
【中科院信工所团队】用于基于知识的视觉问答系统的跨模态知识推理
【论文标题】Cross-Modal Knowledge Reasoning for Knowledge-based Visual Question Answering
【作者团队】Jing Yu,Zihao Zhu,Yujing Wang,Weifeng Zhang,Yue Hu,Jianlong Tan
【发表时间】2020/09/02
【论文链接】https://arxiv.org/abs/2009.00145
【代码链接】https://github.com/astro-zihao/mucko
【推荐理由】
本文发表于模式识别(PR)期刊(中科院 1 区)。
将外部知识引入机器学习系统是当下越来越受到研究者们重视的研究方向。除了可见的内容,基于知识的视觉问答系统(KVQA)还需要的外部知识,从而回答有关某张图像的问题。尽管极具挑战,但是这种能力对于实现通用的视觉问答系统是必不可少的。 现有的 KVQA 解决方案的不足之处之一是:它们在没有进行细粒度选择的情况下联合嵌入了各种信息,这为推理出正确的答案带来了一些意料之外的干扰。如何捕捉以问题为导向和信息互补的证据,是解决这一问题的关键。本文受人类认知理论的启发,本文从视觉、语义和事实三个角度,用多个知识图谱来描述图像。其中,视觉图和语义图被认为是事实图谱以图像为条件的实例。在这些新的表征形式的基础之上,我们重新将基于知识的视觉问答定义为了一个循环推理过程,从而从多模态信息中获得作为补充的依据。为此,我们将模型分解为一系列基于记忆的推理步骤,每个步骤都是由一个基于图的读取、更新和控制(GRUC)模块执行,该模块可以并行地对视觉和语义信息进行推理。该模型通过多次堆叠 GRUC 模块进行传递性推理,得到在不同模态约束下面向问题的概念表征。最终,我们通过联合地考虑全部的概念,运行图神经网络推断出全局最优的答案。我们在三个流行的对比基准测试数据集(FVQA、Visual7W-KB 以及 OK-VQA)上取得了目前最优的性能,并且通过丰富的实验证明了我们模型的有效性和可解释性。
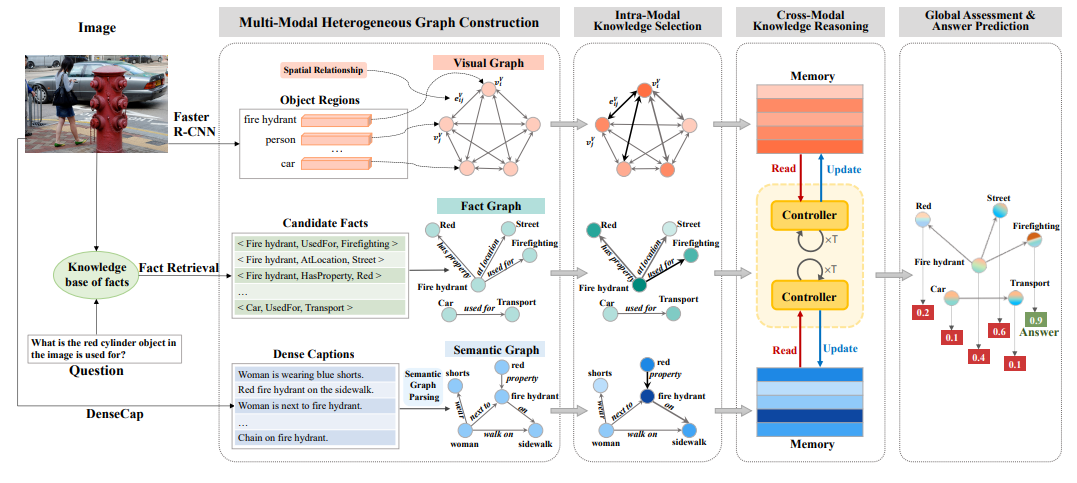
本文主要的贡献如下: (1)本文利用视觉、语义和事实三种知识图谱描述了多模态知识源,统一了图域中不同形式的表征,有利于结构的保存和关系推理。 (2)本文提出了一种循环推理模型,其三个显著的创新之处为:首先,它是一个并行推理模型,以并行方式将面向模态的控制器用于不同模态的推理,可以很容易地扩展到更多模态上;其次,我们的模型被设计用来在图结构的多模态数据上进行推理,旨在在推理过程中考虑本质的结构信息;第三,基础的推理模块 GRUC 是一个模块化的架构,由读取单元、更新单元和控制单元组成,支持更显式、结构化的推理。 (3)该模型在三个对比基准数据集(FVQA、Visual7W-KB 和 OK-VQA)上的性能显著优于目前最先进的方法。 (4)该模型有很好的可解释性。在图融合的过程中,我们的模型通过将 GRUC 模块中的注意力权值和门控值可视化,自动判断哪个实体域模态对回答问题有更大的贡献。同时,该模型还可以根据问题的复杂程度,从不同的模态揭示知识选择模式。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢