
GNN虽牛,但也避免不了计算复杂性等问题。为此,谷歌大脑与牛津大学、哥伦比亚大学的研究人员提出了一种全新的GNN:GKATs。不仅解决了计算复杂度问题,还被证明优于9种SOTA GNN。
从社交网络到生物信息学,再到机器人学中的导航和规划问题,图在各种现实世界的数据集中普遍存在。 于是乎,人们对专门用于处理图结构数据的图神经网络(GNN)产生了极大的兴趣。 尽管现代GNN在理解图形数据方面取得了巨大的成功,但在有效处理图形数据方面仍然存在一些挑战。 例如,当所考虑的图较大时,计算复杂性就成为一个问题。 相反,在空间域工作的算法避免了昂贵的频谱计算,但为了模拟较长距离的依赖关系,不得不依靠深度GNN架构来实现信号从远处节点的传播,因为单个层只模拟局部的相互作用。 为解决这些问题,谷歌大脑、哥伦比亚大学和牛津大学的研究团队提出了一类新的图神经网络:Graph Kernel Attention Transformers(GKATs)。
其结合了图核、基于注意力的网络和结构先验,以及最近的通过低秩分解技术应用小内存占用隐式注意方法的Transformer架构。

该团队证明GKAT比SOTA GNN具有更强的表达能力,同时还减少了计算负担。
「是否有可能设计具有密集单个层的 GNN,显式建模图中更长范围的节点到节点关系,从而实现更浅的架构,同时扩展更大的(不一定是稀疏的)图?」
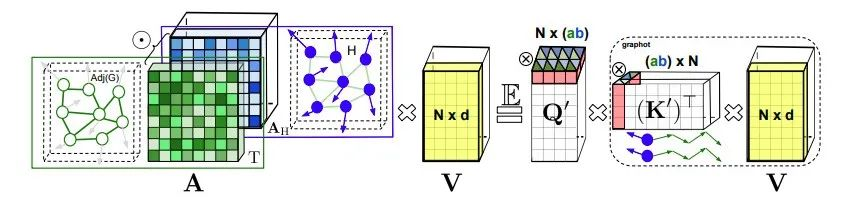
GKATs中可分解的长注意力
GKAT将每一层内的图注意力建模为节点特征向量的核矩阵和图核矩阵的Hadamard乘积。
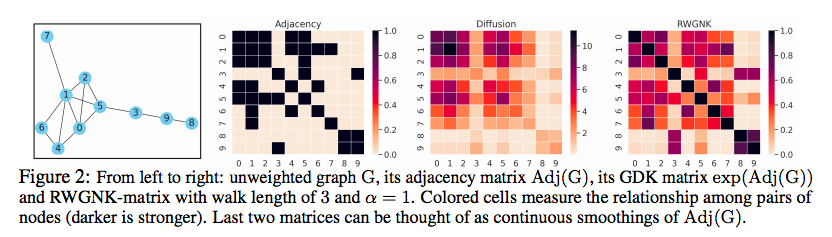
这使GKAT能够利用计算效率高的隐式注意机制,并在单层内对更远距离的依赖项进行建模,从而将其表达能力提升到超越传统GNN的水平。 为了在图节点上定义可实现高效映射的表达内核,研究人员采用了一种新颖的随机游走图节点内核 (RWGNKs) 方法,其中两个节点的值作为两个频率向量的点积给出,这些向量记录了图节点中的随机游走。 完整的 GKAT 架构由几个块组成,每个块由注意力层和标准 MLP 层构建而成。 值得注意的是,注意层与输入图的节点数成线性关系而不是二次方,因此与其常规的图注意力对应物相比降低了计算复杂度。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢