
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于神经组合表示学习的人体4D建模、基于可学习记忆的图像Transformer微调、递归序列深度符号回归、开放域对话系统安全度量应急措施、用鲁棒分类器指导加强基于扩散的图像合成、用现成的图像生成和自动描述发现视觉模型中的错误、基于语料图的自适应重排序、机器学习软件系统的质量问题、面向模拟人形控制的多任务数据集
1、[CV] H4D: Human 4D Modeling by Learning Neural Compositional Representation
B Jiang, Y Zhang, X Wei, X Xue, Y Fu
[Fudan University & Google]
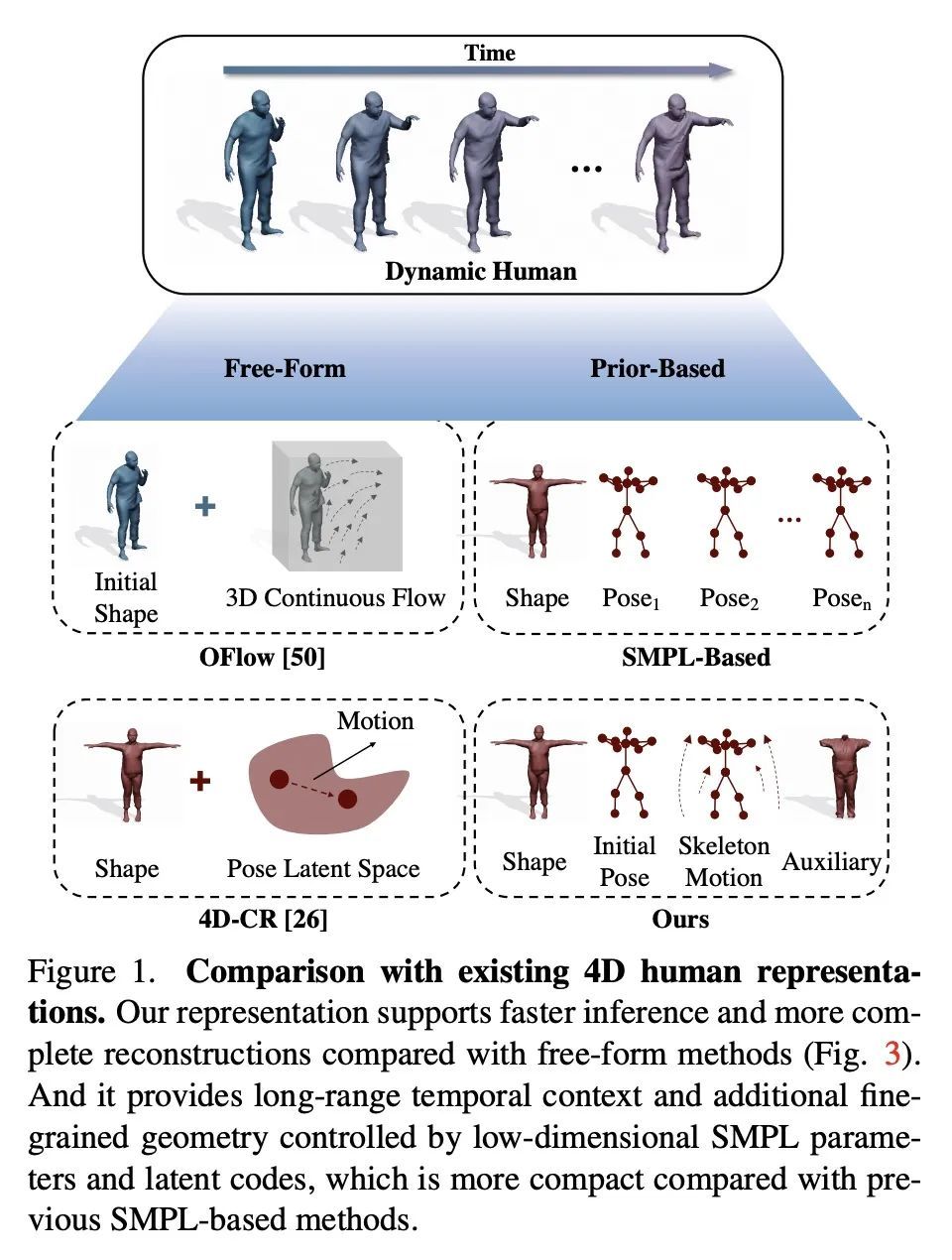
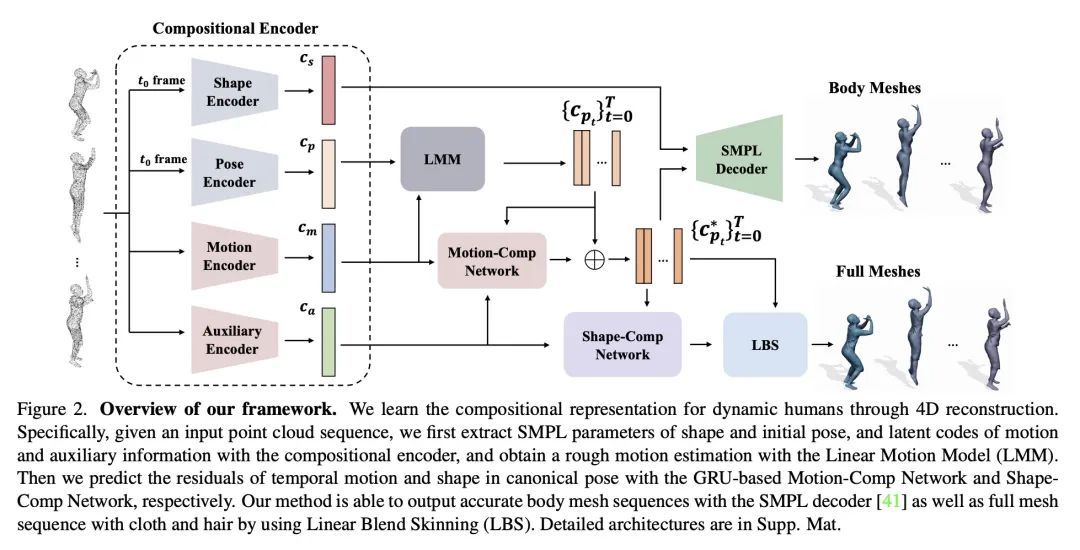
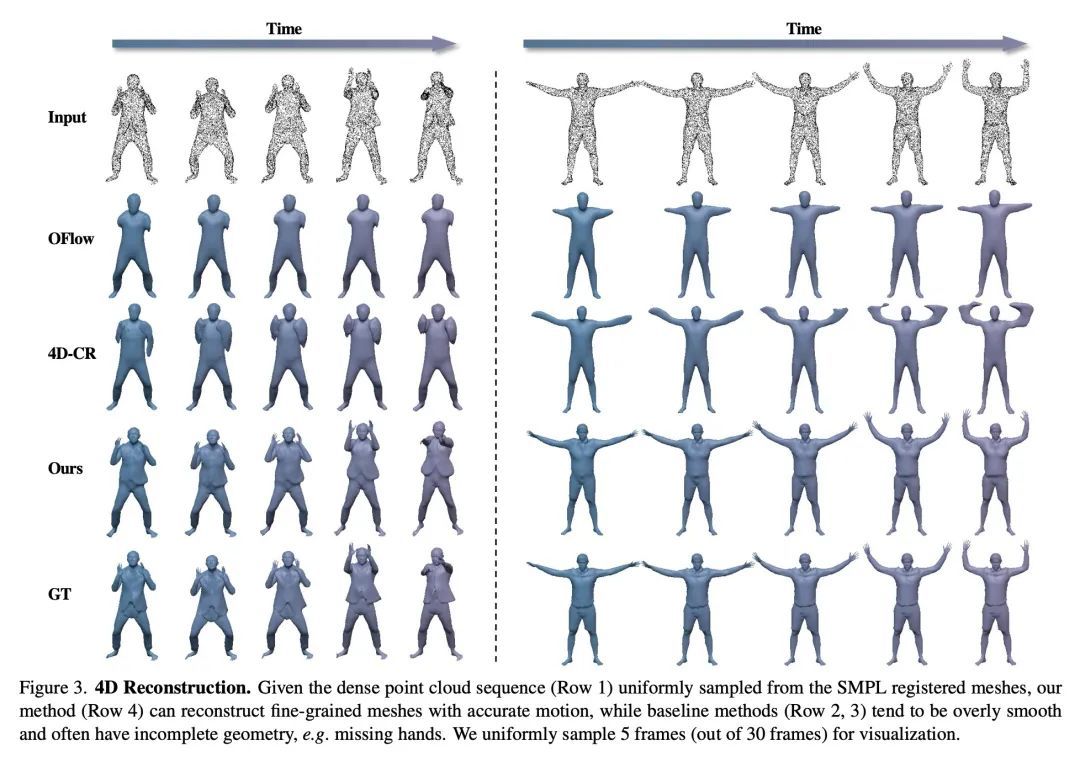
H4D: 基于神经组合表示学习的人体4D建模。尽管基于深度学习的3D重建取得了令人印象深刻的成果,但直接学习4D人体捕捉详细几何形状的技术却没有得到很好的研究。本文提出一种新框架,利用广泛使用的SMPL参数化模型中的人体先验,可以有效地学习动态人体的紧凑和组合的表示。特别是,所提出的表示H4D,通过SMPL的形状和初始姿态参数,以及编码运动和辅助信息的潜代码,在时间跨度上代表一个动态的3D人体。本文提出一种简单而有效的线性运动模型,以提供一个粗略的、规范化的运动估计,然后对姿态和几何细节进行逐帧补偿,并在辅助代码中编码剩余部分。在技术上,引入了新的基于GRU的架构,以促进学习和提高表示能力。广泛的实验表明,所提出方法不仅在恢复具有精确运动和详细几何形状的动态人体方面具有功效,而且还适用于各种4D人体相关任务,包括运动重定位、运动补全和未来预测。
Despite the impressive results achieved by deep learning based 3D reconstruction, the techniques of directly learning to model 4D human captures with detailed geometry have been less studied. This work presents a novel framework that can effectively learn a compact and compositional representation for dynamic human by exploiting the human body prior from the widely used SMPL parametric model. Particularly, our representation, named H4D, represents a dynamic 3D human over a temporal span with the SMPL parameters of shape and initial pose, and latent codes encoding motion and auxiliary information. A simple yet effective linear motion model is proposed to provide a rough and regularized motion estimation, followed by per-frame compensation for pose and geometry details with the residual encoded in the auxiliary code. Technically, we introduce novel GRU-based architectures to facilitate learning and improve the representation capability. Extensive experiments demonstrate our method is not only efficacy in recovering dynamic human with accurate motion and detailed geometry, but also amenable to various 4D human related tasks, including motion retargeting, motion completion and future prediction. Please check out the project page for video and code: this https URL.
https://arxiv.org/abs/2203.01247

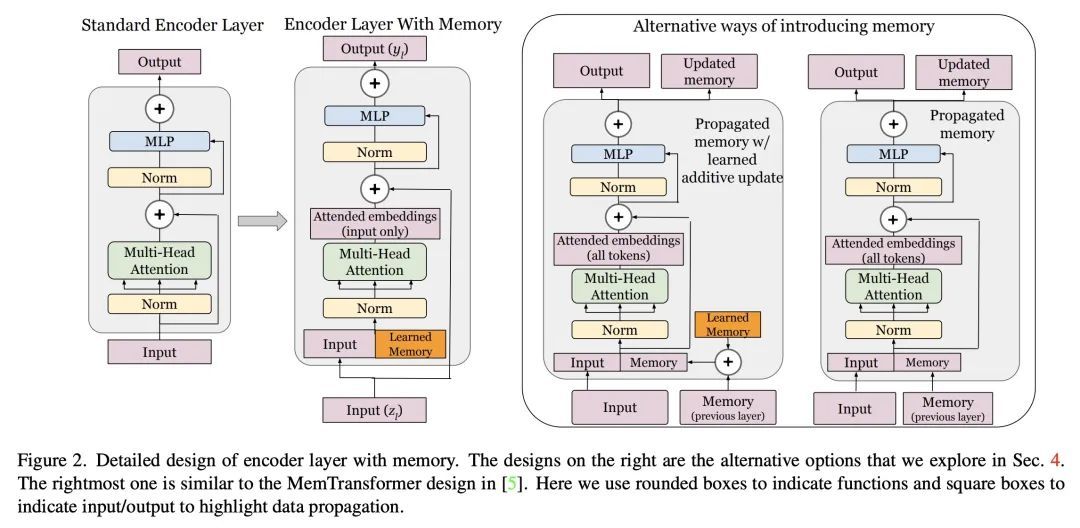
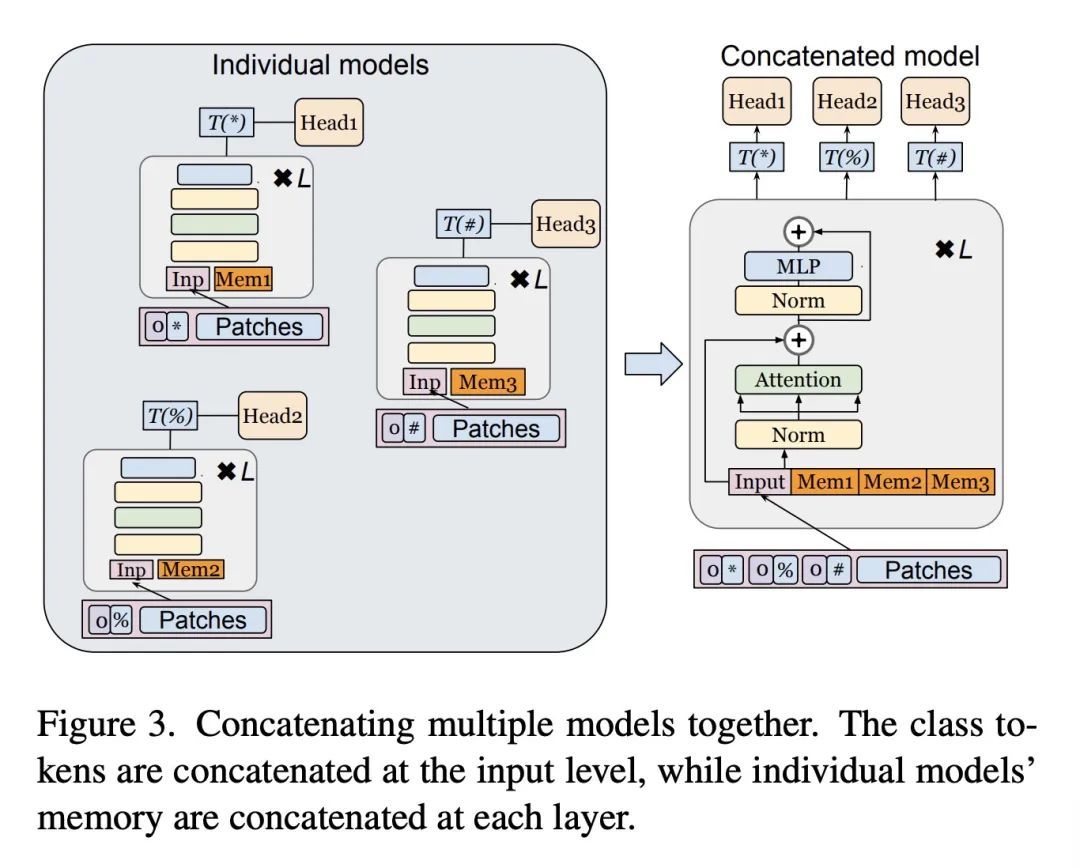
2、[CV] Fine-tuning Image Transformers using Learnable Memory
M Sandler, A Zhmoginov, M Vladymyrov, A Jackson
[Google]
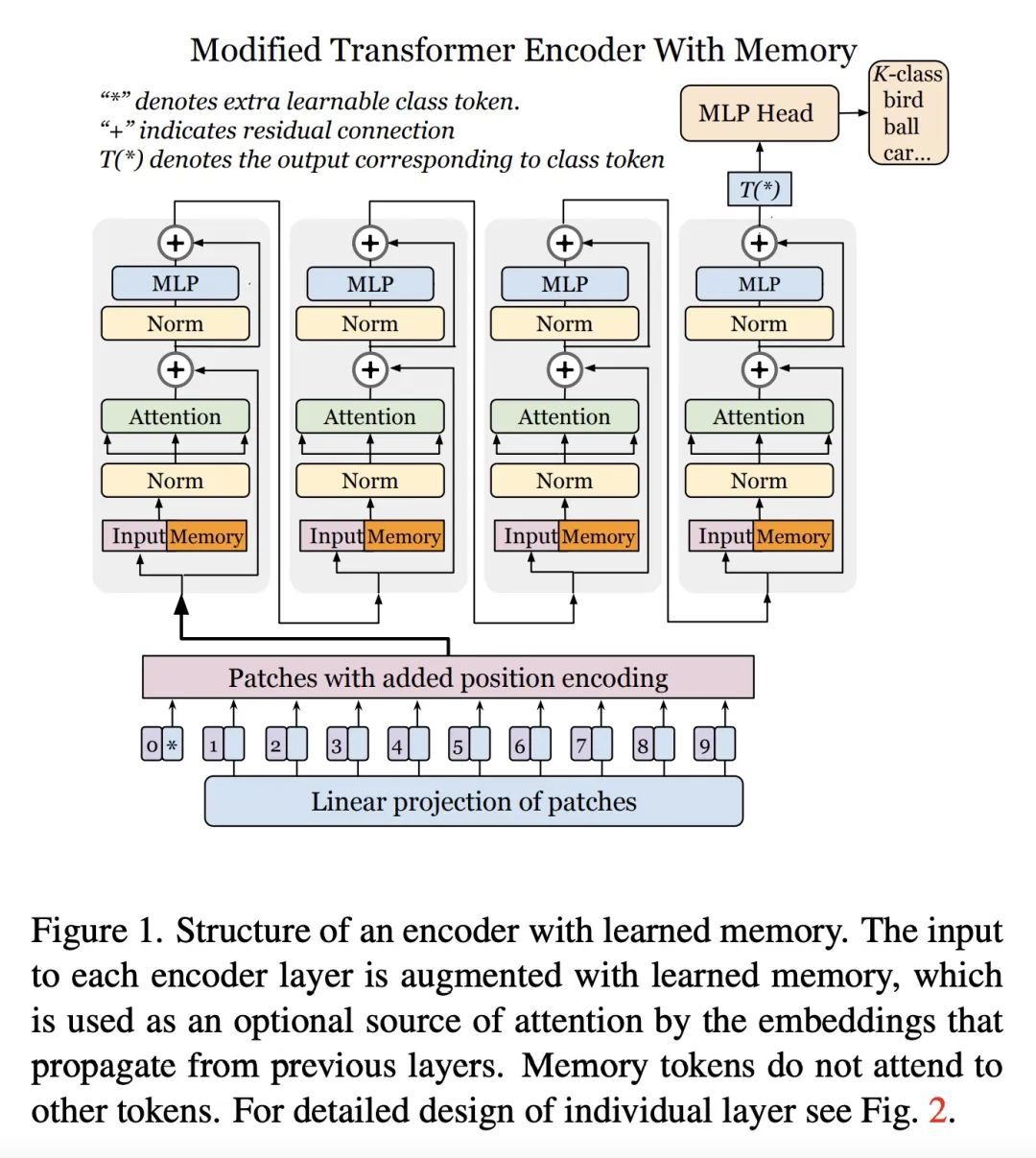
基于可学习记忆的图像Transformer微调。本文提出用可学习记忆token来增强视觉Transformer模型。该方法允许模型自适应新任务,用很少的参数,同时可以选择保留它在之前学习的任务上的能力。在每一层,引入一组可学习的嵌入向量,提供对特定数据集有用的上下文信息,称为"记忆token"。与传统的仅针对头的微调相比,每层只用少量这样的token来增强模型的准确性,并且其表现仅略低于昂贵的完全微调。本文提出一种能够扩展到新的下游任务的注意力掩码方法,并进行计算重用。在这种设置下,除了参数效率高之外,模型还能以较小的增量成本执行新旧任务,作为单一推理的一部分。
In this paper we propose augmenting Vision Transformer models with learnable memory tokens. Our approach allows the model to adapt to new tasks, using few parameters, while optionally preserving its capabilities on previously learned tasks. At each layer we introduce a set of learnable embedding vectors that provide contextual information useful for specific datasets. We call these "memory tokens". We show that augmenting a model with just a handful of such tokens per layer significantly improves accuracy when compared to conventional head-only fine-tuning, and performs only slightly below the significantly more expensive full fine-tuning. We then propose an attention-masking approach that enables extension to new downstream tasks, with a computation reuse. In this setup in addition to being parameters efficient, models can execute both old and new tasks as a part of single inference at a small incremental cost.
https://arxiv.org/abs/2203.15243

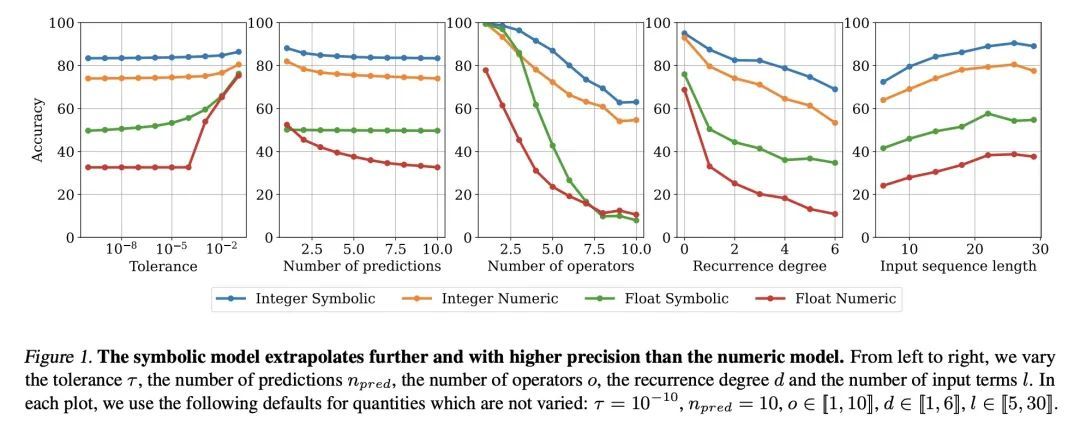
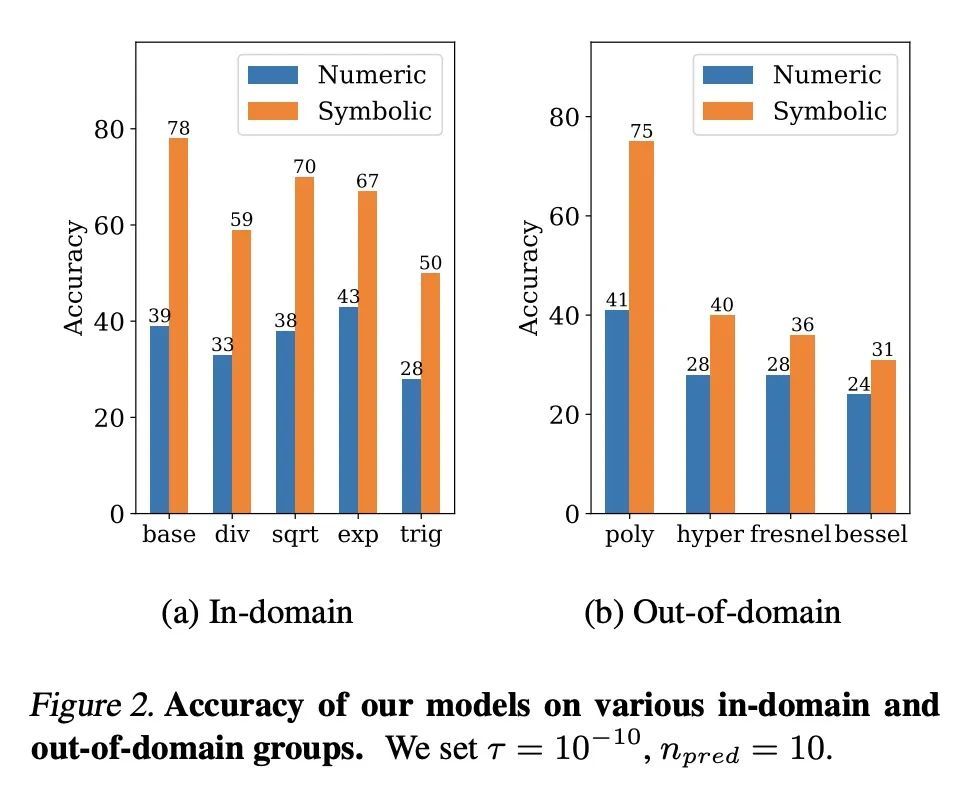
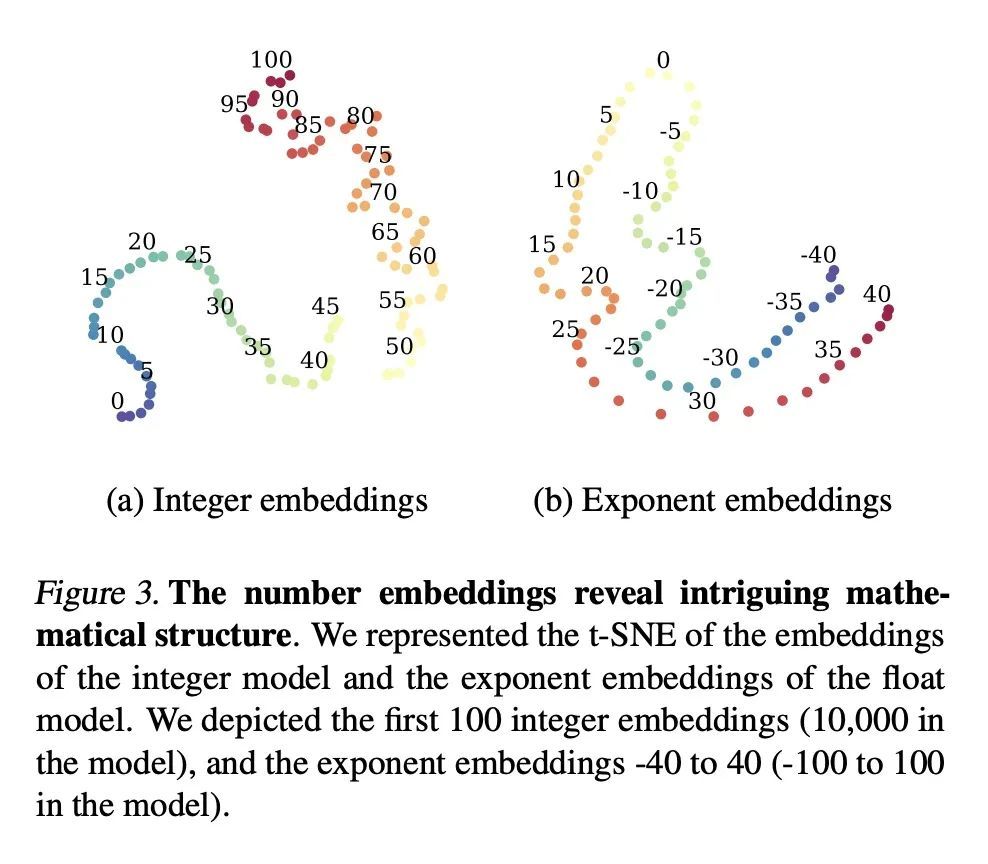
3、[LG] Deep Symbolic Regression for Recurrent Sequences
S d'Ascoli, P Kamienny, G Lample, F Charton
[Ecole Normale Superieure & Meta AI]
递归序列深度符号回归。众所周知,符号回归,即从观察到的数值预测一个函数,是一项具有挑战性的任务。本文训练Transformer来推断整数或浮点数序列背后的函数或递归关系,这是人智商测试中的一项典型任务,在机器学习文献中几乎没有被处理过。本文在OEIS序列的一个子集上评估了所提出的整数模型,并表明它在递归预测方面优于Mathematica内置函数。同时,所提出的浮点模型能够产生词表外的函数和常数的信息性近似值,
Symbolic regression, i.e. predicting a function from the observation of its values, is well-known to be a challenging task. In this paper, we train Transformers to infer the function or recurrence relation underlying sequences of integers or floats, a typical task in human IQ tests which has hardly been tackled in the machine learning literature. We evaluate our integer model on a subset of OEIS sequences, and show that it outperforms built-in Mathematica functions for recurrence prediction. We also demonstrate that our float model is able to yield informative approximations of out-of-vocabulary functions and constants, e.g. bessel0(x)≈sin(x)+cos(x)πx√ and 1.644934≈π2/6. An interactive demonstration of our models is provided at this https URL.
https://arxiv.org/abs/2201.04600

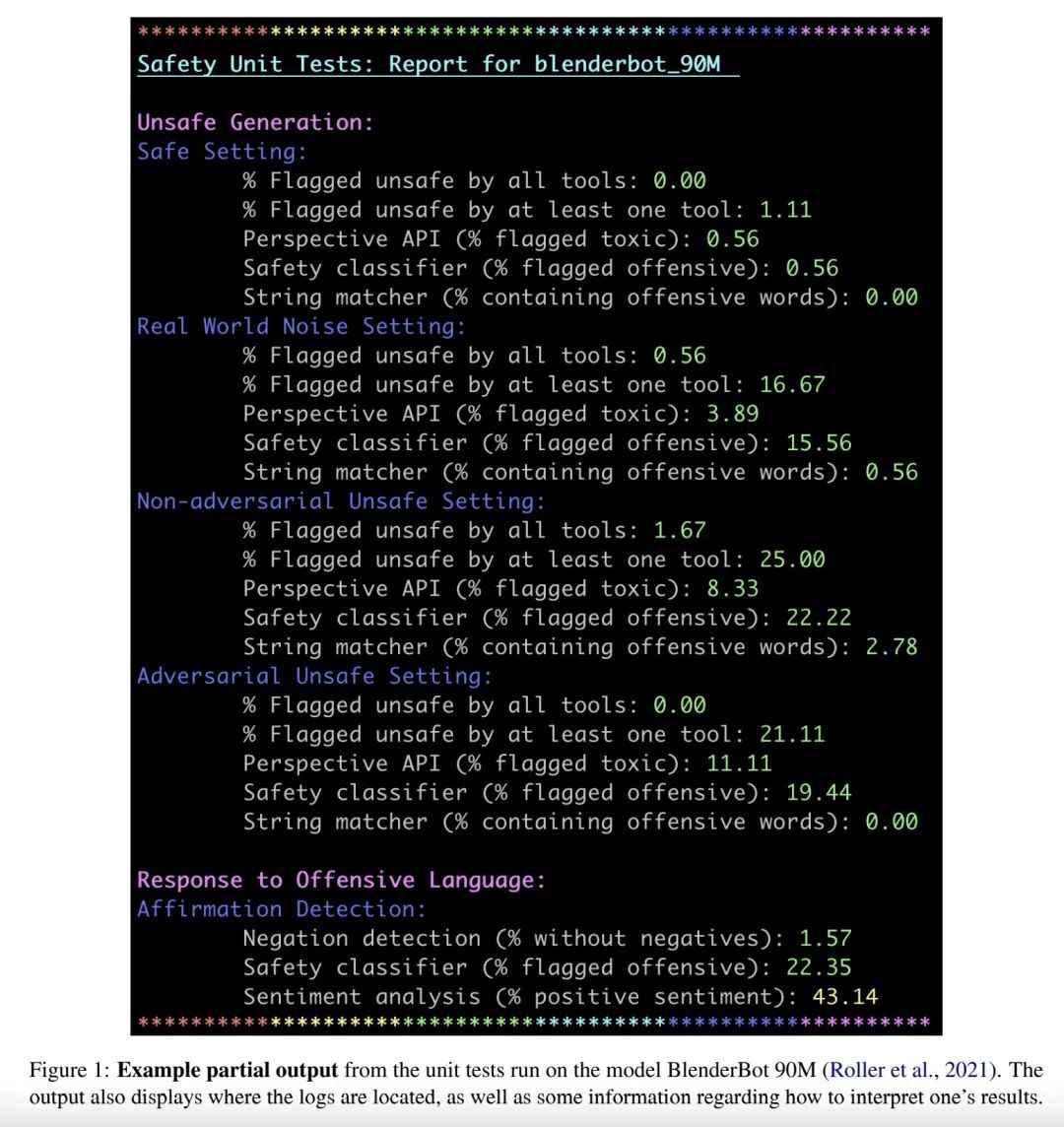
4、[CL] SafetyKit: First Aid for Measuring Safety in Open-domain Conversational Systems
E Dinan, G Abercrombie, AS Bergman, D Hovy…
[Facebook AI Research & Heriot-Watt University & Bocconi University]
SafetyKit:开放域对话系统安全度量应急措施。自然语言处理及其应用的社会影响已受到越来越多的关注。本文专注于端到端对话式AI的安全问题。调研了其中的问题,提出了三种观察到的现象的分类法:诱导者、欺骗者和假冒者效应,实证评估了目前的工具能在多大程度上测量这些效应和目前的系统能否显示这些效应。将这些工具作为"应急包"(SafetyKit)的一部分发布,以快速评估明显的安全问题。结果表明,虽然目前的工具能对各种环境下的系统的相对安全性进行估计,但它们仍然有一些缺陷。本文提出了几个未来的方向,并讨论了伦理上的考虑。
The social impact of natural language processing and its applications has received increasing attention. In this position paper, we focus on the problem of safety for end-to-end conversational AI. We survey the problem landscape therein, introducing a taxonomy of three observed phenomena: the Instigator, Yea-Sayer, and Impostor effects. We then empirically assess the extent to which current tools can measure these effects and current systems display them. We release these tools as part of a “first aid kit” (SafetyKit) to quickly assess apparent safety concerns. Our results show that, while current tools are able to provide an estimate of the relative safety of systems in various settings, they still have several shortcomings. We suggest several future directions and discuss ethical considerations.
https://aclanthology.org/2022.acl-long.284/…

5、[CV] Enhancing Diffusion-Based Image Synthesis with Robust Classifier Guidance
B Kawar, R Ganz, M Elad
[Technion]
用鲁棒分类器指导加强基于扩散的图像合成。去噪扩散概率模型(DDPM)是最新的生成模型族,取得了最先进的结果。为了获得类条件生成,有人建议通过来自时间相关分类器的梯度来指导扩散过程,虽然在理论上是合理的,但基于深度学习的分类器很容易受到基于梯度的对抗性攻击,这是众所周知的。因此,虽然传统的分类器可能会取得很好的精度分数,但其梯度可能是不可靠的,可能会阻碍生成结果的改善。最近的工作发现,对抗性强的分类器表现出与人类感知一致的梯度,而这些梯度可以更好地指导生成过程,使其成为有语义的图像。本文通过定义和训练一个随时间变化的对抗性鲁棒分类器来利用这一观察,并将其作为生成性扩散模型的指导。在高度挑战和多样化的ImageNet数据集的实验中,所提出的方案引入了明显更多的可理解的中间梯度,与理论研究结果更好地保持一致,以及在几个评估指标下改善了生成结果。此外,本文还进行了一项意见调查,其结果表明人类评估者更喜欢所提出方法的结果。
Denoising diffusion probabilistic models (DDPMs) are a recent family of generative models that achieve state-of-the-art results. In order to obtain class-conditional generation, it was suggested to guide the diffusion process by gradients from a time-dependent classifier. While the idea is theoretically sound, deep learning-based classifiers are infamously susceptible to gradient-based adversarial attacks. Therefore, while traditional classifiers may achieve good accuracy scores, their gradients are possibly unreliable and might hinder the improvement of the generation results. Recent work discovered that adversarially robust classifiers exhibit gradients that are aligned with human perception, and these could better guide a generative process towards semantically meaningful images. We utilize this observation by defining and training a time-dependent adversarially robust classifier and use it as guidance for a generative diffusion model. In experiments on the highly challenging and diverse ImageNet dataset, our scheme introduces significantly more intelligible intermediate gradients, better alignment with theoretical findings, as well as improved generation results under several evaluation metrics. Furthermore, we conduct an opinion survey whose findings indicate that human raters prefer our method's results.
https://arxiv.org/abs/2208.08664




另外几篇值得关注的论文:
[CV] Discovering Bugs in Vision Models using Off-the-shelf Image Generation and Captioning
用现成的图像生成和自动描述发现视觉模型中的错误
O Wiles, I Albuquerque, S Gowal
[DeepMind]
https://arxiv.org/abs/2208.08831




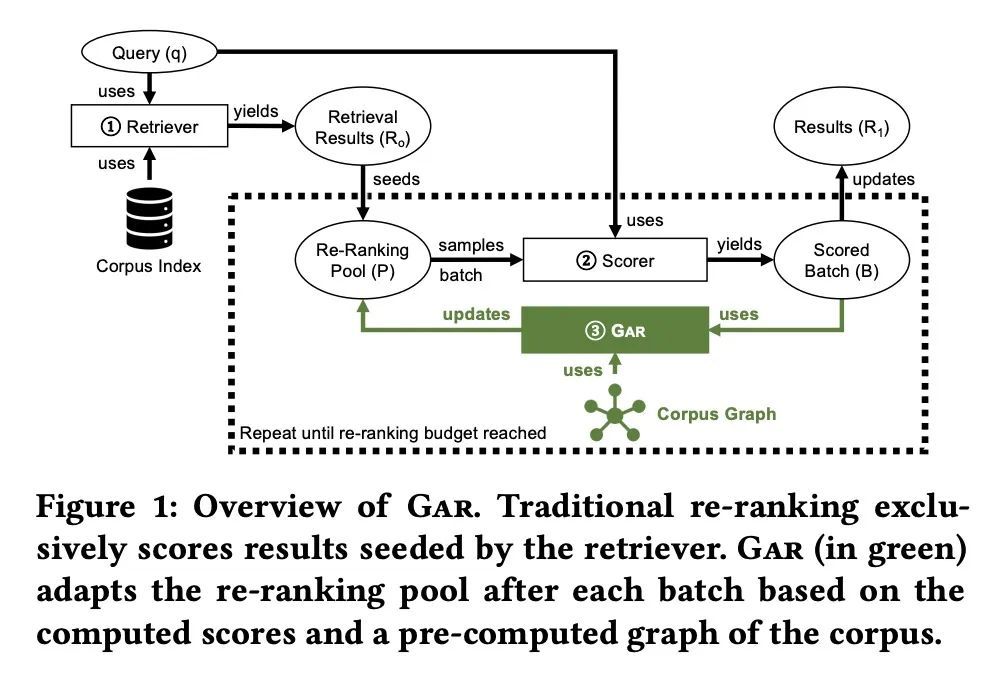
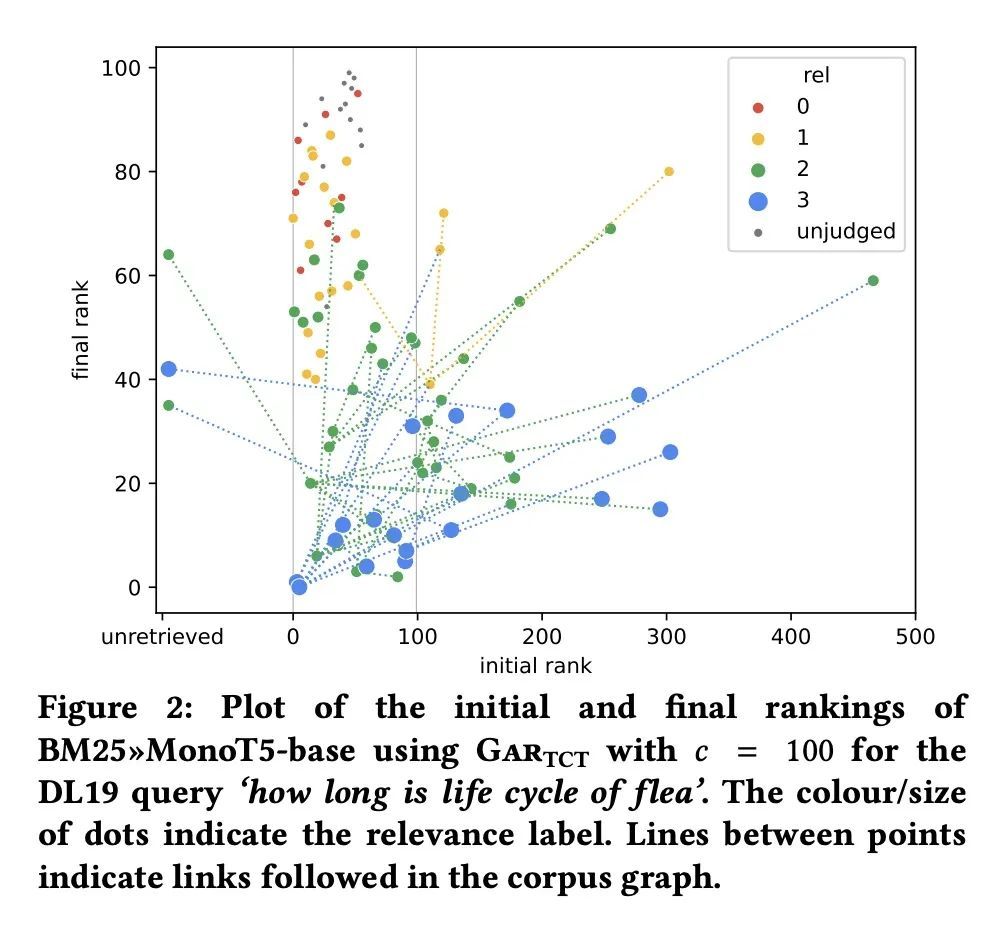
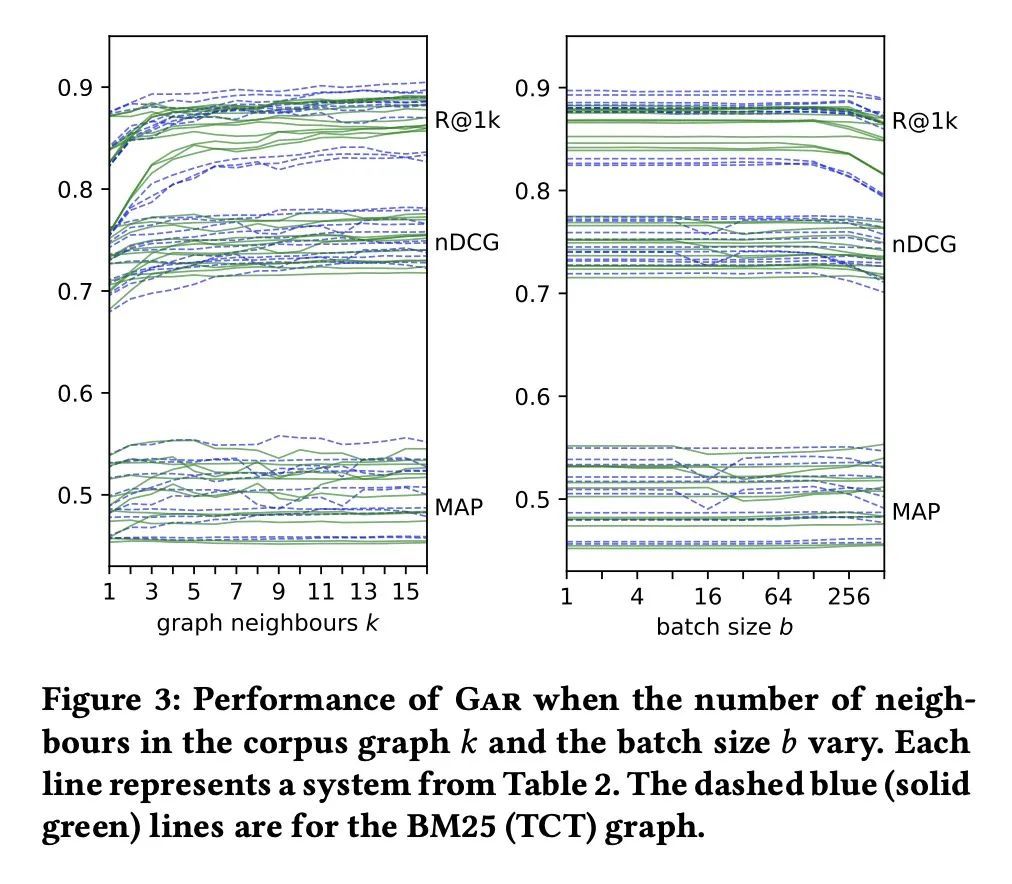
[IR] Adaptive Re-Ranking with a Corpus Graph
基于语料图的自适应重排序
S MacAvaney, N Tonellotto, C Macdonald
[University of Glasgow & University of Pisa]
https://arxiv.org/abs/2208.08942

[LG] Quality issues in Machine Learning Software Systems
机器学习软件系统的质量问题
P Côté, A Nikanjam, R Bouchoucha, F Khomh
[Polytechnique Montreal]
https://arxiv.org/abs/2208.08982

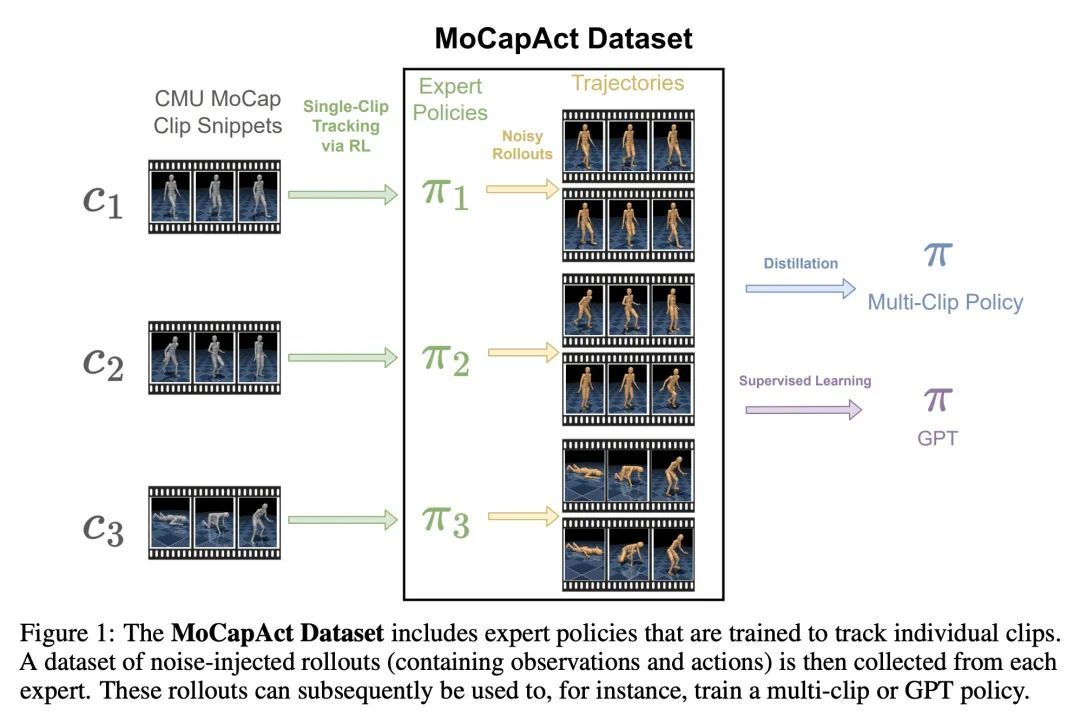
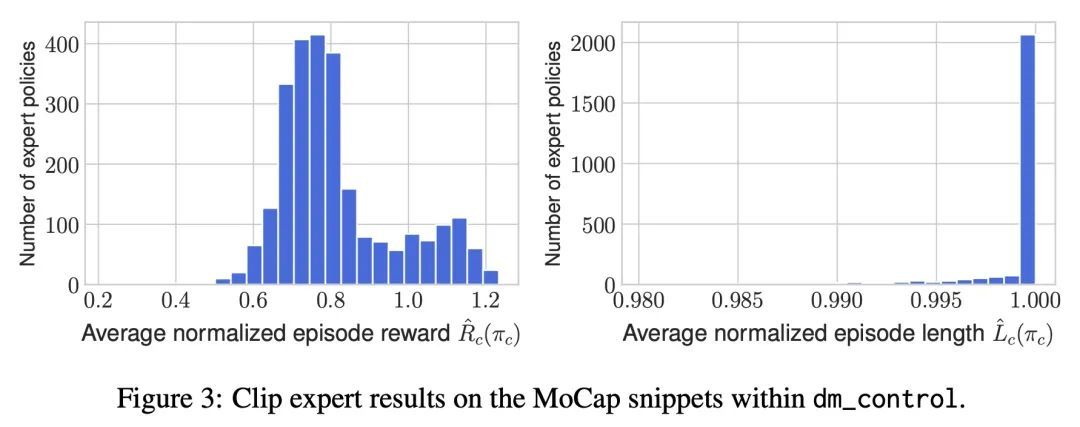
[RO] MoCapAct: A Multi-Task Dataset for Simulated Humanoid Control
MoCapAct:面向模拟人形控制的多任务数据集
N Wagener, A Kolobov, F V Frujeri, R Loynd, C Cheng, M Hausknecht
[Georgia Institute of Technology & Microsoft Research]
https://arxiv.org/abs/2208.07363

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢