
【北京理工大学团队】使用弱标注的视频描述的渐进式视觉推理 【论文标题】Progressive Visual Reasoning for Video Captioning Using Weak Annotation 【作者团队】Jingyi Hou,Yunde Jia,Xinxiao Wu,Yayun Qi,Yao Hu 【发表时间】2020/09/03 【论文链接】https://arxiv.org/pdf/2009.01067.pdf
【推荐理由】
本文首次尝试研究基于弱监督的视频描述任务。
大多数现有的视频描述方法都是基于强注释构建的,即使用成对的「视频-句子」来标注视频,而这一过程既费时又费力。事实上,现在我们有大量带有弱标注的视频,它们仅仅包含动作、物体等语义概念。在本文中,作者研究了如何使用弱标注训练一个视频描述模型。为此,作者们提出了一种渐进式的视觉推理方法,该方法通过为视频描述推理出更多的语义概念及其之间的依赖关系,利用弱标注渐进式地生成更好的描述语句。为了对概念之间的关系进行建模,我们使用了依赖树,它们通过利用大规模句子语料库中的外部知识而展开。作者通过遍历这些依赖树生成用于训练视频描述模型的句子。在此基础之上,作者开发了一种迭代式精修算法,交替地进行以下工作:(1)通过展开依赖树精修句子(2)使用精修后的句子对描述模型进行调优。在若干个数据集上的实验结果表明,本文提出的使用弱标注的方法,与目前使用强标注的最优算法的性能相当。
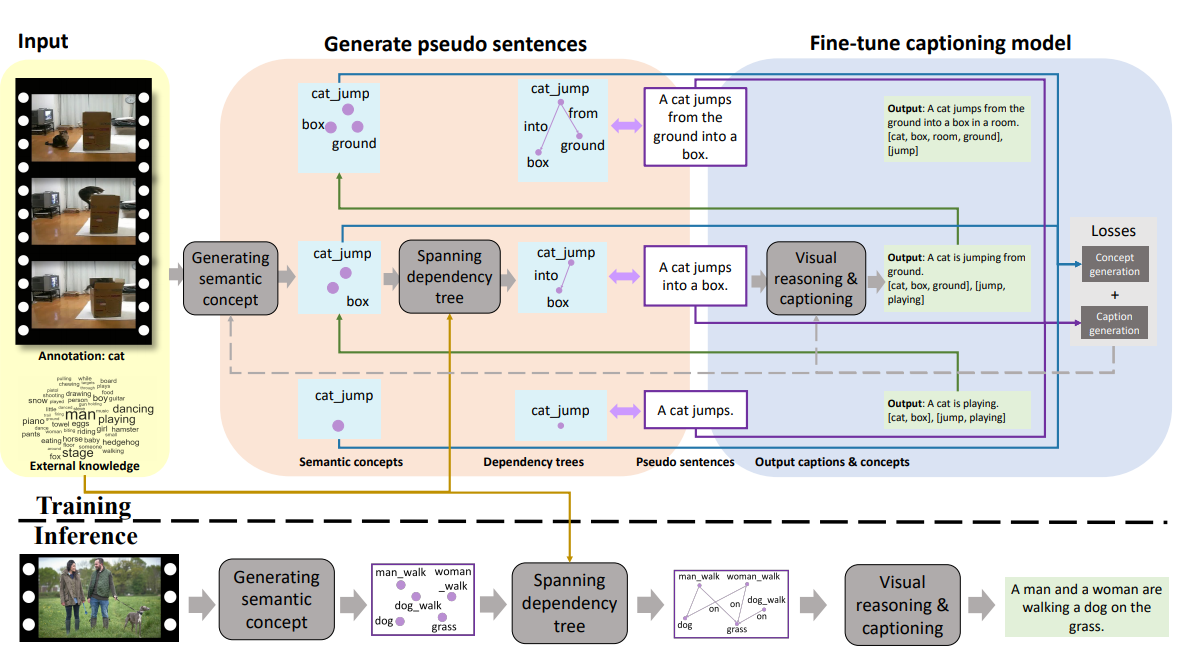
在训练阶段,迭代式地更新视频描述模型,该模型不仅仅生成描述文字,还会通过利用从大规模外部句子语料库中提取的外部知识来生成语义概念。接着,作者将新生成的语义概念输入给下一次迭代,从而使得依赖树进一步扩展。
本文的主要贡献为: (1)本文作者提出了一种渐进式的视觉推理方法,该方法通过利用外部知识渐进式地精修伪句子,从而训练视频描述模型。 (2)本文作者首次尝试研究基于弱标注的视频描述,在若干数据集上进行的实验表明,本文提出的使用弱标注的方法,与目前使用强标注的最优算法的性能相当。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢