

导读
伪装物体检测(COD)旨在识别完全嵌入其环境中的物体,该环境在医学、艺术和农业等领域具有各种下游应用。然而,利用人眼的感知能力识别伪装物体是一项极具挑战性的任务。因此,作者声称COD任务的目标不仅仅是在单个RGB域中模拟人类的视觉能力,而是超越人类的生物视觉。然后,作者引入频域作为额外线索,以更好地从背景中检测伪装的物体。
为了将频率线索很好地融入到CNN模型中,作者提出了一个具有两个特殊组件的强大网络。作者首先设计了一种新的频率增强模块(FEM),以在频域中挖掘伪装物体的线索。它包含浮点离散余弦变换,然后是可学习的增强。
然后,作者使用特征对齐来融合RGB域和频域的特征。此外,为了进一步充分利用频率信息,作者提出了高阶关系模块(HOR)来处理丰富的融合特征。在三个广泛使用的COD数据集上的综合实验表明,该方法显著优于其他最先进的方法。
贡献
为了检测和分割完美嵌入环境中的物体,伪装物体检测(COD)已在计算机视觉领域中流行。作为初步步骤,COD在各种视觉系统中起着至关重要的作用,例如息肉分割、肺部感染分割和娱乐艺术。
传统方法通过利用手工制作的低级特征来检测伪装对象,因此这些方法在复杂场景中往往失败。近年来,随着深度卷积神经网络(CNN)的应用,基于CNN的方法将COD的性能提升到了一个新的水平。一些方法试图设计纹理增强模块或采用注意机制来引导模型关注伪装区域。一些方法试图借助额外的边缘信息准确定位伪装对象。最近的工作试图将分割伪装物体视为一个两阶段的过程。
本文没有使用这些复杂的技术,只需使用带Res2Net和ResNet50主干的U-Net结构网络来检测伪装物体。与现有的最先进(SOTA)方法相比,仅使用U-Net网络已经可以实现具有竞争力的性能,尤其是在更大的数据集上(在3个指标上实现SOTA性能),这表明现有的SOTA方法可能无法很好地解决COD任务。
所有这些SOTA-COD方法都有一个共同的特点:它们只是通过复杂的技术来增强图像的RGB域信息。然而,根据生物学和心理学的研究,当将目标动物与其背景分离时,依赖频率的捕食者捕食利用其与特定特征相关的感知滤波器。在处理视觉场景时,动物的波段比人类多,这使得人类视觉系统(HVS)很难识别伪装的物体。
在本研究中,作者认为COD任务的目标不仅仅是在单个RGB域中模拟人类的视觉能力,而是超越人类的生物视觉。因此,为了更好地从背景中检测伪装物体,需要图像中的一些其他线索(例如,频域中的线索)。
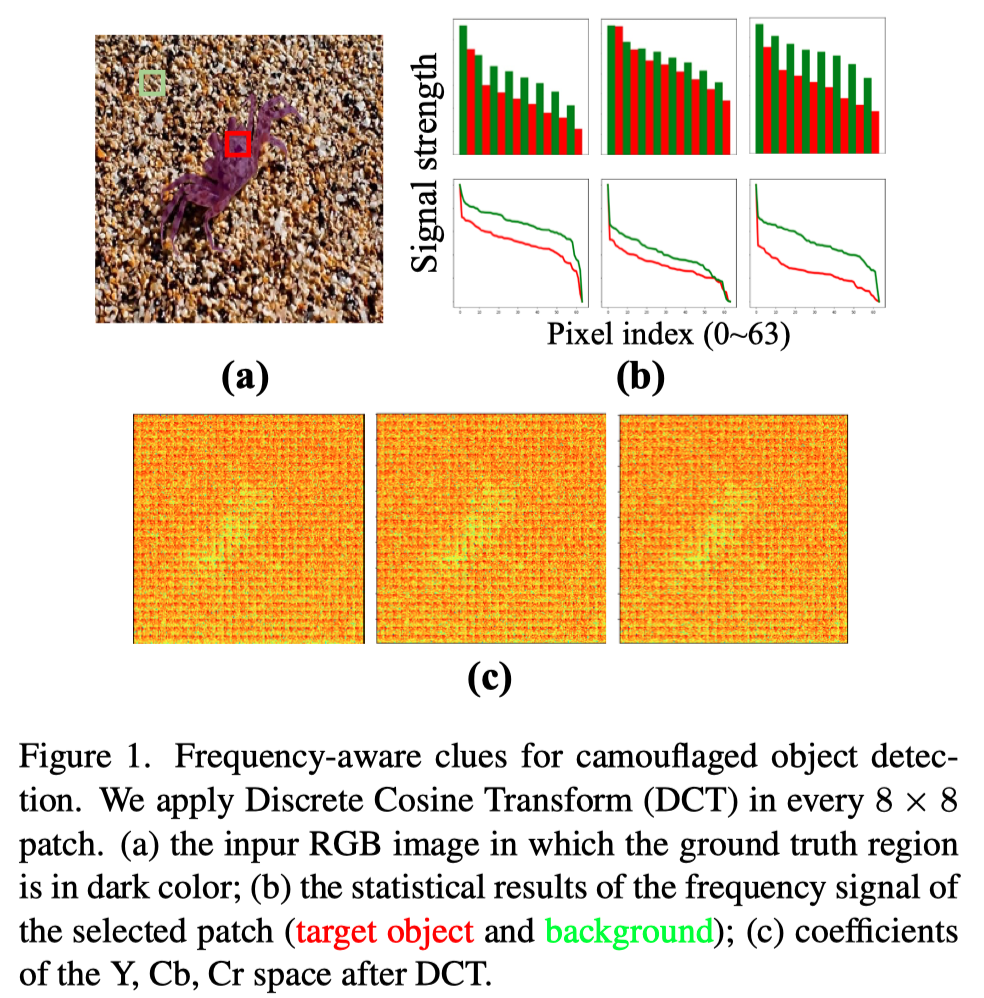
如之前的工作所述,CNN有潜力利用人类无法感知的各种频率图像成分。本文解决的第一个问题是如何将频率感知线索纳入CNN模型。为了了解更多统计信息并增强频域中伪装物体的线索,作者设计了一个频率增强模块(FEM)。它包括一个线性离散余弦变换和一个在线可学习增强,然后进行特征对齐,以融合来自两个RGB和频域的特征。
此外,作者提出了一种新的频率损失来直接约束频率,并引导网络更加关注频率信号。如上图(a)所示,“红框”表示目标物体,“绿框”表示背景。目标对象在背景中是模糊的。在RGB域中,目标对象很难看到。然而,在频域(上图(c))中,捕获了有助于区分目标物体和背景的信息。
当图像中存在噪声对象时,可以将其与伪装对象一起提取。为了区分真实的伪装对象,作者提出了高阶关系模块(HOR)。由于目标和噪声对象总是共享相似的结构信息,低阶关系不足以获得判别特征。
主要贡献总结如下:
- 本文是第一个COD任务应该超越RGB域并引入频率线索来更好地检测伪装物体的工作。
- 作者为COD任务提供了一个强大的网络,具有增强的频率线索。作者设计了具有频率感知损失的频率增强模块(FEM)和高阶关系模块(HOR),以更好地利用频域信息进行密集预测任务。
- 在三个广泛使用的COD数据集(CHAMELEON、CAMO测试和COD10测试)上的综合实验表明,该方法大大优于其他最先进的方法。
方法
1.Network overview
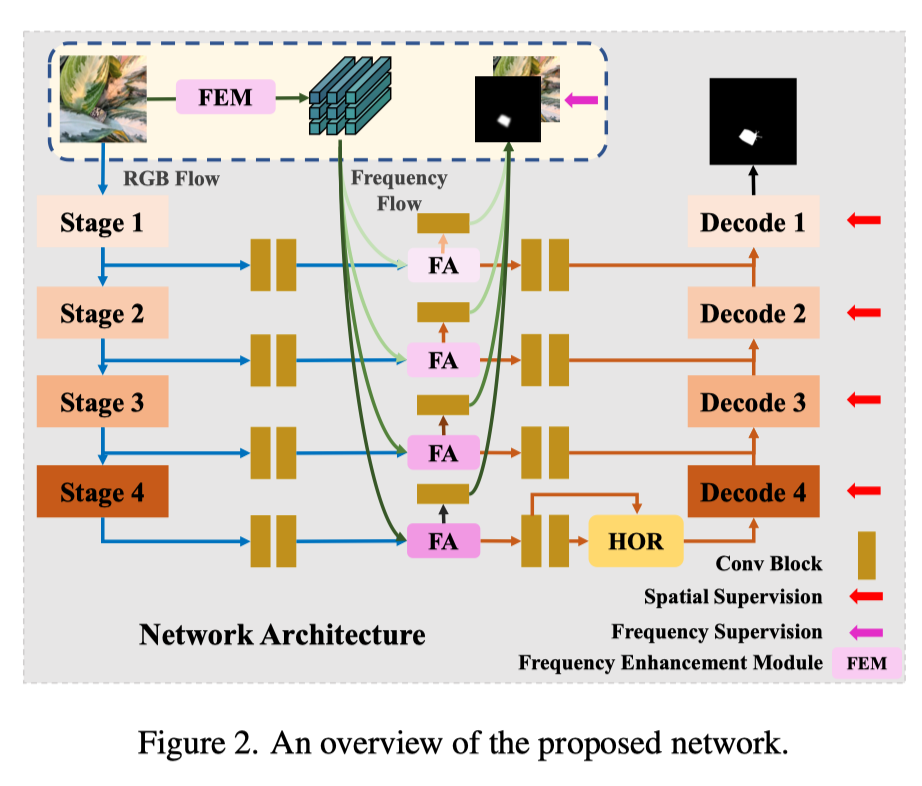
上图展示了提出的网络。RGB输入被转换到频域,并通过频率增强模块(FEM)进行增强。然后,RGB和频率输入分别以RGB流和频率流输入到网络中。特征对齐(FA)用于从RGB和频域融合这些特征。为了在特征中发现更多细微差异以区分伪装对象,在主网络中构建了高阶关系模块(HOR)。
2. Frequency enhancement module
Offline Discrete Cosine Transform
在这一部分中,输入RGB图像首先通过DCT处理以利用频率信息。xrgb转换为YCbCr空间。然后,可以得到{pi,jc|1<i,j<H/8}通过将xYCbCr划分为一组8×8的patch(在图像的滑动窗口上密集地进行DCT是频率处理(如JPEG压缩)的常见操作)。pi,jc表示某个颜色通道的patch。
每个patch通过DCT处理为频谱di,jc,其中每个值对应于特定频带的强度。为了将相同频率的所有分量组合到一个通道中,作者对频谱进行细化,并根据patch下标对其进行整形以形成新的输入:
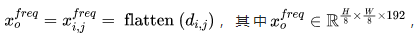
,di,j表示所有di,jc的concat结果。通过这种方式,作者将锯齿状排列的信号重新排列在一个patch中,xofreq的每个通道都属于一个频带。因此,原始颜色输入被转换到频域。
Online learnable enhancement
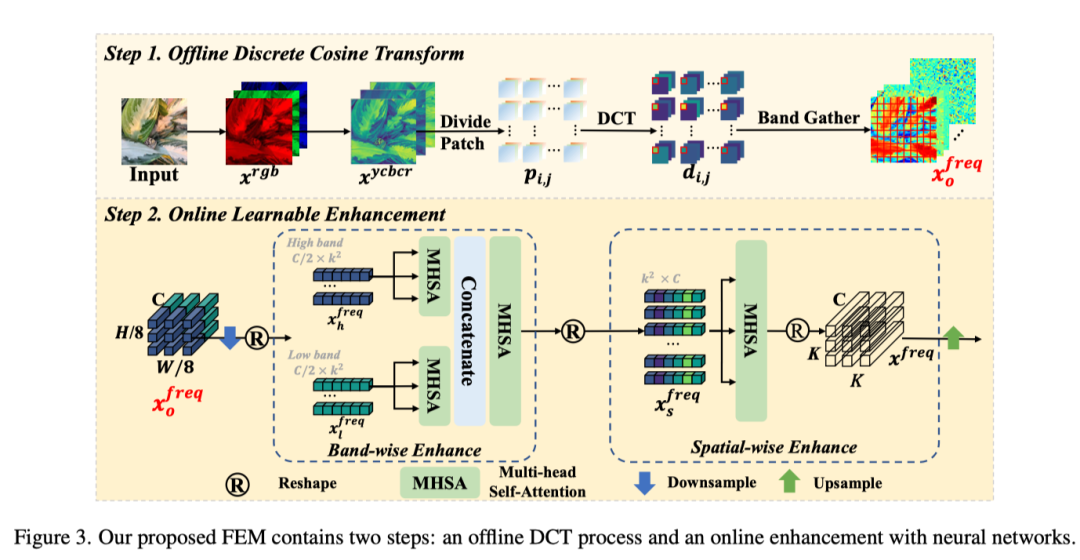
上图描述了频域转换过程,其中图像映射到频域,并通过可学习模块进行增强,以发现隐藏在频率空间中的伪装对象的线索。实际上,存在各种伪装对象和复杂背景,固定的离线 DCT可能无法很好地处理这一点。因此还需要一个自适应学习过程来适应复杂的场景。因为信息在预处理过程中会丢失,例如JPEG压缩。为了加强频域信号,作者引入了在线可学习增强来提高信号的适应性。
作者从单个patch内和patch之间构建增强模块。遵循传统方法,首先增强局部频带中的系数。对信号进行降采样并将其分为两部分,低信号和高信号,其中k表示尺寸。为了增强相应频带中的信号,作者将其分别馈入两个多头自注意力(MHSA),并连接其输出以恢复原始形状。
然后,另一个MHSA协调所有不同的频带,新形成的信号表示。MHSA能够捕捉输入特征中每个item之间的丰富相关性。此时,图像的不同频谱完全相互作用。对于离散余弦变换,patch相互独立,上述过程仅增强了单个patch。为了帮助网络识别伪装对象的位置,需要在patch之间建立concat。首先将xfreqf reshape为xfreqs。然后使用MHSA来建模所有patch之间的关系。
最后,可以上采样并得到增强的频率信号xfreq。两个xrgb和xfreq都被馈送到网络中。由于作者在每个地方应用单层MHSA,并且频率信号的大小很小,因此不会带来很高的计算成本。
Feature alignment
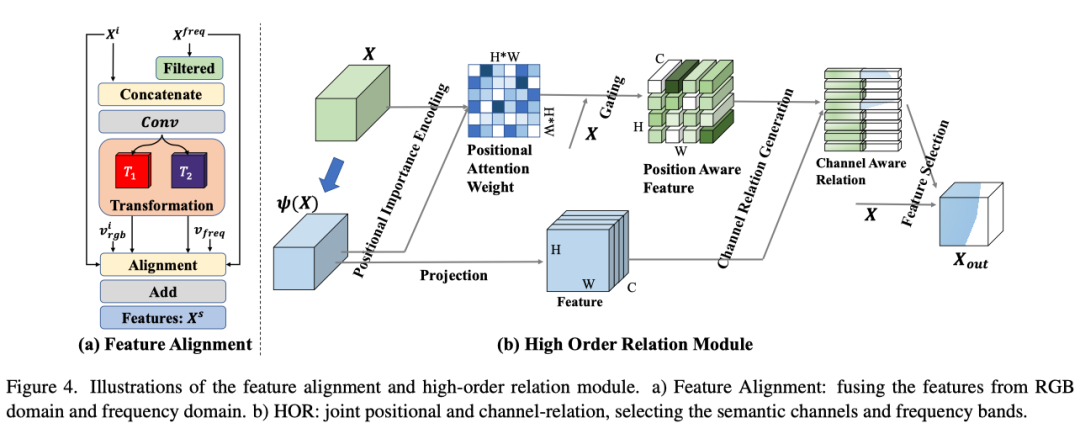
作者引入频率信息来帮助区分伪装物体与背景或干扰物体。因此应该构建另一个模块来融合RGB域和信号域的特征,因为它们没有对齐,如上图(a)所示。特征对齐是一个相辅相成的过程。伪装目标的频率特征是有区别的。RGB特征具有更大的感受域,可以补偿频率特征。由于之前的处理确保xrgb和xfreq在空间上对齐,因此在本部分中,作者仅将频域与rgb域对齐。
由于CNN模型对低频信道更敏感,作者首先应用滤波器从COD的xfreq中提取有用的部分Xfreq。根据图1中的可视化,可以看到,较高频率下的差异有助于找到伪装对象。作者设计了一个覆盖高频带的二进制base滤波器fbase,并为Y、Cb、Cr颜色空间添加了三个可学习滤波器fi。
滤波是频率响应和组合滤波器之间的点积fbase+σ(fi)。对于输入频域特征xfreq,网络可以通过以下方式自动聚焦最重要的频谱:
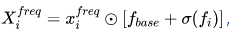
,其中⊙ 是元素乘积。最后,作者把它们放在一起:
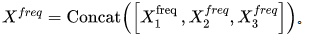 。
。
然后,作者从空间域和频域计算这两个信号的变换。由于Xi具有不同的大小,因此需要将Xfreq缩放到其相应的大小。作者concat了Xi和Xfreq,然后将其馈入具有4n个输出通道的Conv层,输出为T。
然后将第三维reshape为HW*n。因此可以获得REG域的融合矩阵,频域的融合矩阵,计算方式如下: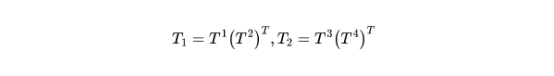
然后对齐特征图。可学习向量调整每个通道的强度。每个域的对齐特征表示如下: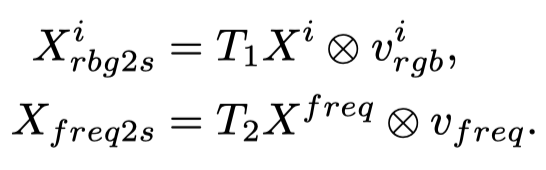
最后,作者可以通过添加两个域特征来获得融合特征:。通过这种方式,可以利用辨别频率信息来查找伪装对象,同时保持CNN线索,以确保对象的完整性和细节。
Frequency perception loss
为了进一步捕获不同于人类感知的频率,作者引入了一种新的损失来约束网络。除了直接在RGB域中计算损耗外,作者还打算在频域中对网络进行监督。一方面,常用的损失可能无法在频域对网络产生有效的引导,并可能导致关键线索的丢失。另一方面,作者认为,当预测作用于原始图像时,不仅在每个像素位置,而且在DCT后的系数中,预测都应该是正确的。
由于离散余弦变换是一种基于patch的运算,可以在这里得到粗略的预测,主要集中在伪装对象的定位上。从使用像素损失出发,作者在DCT后的频域中计算损失,并且可以引导网络在频域中挖掘更多信息。给定输入的RGB图像x、相应的ground truth掩码M和预测掩码Y,可以定义损失如下: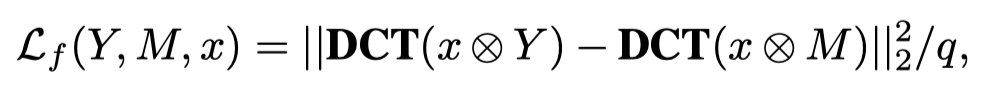
其中⊗ 指元素乘法。Y和M将首先被复制并扩展到与x相同的大小。
3. High order frequency channel selection
在频域信息的帮助下,已经可以通过不可见的线索来提高网络的性能。然而,如果想要更好地区分伪装对象与其他非伪装对象,需要深入研究中不同像素之间的关系。具体来说,借助频域信息,可以从背景中分离出真实的伪装和干扰物体。
然而,真实的伪装和干扰物体通常共享极其相似的结构信息,频域线索很难区分细微差异。一种直观的方法是引入注意力机制,以探索特征内不同像素的关系,这可能有助于区分细微差异。然而,常用的注意机制只能捕捉到低阶关系,并且不足以发现这些细微的差异。因此,作者提出了一个高阶关系模块(HOR)来解决这个问题。
因此,作者提出了高阶关系模块(HOR),以充分利用频率信号中的信息,如上图(b)所示。通过采用位置感知gating操作构建结构关系,为进一步的通道交互和判别频谱选择提供高阶空间增强。
X表示输入特征,首先将其重塑为C*HW。由于频率响应来自局部区域,因此有必要对原始特征进行位置重要性编码,以区分伪装物体与其他物体。位置注意力权重可以表示为: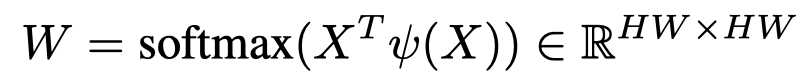
此外,不同的网络层以不同的尺度呈现潜在信息,后面的层具有更大的感受域。利用跨层语义还可以增强多尺度学习的表示。这里表示比后一些的一层。因此,作为注意力权重,用于发现不同层之间的RGB和频率响应相关性。然后,位置权重加强原始特征,并随后通过自适应gating操作,以在出现不同样本时选择最有用的特征: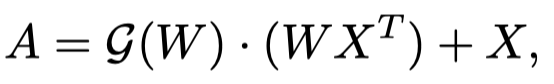
其中表示由FC层生成的gating权重,可以将其视为函数。基于空间感知生成gating操作,以形成位置感知特征。
非局部注意力与本文的模块最相关。然而,它可以使用每个通道的重新加权机制进行隐式描述。这种注意力机制可以被视为去噪或高通滤波操作。PFNet连续使用两个这样的模块用于通道和空间。
这使他们相互独立。类似地,虽然特征A保持其原始形状,但省略了跨不同语义通道和频带的关系矩阵。因此,作者提出随后生成丰富的关系感知表示。在获得位置增强特征A后,可以通过类似的操作建立通道感知关系矩阵: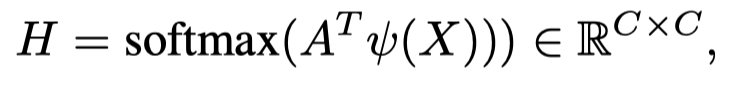
其中C表示位置感知特征的通道尺寸。通道感知关系中的每个张量对于对应于原始特征通道和频谱的语义和频率映射具有相同的C维。最后,作者将该关系矩阵应用于X,以获得有利于伪装对象的选定信息:。然后将特征送入解码过程。
4. Supervision
设D表示从解码块的每个阶段提取的特征。在本文的网络中,作者在不同分辨率下进行了四个预测P,在每个FA之后从卷积层中得到Y。每个P和Y首先重新缩放为输入图像大小。作者通过频率感知损失在频域中监督网络。
作者还在通用RGB域中提供监督,以确保细节。作者将加权BCE loss和加权IoU损失结合起来,以更加关注分散区域。损失函数定义为: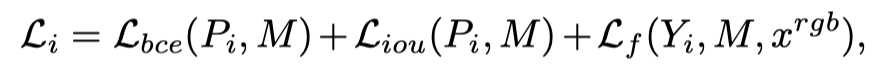
其中M表示Ground Truth标签,i表示网络的第i阶段。最后,总损失函数为:
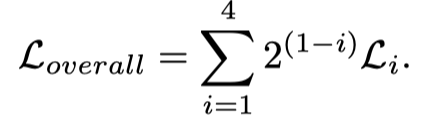
实验
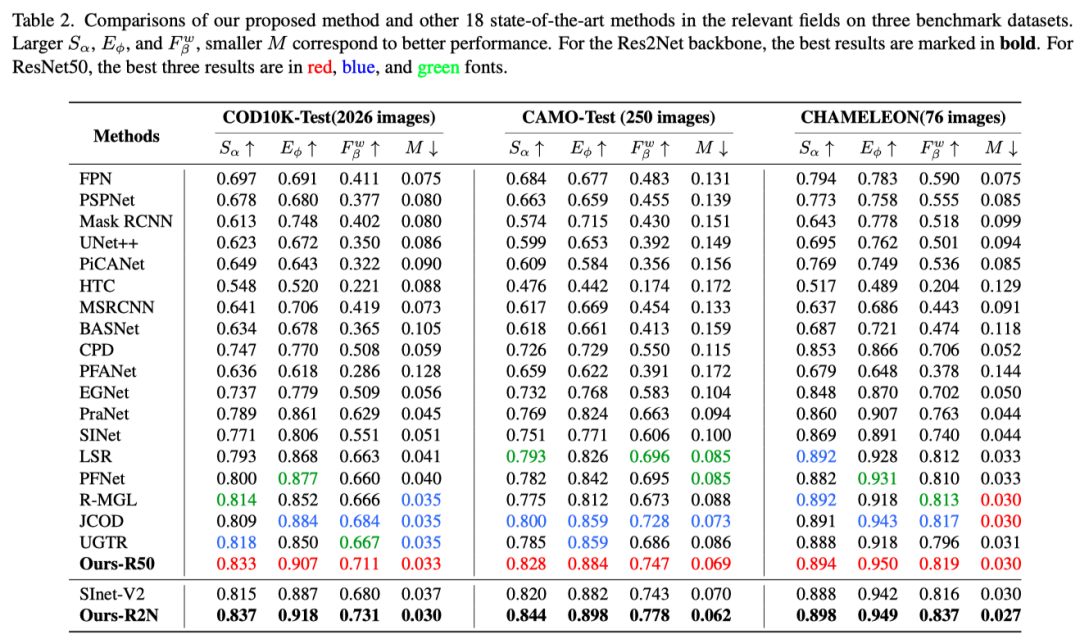
对于定量评估,作者在上表中报告了四个流行的指标。baseline是具有加权BCE损失和加权IoU损失的vanilla U-Net。请注意,无论应用哪种主干网络,本文的网络都能在这些数据集上实现具有竞争力的性能。
在上图中,作者提供了具有挑战性的示例。与其他方法相比,本文的方法获得更具竞争力的视觉表现主要体现在以下几个方面。(a) 更精确的伪装对象定位。(b) 更强的噪声对象抑制。
首先,作者探讨了哪些频段对COD更有效。在没有base滤波器的情况下训练模型。上图左侧显示了可学习滤波器选择光谱的heat-map。其次,作者使用基滤波器训练模型。通过这种方式,可以明确告诉网络关注更高频率的信息。如上图右侧所示,该网络可以进一步发现数量较少的特定、有区别的频带。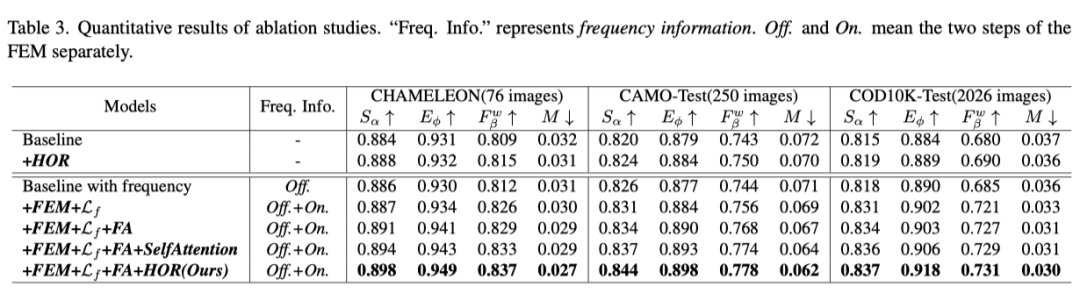
上表展示了本文方法中每个模块的消融实验结果,可以看出,本文方法中的每个模块都具有非常好的效果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢