

随着深度学习的快速发展,神经网络模型在CV、NLP等很多领域已经取得了显著超越传统模型的效果。然而,在信息检索领域,神经网络模型的有效性却仍然受到质疑。 例如这两年来,如BERT一样的预训练语言模型在很多自然语言处理的任务上取得了不错的效果,也成为了众多NLP任务的基线模型。然而,在信息检索领域,预训练语言模型在信息检索数据上的表现却并不突出。 那么,神经网络模型在信息检索领域的作用是否被夸大,又该如何有效地将神经网络模型应用于开放域信息检索场景? 基于上述问题,清华大学刘知远联合微软团队不仅提出了基于强化学习的弱监督数据筛选模型(ReInfoSelect)等相应解决方案,而且为了更好地解决开放域信息检索问题,刘知远老师所在的清华大学自然语言处理与社会人文计算实验室于近日开源了开放域信息检索工具包——OpenMatch(基于Python和PyTorch开发),以及神经网络信息检索必读论文集——NeuIRPapers。
信息检索顾名思义,就是根据用户给定的问题,通过模型的搜索返回相关的文档(如下图所示)。整个检索过程大致分为两步:文档检索、文档重排序。
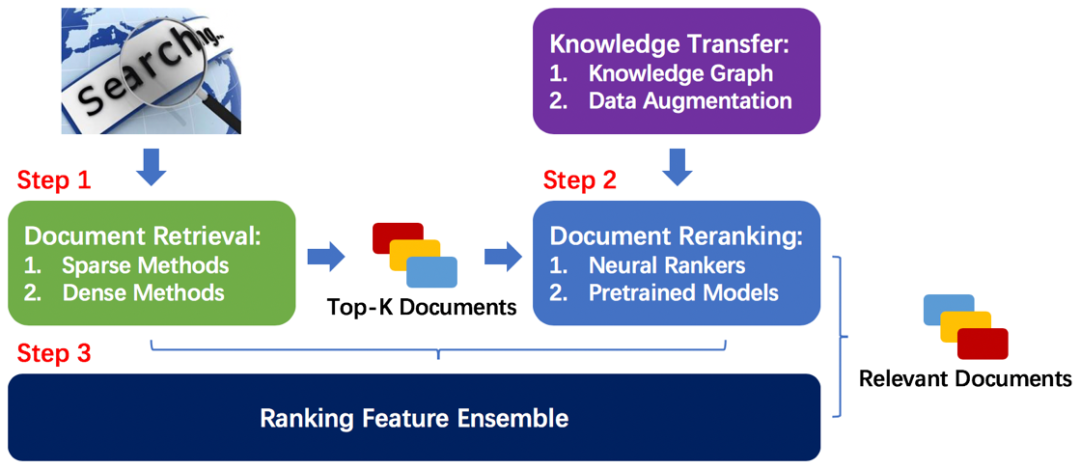
在文档检索中,由于检索规模巨大,且需要保证检索的召回率,因此,我们往往采用两类方法来实现。第一种为Sparse Methods,例如BM25,SDM等基于精确词语匹配的模型;第二种是Dense Methods,例如ANN(Approximate Nearest Neighbor),其基于神经网络得到问题和文档的表示,通过计算二者表示的相似程度来对候选文档进行排序。 对于文档重排序而言,由于只需要对文档检索出来的前K个文档重排序,因此,我们更侧重于检索的精度和效果。 此类模型主要分为两类: 1、基于神经网络的信息检索模型,此种模型主要侧重于通过端到端训练,学习词向量之间的相关性特征,例如K-NRM,Conv-KNRM,TK等。 2、诸如BERT之类的预训练模型,此种模型通过预训练语言模型来增强模型的效果。 最后,我们可以通过Coordinate Ascent或RankSVM来整合两个阶段的全部模型特征,从而提升整体检索的效果。
在本文中,重点介绍第二步,以及如何更好的将领域知识迁移到文档重排序模型中。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢