
论文题目:Learn2Sing 2.0: Diffusion and Mutual Information-Based Target Speaker SVS by Learning from Singing Teacher
论文链接:https://arxiv.org/abs/2203.16408
Demo&Code: https://welkinyang.github.io/Learn2Sing2.0
本文提出了一种基于扩散模型 (Diffusion Model) 和互信息 (Mutual Information, MI) 的SVS方法 Learn2Sing 2.0。与Learn2Sing 1.0类似,Learn2Sing 2.0也是通过向歌唱老师学习,为目标说话人生成高表现力的歌唱语音。不同的是,Learn2Sing 2.0首先生成一个被不同说话人共享的中间表征,例如,有/无歌唱语料库的说话人,然后用额外的风格信息,即说话或歌唱,恢复最终的目标特征。也就是说,这个中间特征需要抹平不同风格之间的差异,然后基于这个中间特征,解码器根据特定的风格来还原最终的目标特征。而因为音高是区分说话和歌唱的关键风格因素,为此我们选择了音素级的mel-spectrogram(音素内部的音高是被平均的)来作为这种中间特征。得到中间特征后,解码器负责将中间特征根据相应的风格信息还原最终的目标特征。因为扩散模型具有强大建模能力,可以避免由L1/L2损失函数造成的过平滑问题,所以我们选择了基于分数的Diffusion解码器来逐步的还原目标特征。由于每个说话人都对应着一种特定的风格,即说话或唱歌,因此有必要确保说话人的嵌入是独立于风格的,反之亦然。为此,我们使用了MI来实现说话人和风格的解耦。
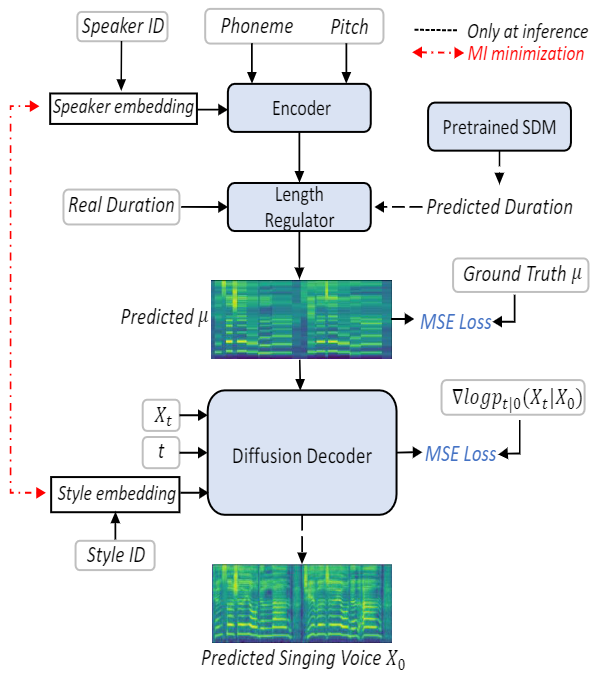
图4 Learn2Sing2.0的训练和推理过程
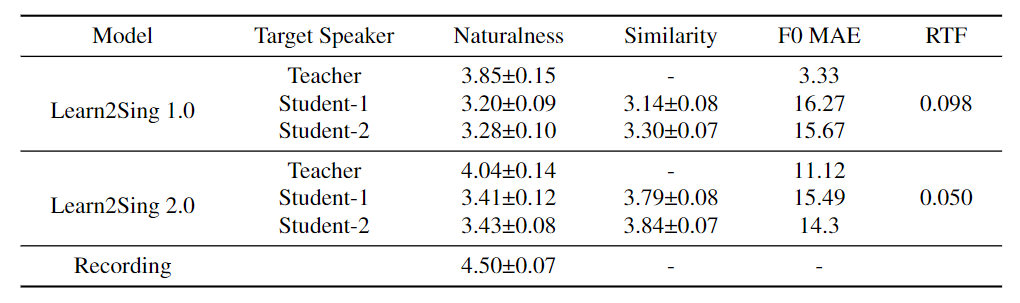
表1 95%置信区间的MOS的实验结果,F0 MAE和RTF的实验结果
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢