
前言
互联网的极速发展使得世界各地可以更加紧密地进行商务及日常交流,然而语言不通使得这样的交流产生了壁垒。 机器翻译的研究致力于打破不同语言使用者交流的壁垒,追求更流畅的沟通。文本翻译一直是机器翻译的主要工作方向,然而现在的信息表达方式更加多样化,单纯文本的翻译难以满足多样化的场景需求。语音是人类日常交流中的主要信息载体,语音到语音的翻译 (Speech-to-speech Translation, S2ST) 可以帮助人们更加自然高效地交流。在很多场景下,语音到语音的翻译可以提升交流体验感,例如:视频直播、国外旅游、国际贸易等。
端到端语音到语音翻译的现状以及挑战
语音到语音翻译可以有两种实现方式,一种是级联语音识别、机器翻译以及语音合成系统;另一种是端到端的方案:采用一个模型直接把一种语言的语音翻译合成为另一种语言的语音。相比于级联的方案,端到端的研究起步比较晚,并在近些年被Jia等人正式提出并验证可行,该工作被称为Translatotron[1]。之后,Translatotron2[2]被提出以便提高预测语音的鲁棒性,并在翻译中保留源说话者的音色。另一方面,Lee提出在目标语音上采用离散单元 (discrete units)表示的方法[3],旨在为没有文字的语言构建直接的S2ST系统。该方法不再预测连续的频谱图,而是预测从目标语音的自监督表示中学习的离散单元。文本数据可以在多任务学习框架下被使用,也可以不使用。此外,Lee等人提出了一种无文本 S2ST 系统[4],可以在没有任何文本数据的情况下进行训练。 同时,它首次尝试了采用真实世界的 S2ST 数据进行训练来生成多说话人目标语音。
端到端的系统往往有更低的延时,同时能缓解级联系统中的误差累计问题。相比于级联系统,数据量不足是端到端系统面临的最大挑战之一。利用伪标注数据在深度学习领域是一种十分有效的提升模型性能的方法,本文将为大家介绍一篇由字节跳动 AI-Lab 与南方科技大学共同发表在 InterSpeech 2022 上的文章 ——Leveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation[5]。

论文地址:
https://arxiv.org/pdf/2205.08993.pdf
代码地址:
https://github.com/fengpeng-yue/speech-to-speech-translation
伪标注数据的使用方法
随着工业和学术界的不断积累,语音识别的开源数据量越来越多。我们可以将开源的语音识别数据中的文本经过机器翻译系统翻译到目标语言,再将目标语言的文本经过语音合成系统合成到目标语音,以此来构造伪标注的语音到语音的翻译数据集。为了缓解端到端语音到语音翻译数据量不足的问题,本文探索了三种利用伪标注数据 (Pseudo Translation Labeling,PTL) 的方法:1、Pre-training and Fine-tuning,2、Mixed-tuning,3、Prompt-tuning。
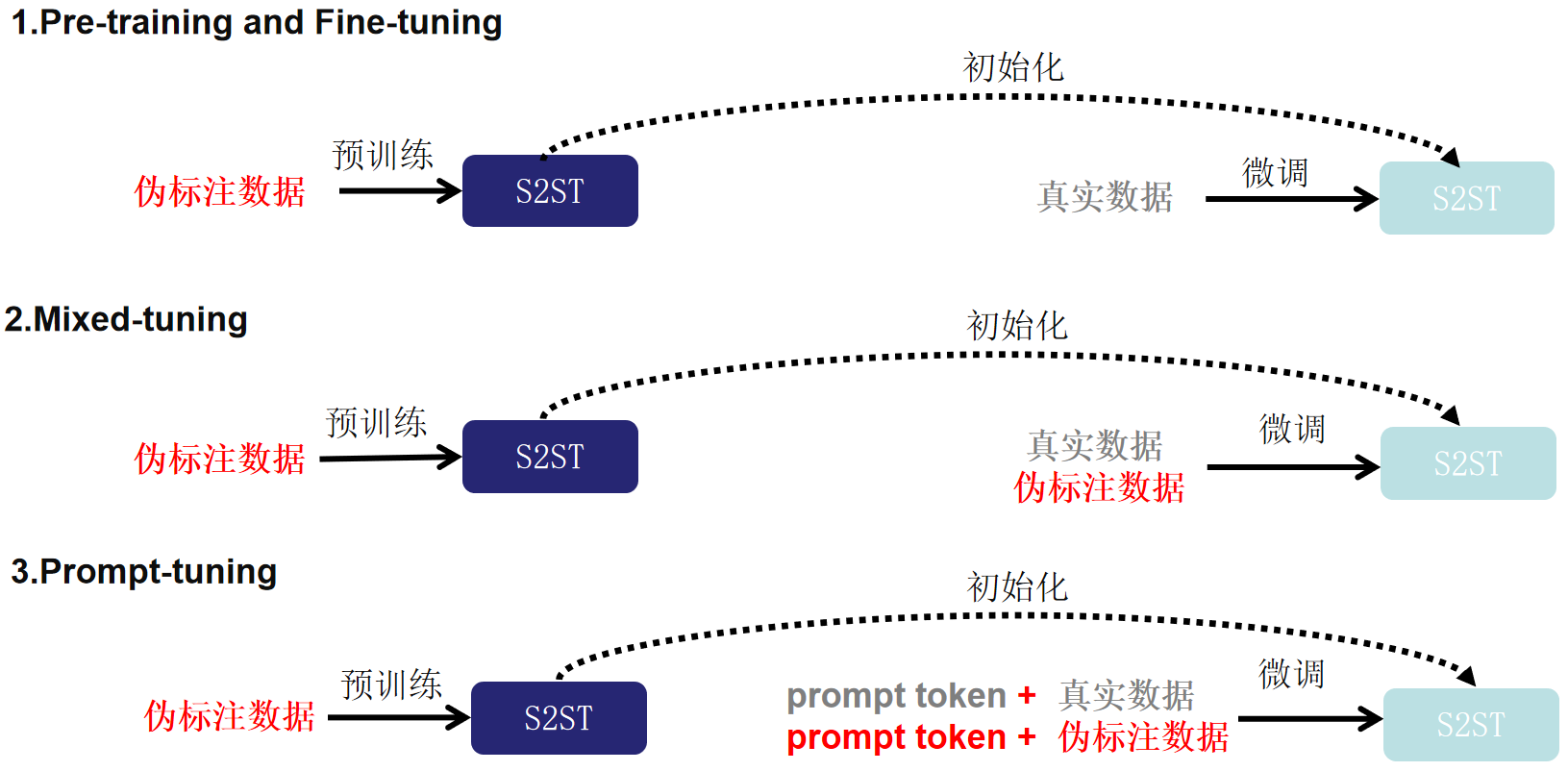
1、Pre-training and Fine-tuning
在这个方法中,论文利用伪标注数据首先预训练一个端到端的语音到语音翻译的模型。然后利用真实数据在这个模型上进行微调。
2、Mixed-tuning
相比于Pre-training and Fine-tuning,在微调阶段除了采用真实数据,论文使用真实数据和伪标注数据一起微调模型。
3、Prompt-tuning
为了增强模型学习各种数据源之间差异的能力,论文采用“预训练、提示和预测”[6]范式。 在预训练的基础上,将数据集的类别作为prompt,并在提示调整阶段以预定义embedding的形式将其附加到每个样本的输入特征中。 通过明确的prompt,其可以在推理阶段操纵模型适应不同源的数据。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢