
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:黎曼扩散模型、超图因果效应学习、非收敛学习算法泛化问题研究、基于多样位置感知注意力的长文档理解、基于交互式绘画的渐进式图像合成与编辑、智能体因果发现算法、用基于分数的扩散近似退火重要性采样(AIS)、基于梯度方差裁剪的二元潜变量梯度估计、具有任务相关性和跨模态显著性教学视频摘要
1、[LG] Riemannian Diffusion Models
C Huang, M Aghajohari, A J Bose, P Panangaden, A Courville
[University of Montreal & McGill University & Mila]
黎曼扩散模型。扩散模型是近期用于图像生成和似然估计的最先进方法。本文将连续时间扩散模型推广到任意黎曼流形RDM——包括挑战性的非紧凑流形,如双曲空间,并推导出一个似然估计的变分框架,通过优化一个新目标,即黎曼连续时间ELBO来训练RDM。为了实现高效和稳定的训练,本文提供了几个关键工具,如环境空间中SDE的固定推理参数化,计算黎曼扩散的新方法,以及针对时间积分的重要性采样程序,以减少损失的方差。理论方面,通过构建边际等价SDE,展示了所提出的变分框架和黎曼分数匹配之间的深刻联系。通过构建RDM来补充所提出理论,这些RDM在地球科学数据集的密度估计、环形的蛋白质/RNA数据以及双曲和正交组流形的合成数据上取得了最先进的性能。
Diffusion models are recent state-of-the-art methods for image generation and likelihood estimation. In this work, we generalize continuous-time diffusion models to arbitrary Riemannian manifolds and derive a variational framework for likelihood estimation. Computationally, we propose new methods for computing the Riemannian divergence which is needed in the likelihood estimation. Moreover, in generalizing the Euclidean case, we prove that maximizing this variational lower-bound is equivalent to Riemannian score matching. Empirically, we demonstrate the expressive power of Riemannian diffusion models on a wide spectrum of smooth manifolds, such as spheres, tori, hyperboloids, and orthogonal groups. Our proposed method achieves new state-of-the-art likelihoods on all benchmarks.
https://arxiv.org/abs/2208.07949

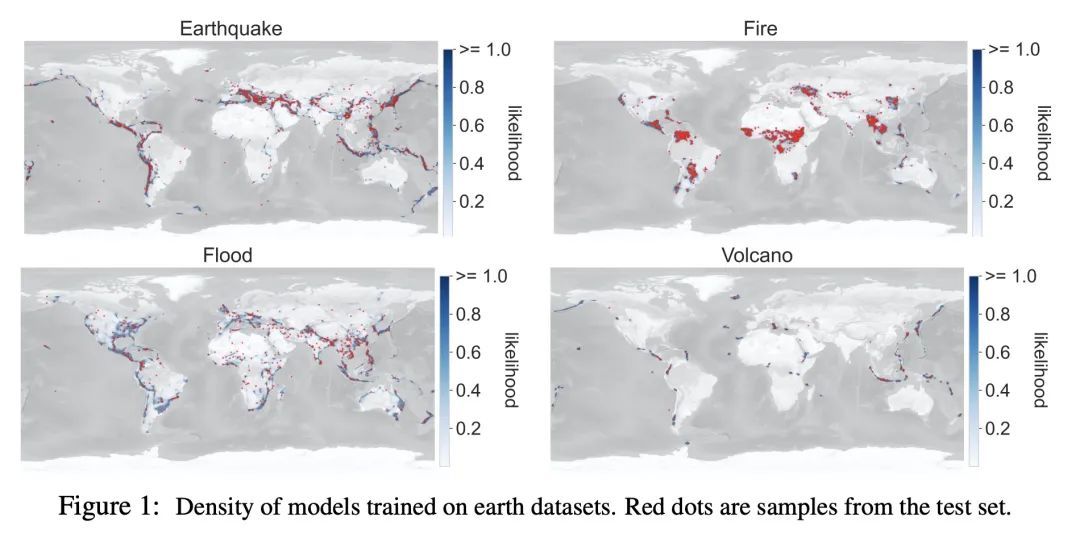
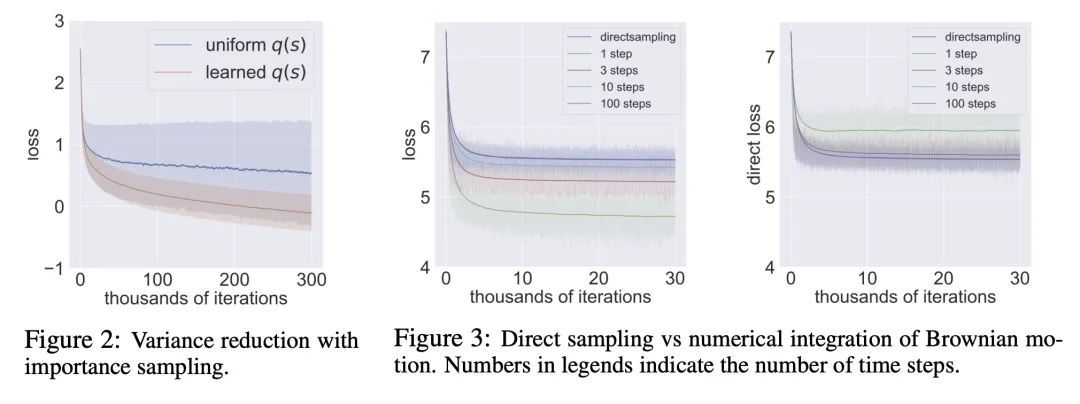
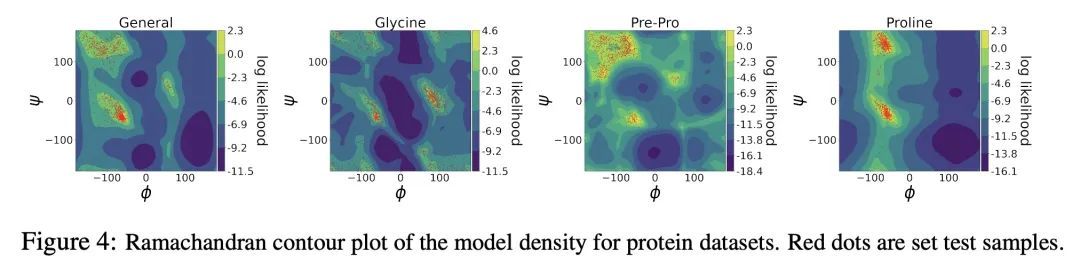
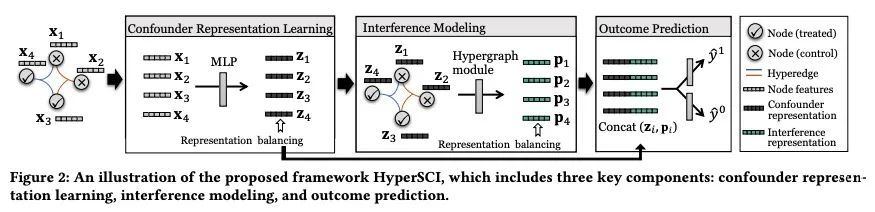
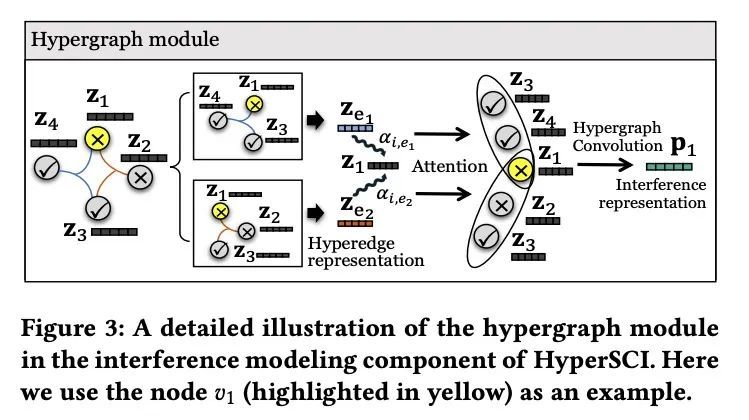
2、[LG] Learning Causal Effects on Hypergraphs
J Ma, M Wan, L Yang, J Li, B Hecht, J Teevan
[University of Virginia & Microsoft]
超图因果效应学习。超图为建模节点间的多向群体交互提供了有效的抽象,其中每个超图可以连接任意数量的节点。与大多数现有研究不同,本文从因果关系的角度研究超图。具体来说,本文专注于超图上个体治疗效果(ITE)估计问题,旨在估计一项干预措施(如戴口罩)会对每个个体节点的结果(如COVID-19感染)产生多大的因果关系。现有的关于ITE估计的工作要么假设一个人的结果不应受到其他个体的治疗分配的影响(即没有干扰),要么假设干扰只存在于普通图中的连接个体对之间。本文认为,这些假设在现实世界的超图上可能是不现实的,由于群体交互的存在,高阶干扰会影响最终的ITE估计。本文研究了高阶干扰建模,并提出一种由超图神经网络驱动的新因果关系学习框架。在真实世界的超图上进行的广泛实验,验证了所提出框架比现有基线的优越性。
Hypergraphs provide an effective abstraction for modeling multiway group interactions among nodes, where each hyperedge can connect any number of nodes. Different from most existing studies which leverage statistical dependencies, we study hypergraphs from the perspective of causality. Specifically, in this paper, we focus on the problem of individual treatment effect (ITE) estimation on hypergraphs, aiming to estimate how much an intervention (e.g., wearing face covering) would causally affect an outcome (e.g., COVID-19 infection) of each individual node. Existing works on ITE estimation either assume that the outcome on one individual should not be influenced by the treatment assignments on other individuals (i.e., no interference), or assume the interference only exists between pairs of connected individuals in an ordinary graph. We argue that these assumptions can be unrealistic on real-world hypergraphs, where higher-order interference can affect the ultimate ITE estimations due to the presence of group interactions. In this work, we investigate high-order interference modeling, and propose a new causality learning framework powered by hypergraph neural networks. Extensive experiments on real-world hypergraphs verify the superiority of our framework over existing baselines. CCS CONCEPTS •Mathematics of computing→Causal networks;Hypergraphs; • Information systems→ Social networks.
https://arxiv.org/abs/2207.04049

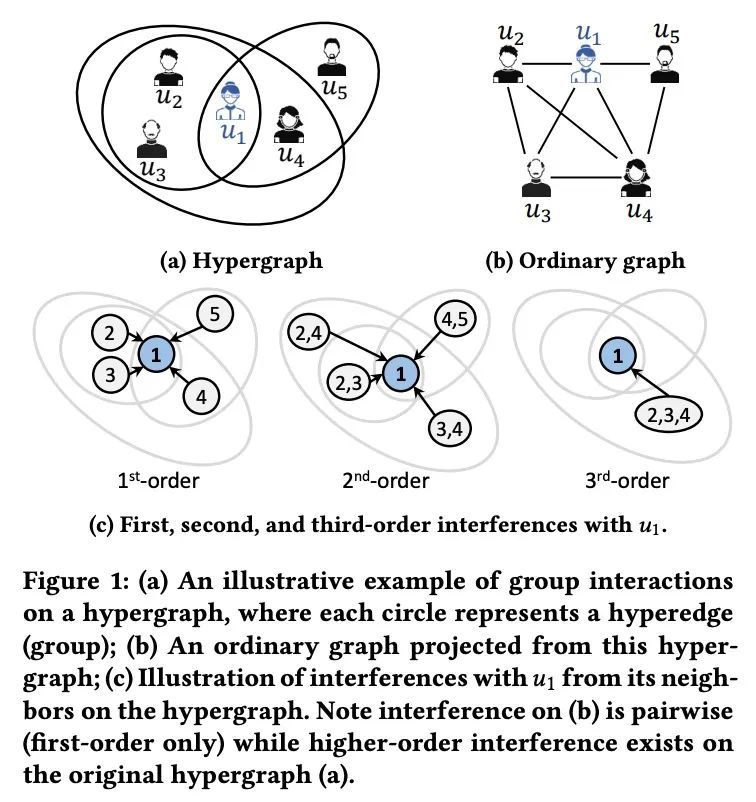
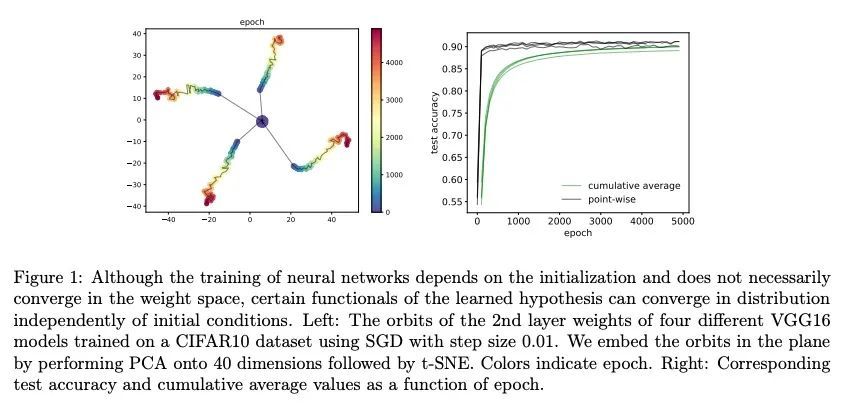
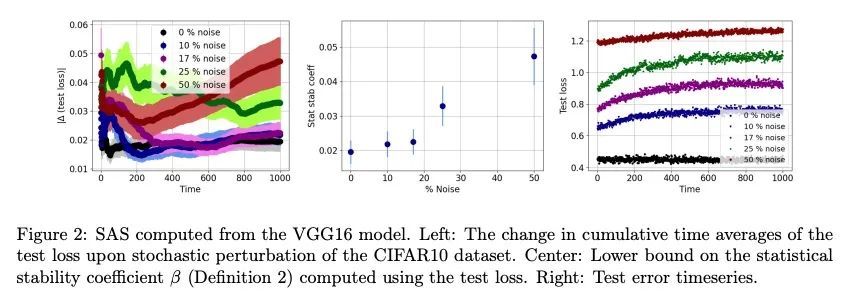
3、[LG] On the generalization of learning algorithms that do not converge
N Chandramoorthy, A Loukas, K Gatmiry, S Jegelka
[MIT & Roche]
非收敛学习算法泛化问题研究。深度学习的泛化分析,通常假定训练会收敛到一个固定点。但是,最近的结果表明,在实践中,用随机梯度下降法优化的深度神经网络的权重,往往会无限振荡下去。为减少理论与实践之间的这种差异,本文重点讨论了训练动态不一定收敛到固定点的神经网络的泛化问题。本文的主要贡献,是提出了一个统计算法稳定性(SAS)的概念,将经典的算法稳定性扩展到非收敛算法,并研究其与泛化的联系。与传统的优化和学习理论的观点相比,这种遍历理论的方法带来了新的见解。本文证明了一个学习算法的时间渐进行为的稳定性与它的泛化有关,并从经验上证明了损失动力学如何提供泛化性能的线索。本文的发现提供了证据,证明网络"稳定训练泛化效果更好",即使训练无限继续且权重不收敛。
Generalization analyses of deep learning typically assume that the training converges to a fixed point. But, recent results indicate that in practice, the weights of deep neural networks optimized with stochastic gradient descent often oscillate indefinitely. To reduce this discrepancy between theory and practice, this paper focuses on the generalization of neural networks whose training dynamics do not necessarily converge to fixed points. Our main contribution is to propose a notion of statistical algorithmic stability (SAS) that extends classical algorithmic stability to non-convergent algorithms and to study its connection to generalization. This ergodic-theoretic approach leads to new insights when compared to the traditional optimization and learning theory perspectives. We prove that the stability of the time-asymptotic behavior of a learning algorithm relates to its generalization and empirically demonstrate how loss dynamics can provide clues to generalization performance. Our findings provide evidence that networks that “train stably generalize better” even when the training continues indefinitely and the weights do not converge.
https://arxiv.org/abs/2208.07951


4、[CL] Understanding Long Documents with Different Position-Aware Attentions
H Pham, G Wang, Y Lu, D Florencio, C Zhang
[CMU & Microsoft Azure AI]
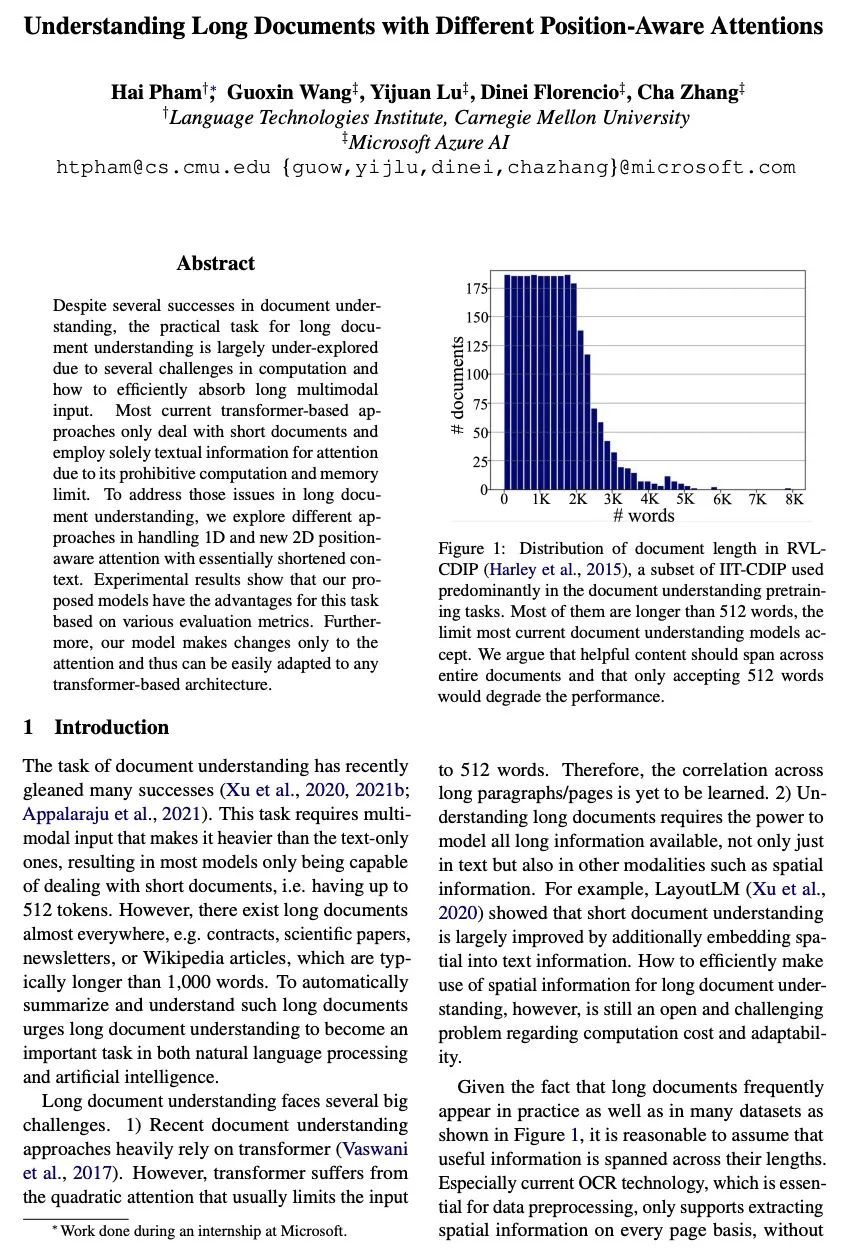
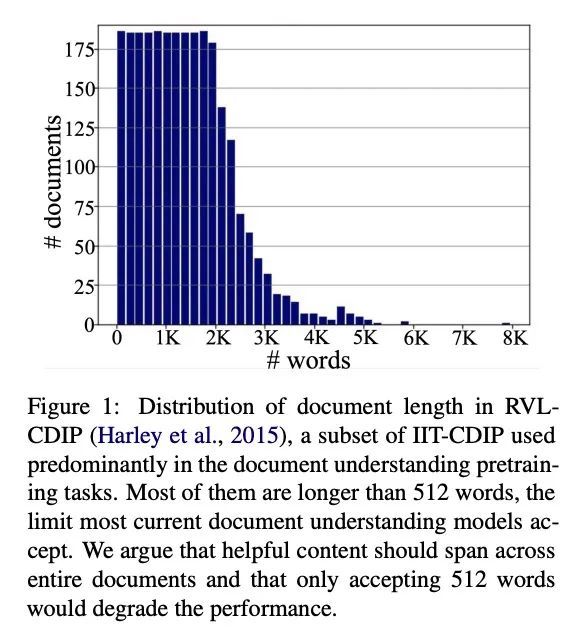
基于多样位置感知注意力的长文档理解。尽管在文档理解方面取得了一些成功,但由于在计算和如何有效地吸收长的多模态输入方面的一些挑战,长文档理解的实际任务在很大程度上还没有被探索。目前大多数基于Transformer的方法只处理短文档,并且由于其计算和内存限制,只采用文本信息来计算注意力。为了解决长文档理解中的这些问题,本文在处理1D和新的2D位置感知注意力方面探索了不同的方法,缩短了其上下文。实验结果表明,根据各种评价指标,所提出的模型在这项任务中具有优势。此外,所提模型只对注意力做了改变,因此可以很容易地适应于任何基于Transformer的架构。
Despite several successes in document understanding, the practical task for long document understanding is largely under-explored due to several challenges in computation and how to efficiently absorb long multimodal input. Most current transformer-based approaches only deal with short documents and employ solely textual information for attention due to its prohibitive computation and memory limit. To address those issues in long document understanding, we explore different approaches in handling 1D and new 2D positionaware attention with essentially shortened context. Experimental results show that our proposed models have the advantages for this task based on various evaluation metrics. Furthermore, our model makes changes only to the attention and thus can be easily adapted to any transformer-based architecture.
https://arxiv.org/abs/2208.08201

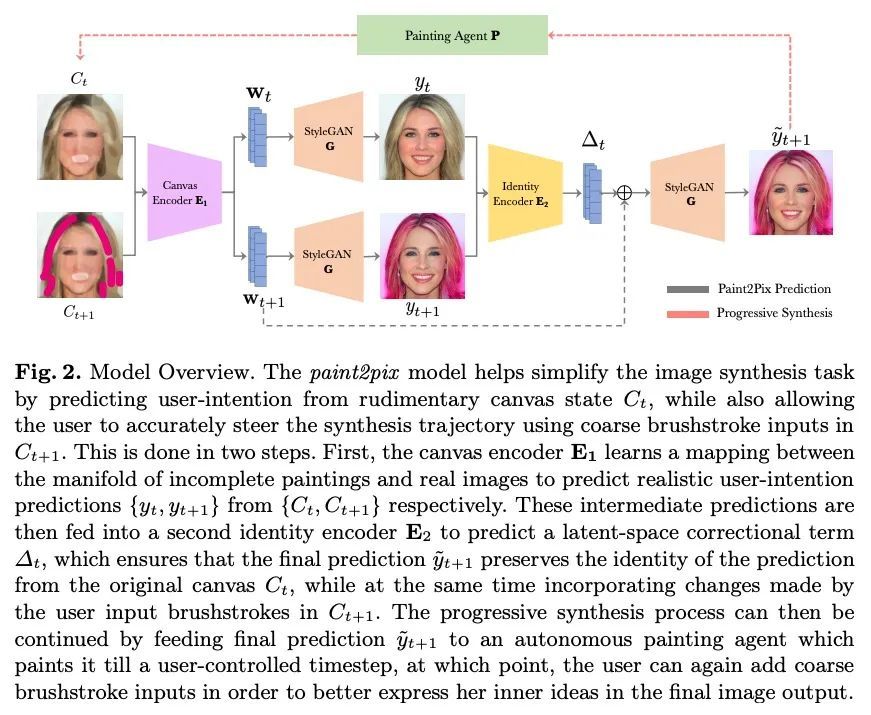
5、[CV] Paint2Pix: Interactive Painting based Progressive Image Synthesis and Editing
J Singh, L Zheng, C Smith, J Echevarria
[Adobe Research & Australian National University]
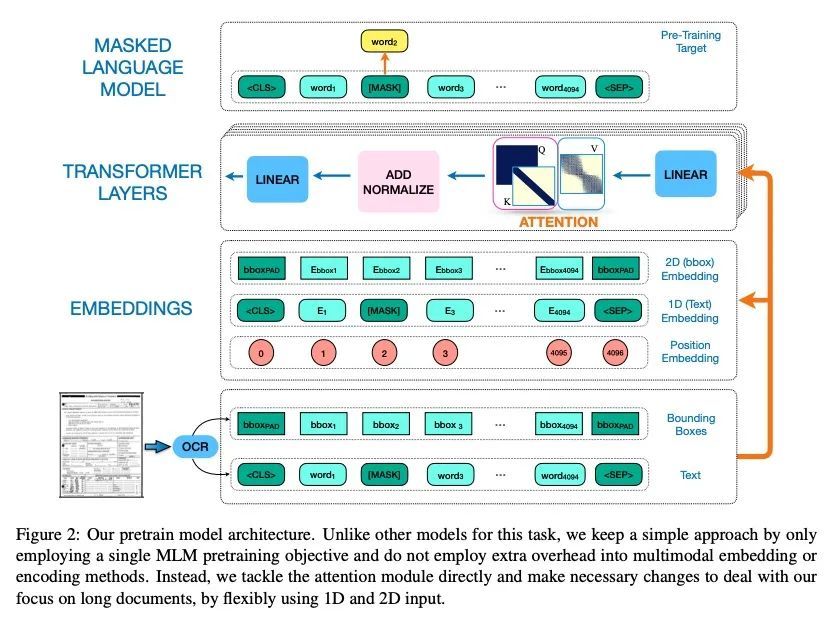
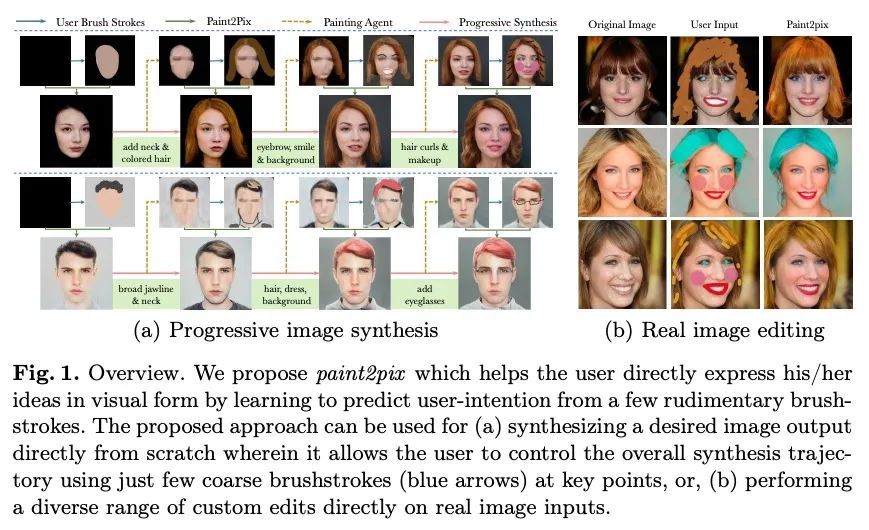
Paint2Pix: 基于交互式绘画的渐进式图像合成与编辑。利用用户的涂鸦进行可控的图像合成,是计算机视觉界非常感兴趣的一个话题。本文首次研究了从不完整和原始的人类绘画中合成逼真图像的问题。特别的,提出一种新方法paint2pix,通过学习从不完整的人类绘画的流形到其现实渲染的映射,来预测(和自适应)"用户想画什么"。当与最近在自主绘画智能体方面的工作结合使用时,paint2pix可以用于从头开始的渐进式图像合成。在此过程中,paint2pix允许新手逐步合成所需的图像输出,而只需少数粗略的用户涂鸦来准确地引导合成过程的轨迹。此外,所提出方法也为真正的图像编辑提供了惊人的便利,允许用户通过添加一些位置良好的笔触来进行各种自定义的细粒度编辑。
Controllable image synthesis with user scribbles is a topic of keen interest in the computer vision community. In this paper, for the first time we study the problem of photorealistic image synthesis from incomplete and primitive human paintings. In particular, we propose a novel approach paint2pix, which learns to predict (and adapt) “what a user wants to draw” from rudimentary brushstroke inputs, by learning a mapping from the manifold of incomplete human paintings to their realistic renderings. When used in conjunction with recent works in autonomous painting agents, we show that paint2pix can be used for progressive image synthesis from scratch. During this process, paint2pix allows a novice user to progressively synthesize the desired image output, while requiring just few coarse user scribbles to accurately steer the trajectory of the synthesis process. Furthermore, we find that our approach also forms a surprisingly convenient approach for real image editing, and allows the user to perform a diverse range of custom fine-grained edits through the addition of only a few well-placed brushstrokes. Source code and demo is available at https://github.com/1jsingh/paint2pix.
https://arxiv.org/abs/2208.08092


另外几篇值得关注的论文:
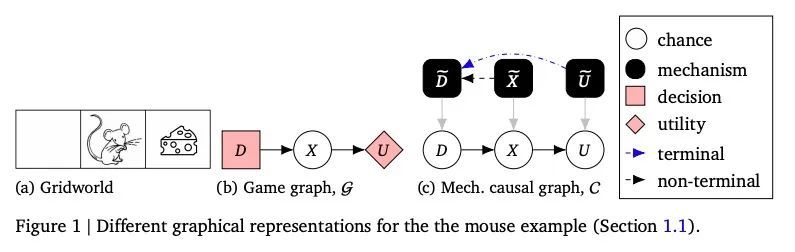
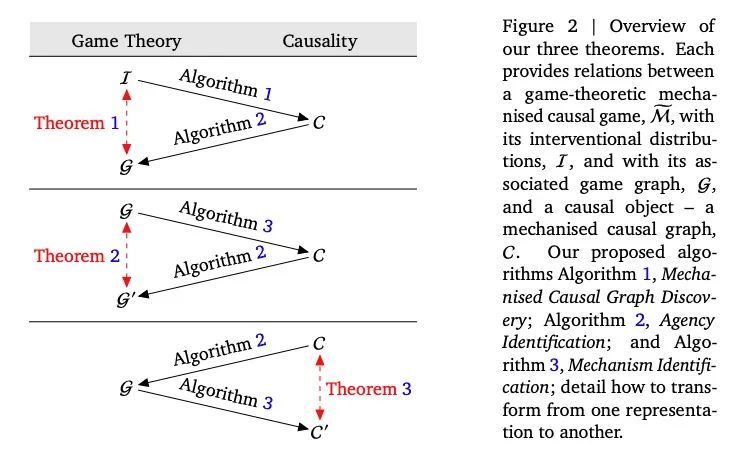
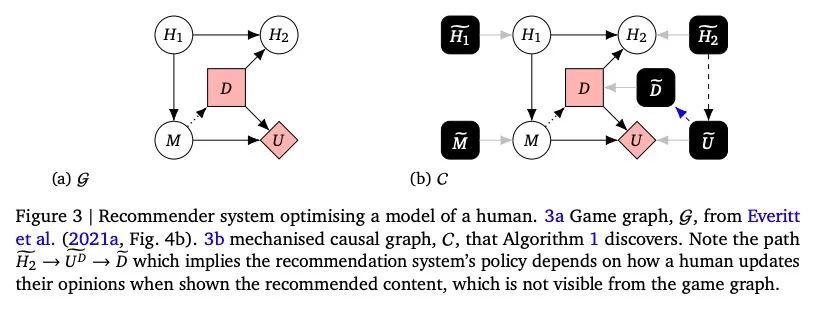
[LG] Discovering Agents
智能体因果发现算法
Z Kenton, R Kumar, S Farquhar, J Richens, M MacDermott, T Everitt
[DeepMind & University of Oxford & Imperial College London]
https://arxiv.org/abs/2208.08345

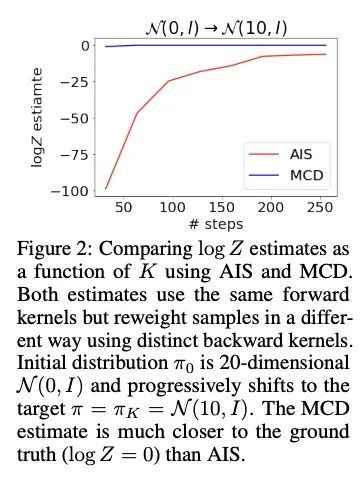
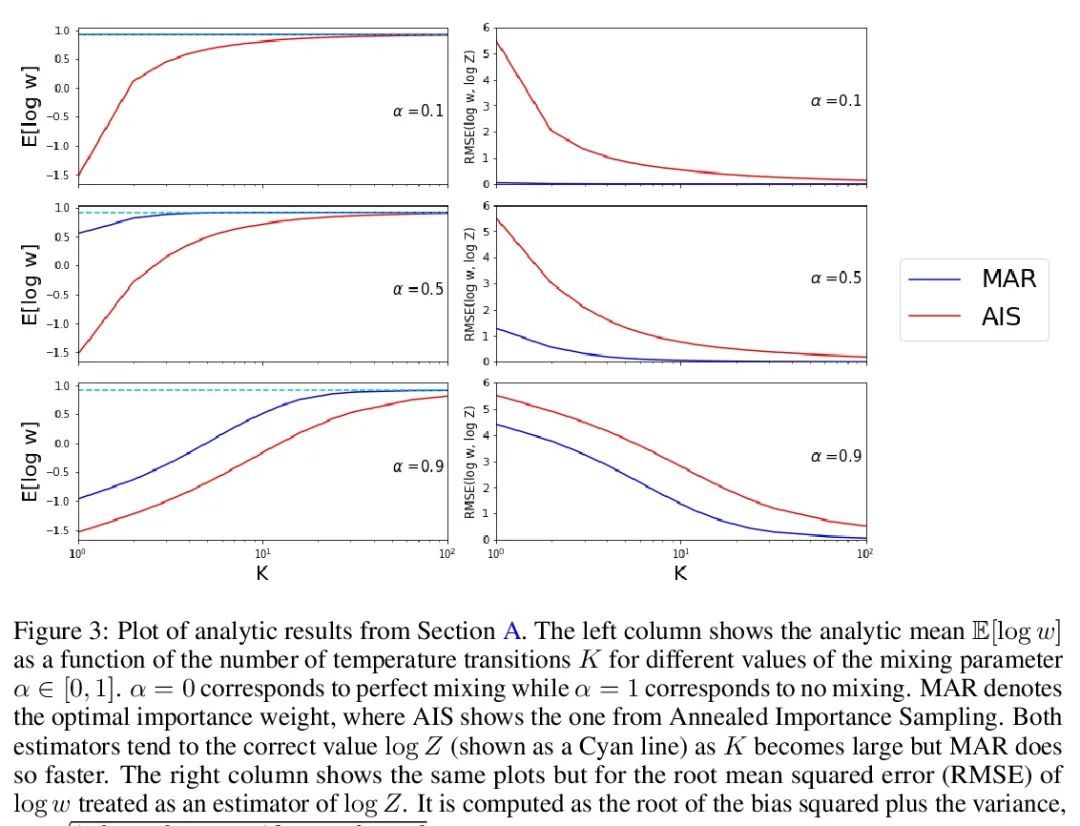
[LG] Score-Based Diffusion meets Annealed Importance Sampling
用基于分数的扩散近似退火重要性采样(AIS)
A Doucet, W Grathwohl, A G. D. G. Matthews, H Strathmann
[DeepMind]
https://arxiv.org/abs/2208.07698


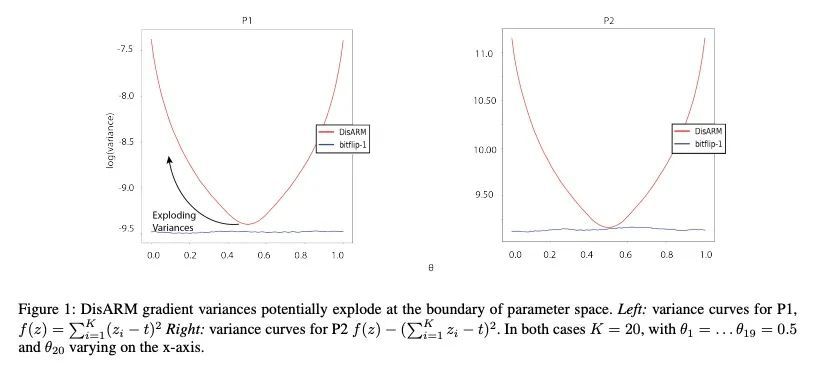
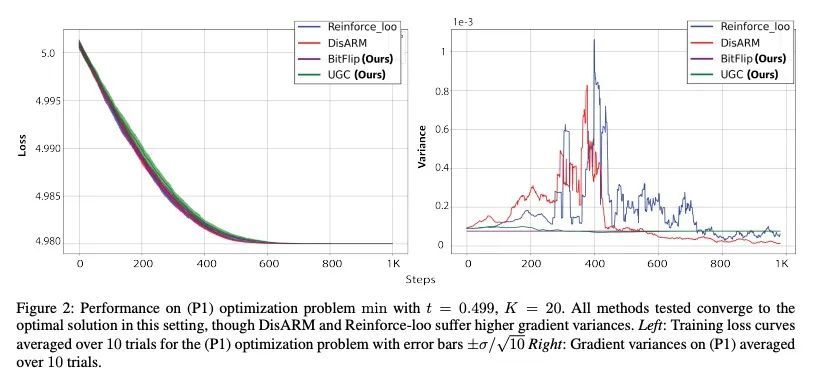
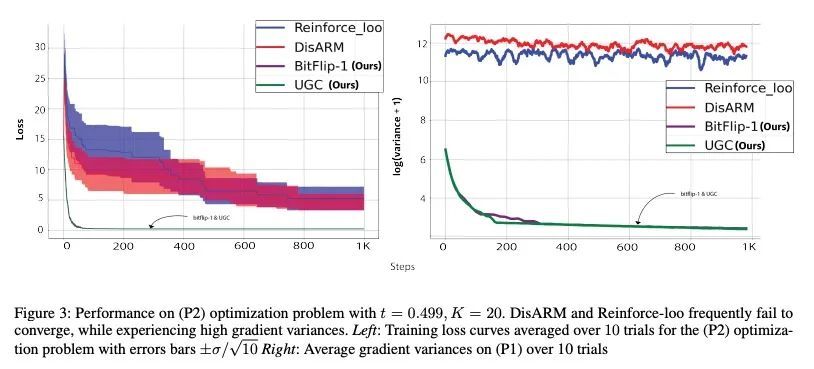
[LG] Gradient Estimation for Binary Latent Variables via Gradient Variance Clipping
基于梯度方差裁剪的二元潜变量梯度估计
R Z. Kunes, M Yin, M Land, D Haviv, D Pe'er, S Tavaré
[Columbia University & Memorial Sloan Kettering Cancer Center]
https://arxiv.org/abs/2208.06124

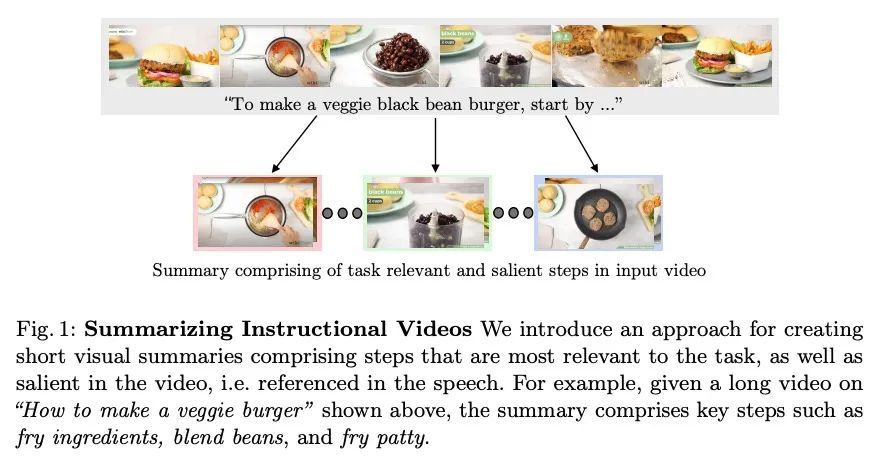
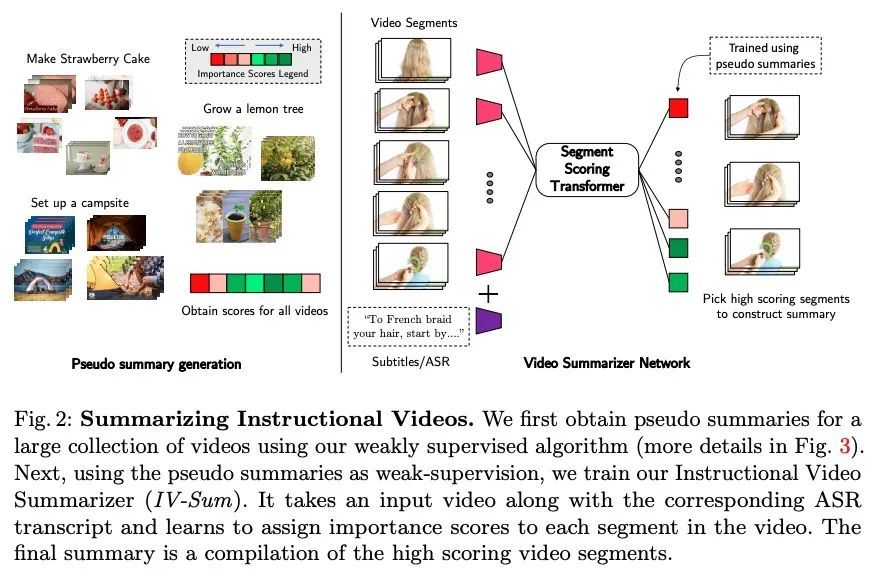
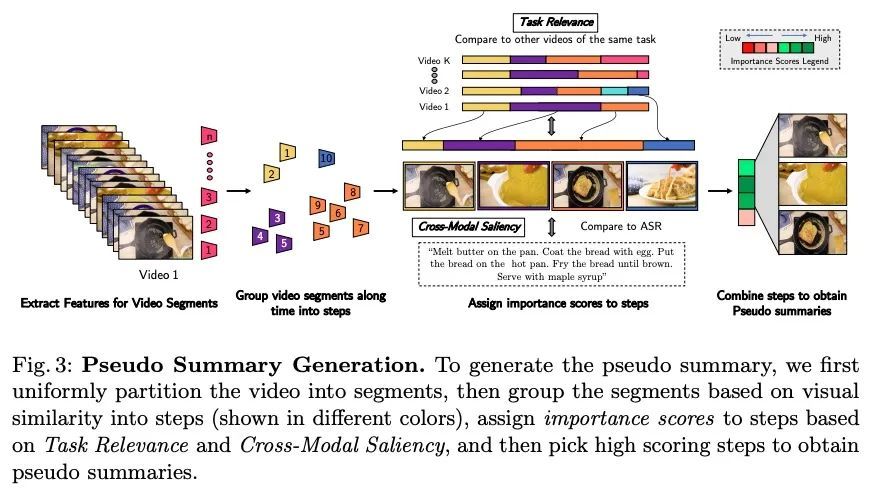
[CV] TL;DW? Summarizing Instructional Videos with Task Relevance & Cross-Modal Saliency
具有任务相关性和跨模态显著性教学视频摘要
M Narasimhan, A Nagrani, C Sun, M Rubinstein, T Darrell, A Rohrbach, C Schmid
[UC Berkeley & Google Research]
https://arxiv.org/abs/2208.06773

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢