【标题】PD-MORL: Preference-Driven Multi-Objective Reinforcement Learning Algorithm
【作者团队】Toygun Basaklar, Suat Gumussoy, Umit Y. Ogras
【发表日期】2022.8.16
【论文链接】https://arxiv.org/pdf/2208.07914.pdf
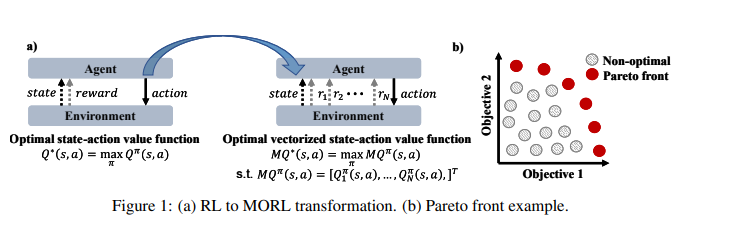
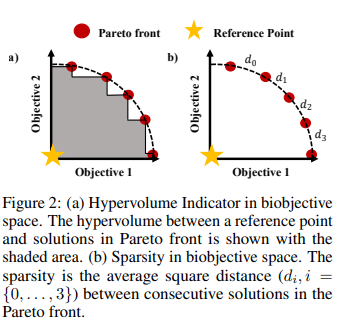
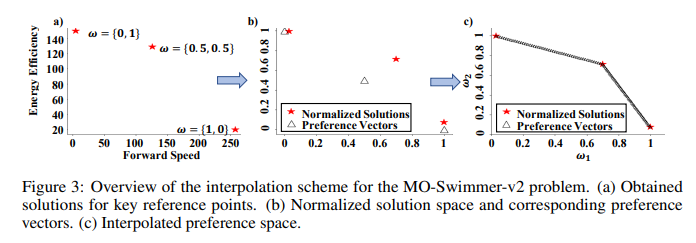
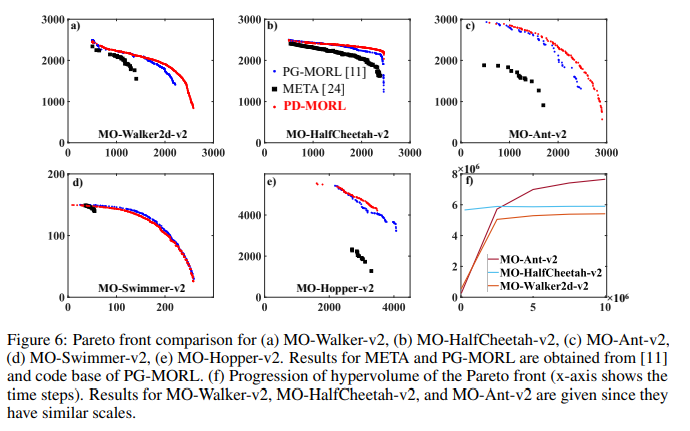
【推荐理由】许多现实世界的问题涉及多个可能相互冲突的目标。多目标强化学习(MORL)方法通过最大化由偏好向量加权的联合目标函数来解决这些问题。此类方法找到与训练期间指定的偏好向量相对应的固定定制策略。然而,设计约束和目标通常在现实场景中动态变化。此外,为每个潜在偏好存储策略是不可扩展的。因此,通过单个训练获得给定域中整个偏好空间的一组帕累托前沿解至关重要。为此,本文提出了新颖的MORL算法,其训练单个通用网络以覆盖整个偏好空间。偏好驱动的MORL(PD-MORL),利用偏好作为指导来更新网络参数。在使用经典深海宝藏和果树导航基准演示PD-MORL之后,最后评估了其在具有挑战性的多目标连续控制任务中的性能。



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢