
本文介绍我们被KDD 2022接收的新工作:DICE: Domain-attack Invariant Causal Learning for Improved Data Privacy Protection and Adversarial Robustness。我们利用因果推断来建模分析和改善了当前攻击和防御算法各自的局限性。

对抗攻击 (adversarial attack) 发生在模型部署阶段,通过对测试集的数据注入恶意的而人眼不可见的噪声,来降低模型在攻击后的测试样本上的表现。虚假攻击 (delusive attack) 则发生在模型训练阶段,可看作数据投毒的一种,通过对训练集的数据进行恶意且不可见的扰动,大大降低模型在干净的测试数据上的表现。其中虚假攻击可以用于数据隐私保护:如果数据拥有者在公开隐私数据前主动对数据进行虚假攻击,可以防止数据被未经授权或者非法使用,因为虚假攻击后的数据对于模型训练是有害的。
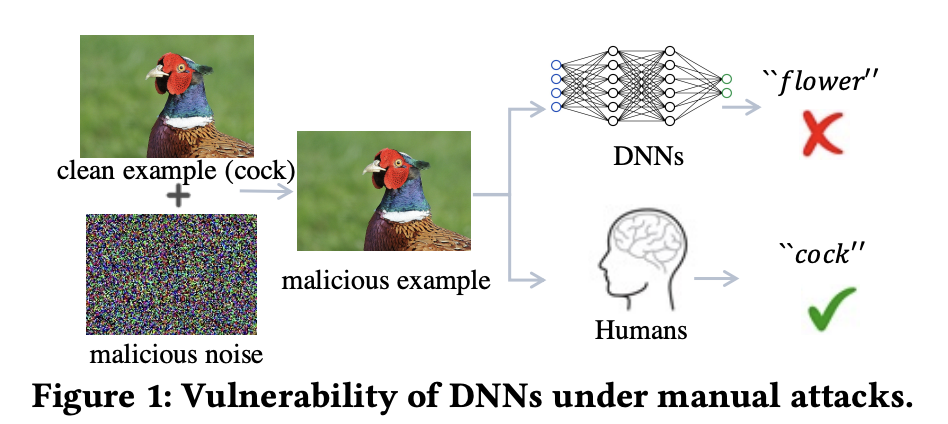
即使两种攻击手段通过造成测试域或者训练域的域偏移 (domain shift)在深度神经网络 (DNNs)上取得了很好的效果,然而它们并不会影响人类判断 (图 1)。对此一种流行的假设是人类认知系统能够捕捉到图像和标签中对域偏移保持不变的因果联系,而DNNs为了达到人类设置的监督目标,倾向于利用数据和标签之间所有的相关性来拟合数据,其中就可能有虚假的相关性,比如一张图像为草地上的鸡,草地并不是决定该图像标签 (鸡)的决定性因素,但是因为其在类别为“鸡”的图像里经常出现,所以容易被神经网络利用来做决策。因此,有理由认为攻击者的成功在于利用了这类虚假因子,造成训练数据和测试数据间的域偏移,使之不满足独立同分布 (IID)假设,降低模型的泛化性能。
然而这两类攻击造成的威胁很大程度上可以通过对抗训练 (adversarial training)得到缓解。对抗训练通过让模型在训练阶段拟合对抗数据来提升鲁棒性,对抗训练的成功展示出被攻击者扰动的虚假因子可以很容易的通过对抗训练恢复出来。所以如果攻击者可以识别并且扰动数据和标签之间的因果关系,就可以进一步提升他们在对抗训练下的性能。
论文链接:https://dl.acm.org/doi/pdf/10.1145/3534678.3539242
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢