法就是对CNN进行处理。如剪枝、量化、知识蒸馏等。通过缩减参数量、计算量来适应低功耗设备,减少其消耗。然而作者等人发现,现有计算机视觉任务,其图像中总是包含与任务无关的像素,而CNN的计算方式则是不加选择的对输入中每一个像素进行操作,这就带来一定的计算压力。
因此出发点来了,如果我们能对原始输入图像进行处理,把图像划分为与任务相关的像素和与任务无关的像素,另外让CNN仅对相关的像素进行计算,是不是就能达到节省计算资源的目的?
什么是与任务无关的像素?比如任务是寻找汽车,图像中包含了汽车和天空,那么天空中的像素就不是很有用。
作者等人通过两种方法来证明上述猜想是可行的:
1.证明三种流行的计算机视觉数据集都包含许多此类像素(相关和无关)。
2.通过使用聚焦卷积删除这些无关像素来达到推理速度改进。
方法
一、输入图像处理——划分相关与不相关
如上所述,想要大幅度缩减计算量,首先需对原始输入图像进行处理,其次配合可以忽略不相关像素的聚焦卷积来实现。
那么划分相关与不相关像素?在本文中,作者等人借助深度图来完成。在深度图中,仅使用一个值来表示图像中的每个像素,该值也被称为像素的深度级别,表示该像素距离相机的距离。
首先对相关像素进行定义:构成数据集的ground truth对象及其相关深度级别的所有像素。如下图1所示,左图ground truth对象为红色区域的巴士,而右侧的阈值图中明显包含了巴士及其周边的一些相关像素。这些额外的相关像素被认为是对模型有帮助的区域,CNN使用这些像素来提取上下文和理解对象特征。

图1:PASCAL VOC数据集图像中不相关像素的示例。
如图2,其具体过程如可以表述如下:
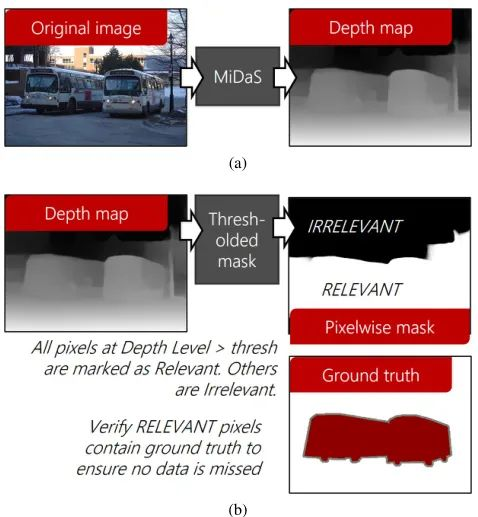
图2:如何计算数据集中不相关像素的数量。
- 首先使用Ranftl等人的深度估计模型“MiDaS”生成深度图。由于该模型预先在不同数据集上进行训练并取得优秀结果,因此MiDaS生成的深度图可以较为准确的表示图像中每个像素的深度级别。
- 其次对深度图进行阈值化处理。因为前文对相关像素的定义是:构成数据集的ground truth对象及其相关深度级别的所有像素。同时相机焦距往往会导致在中等深度水平下拍摄照片,因此仅需设置中间范围的深度来对深度进行阈值化,过滤掉过短或过长的不相关像素,即可初步得到一幅相关与不相关像素的阈值图。
- 最后根据ground truth标签来验证阈值图是否合适。即如果阈值图中的相关像素区包含全部的ground truth标签,那么阈值处理结束,反之则扩大阈值,重新验证。
通过这种方法对原始输入图像完成处理,作者等人对处理结果进行如下统计:
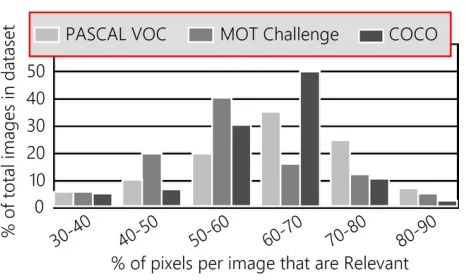
图3:相关像素的平均百分比。
从图中可以看出三个数据集中,按本文方法划分的不相关像素占比是很大的,如果有方法能忽略这些像素,同时保证模型准确率,那么确实可以大大减少推理速度。下面将介绍配合阈值图使用的聚焦卷积。
二、聚焦卷积——不相关像素忽略
聚焦卷积建立在GEMM的基础之上,传统的GEMM将3D输入张量的块转换为2D矩阵的列,然后将矩阵乘以卷积权重以得到卷积结果,其过程如下图所示:
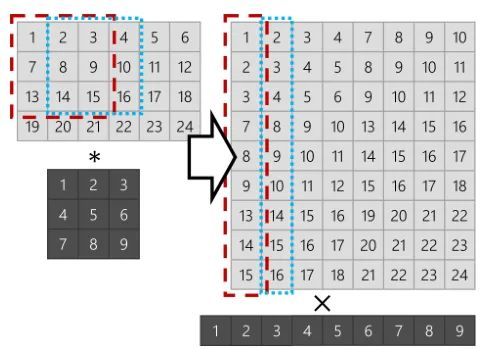
图4:GEMM示意图。
左侧黑色方块代表卷积权重,在右侧展开为行。左侧灰色方块代表输入张量,被标记的红色、蓝色虚线区域代表卷积作用的部分,在右侧展开为列。最终列与行相乘得到卷积结果。
聚焦卷积的计算过程与此类似,但不同的是,聚焦卷积可以识别不相关像素。
如下图所示,如果一块像素被标记为不相关,那么聚焦卷积不会将这块像素转换为列,即不相关像素不参与卷积计算。同时如果聚焦卷积的输入不是阈值图,那么其计算过程与GEMM一致。因此聚焦卷积可以作为一种即插即用的模块,在不更改模型结构、权重以及偏差的情况下进行替换。
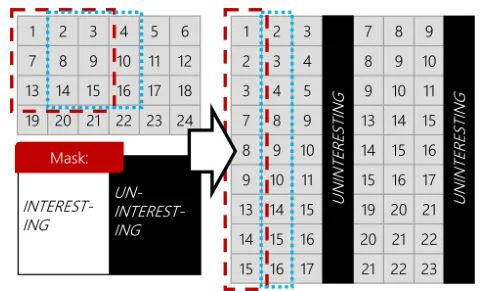
图5:聚焦卷积示意图。
实验
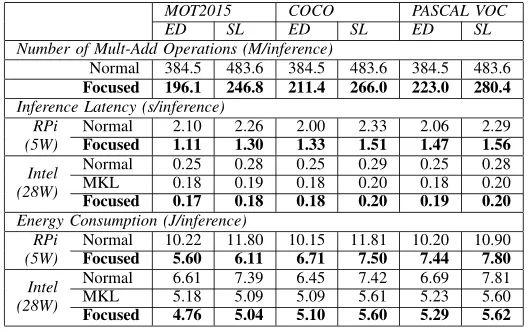
表1:MOTChallenge, COCO, PASCAL VOC的性能对比结果。
如表1所示,作者等人在功率为5W的Raspberry Pi 3(RPi)和功率为28W的Intel Core i7 CPU上进行性能测试,对比模型为轻量级的EfficientDet(ED)和SSD-Lite(SL),对比卷积方法为正常卷积(Normal)、使用 Intel MKL 优化卷积(MKL)以及本文的聚焦卷积(Focused)。
从结果可以看出本文方法对模型性能提升了很多,而且即插即用更为灵活。
本文另辟蹊径,从原始输入图像着手,配合聚焦卷积实现了线性的计算优化。然而本文方法仅在三个数据集(MOTChallenge, COCO, PASCAL VOC)上进行性能测试,在实际场景中可能包含一些广角照片、风景照片,这些照片的主要对象可能并不适用于中间范围深度,因此对本文方法来说可能存在一定的应用挑战。另外对原始输入图像进行深度图转换的操作,包括后续的阈值化处理和不断记录像素数量的重复过程,是否考虑进成本计算。
尽管本文方法存在一些不足,但对于不相关像素的思想值得学习,类似的工作还有“SBNet: Sparse Blocks Network for Fast Inference”,感兴趣的朋友可以自行阅读。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢