
少样本动作识别在动作识别领域是一个大家期望达到的目标。近几年,围绕少样本动作识别这一主题出现了大量的文章。但目前的少样本动作识别工作大部分都是基于视频的,具有数据维度高,难以训练等等问题。我们组前段时间挖了个新坑,即从低维的骨骼点数据上进行动作少样本识别:“Learning Spatial-Preserved Skeleton Representations for Few-Shot Action Recognition(ECCV 2022)。

https://zhoushengisnoob.github.io/papers/DASTM.pdf
代码(已开源):
https://github.com/NingMa-AI/DASTM
该工作在较少的训练数据下取得了良好的效果。比如在NTU-RGB+D 120上我们取了100类,每个类取30个样本,组成共3000个动作的数据集,就能达到70%以上的1-shot精度。接下来将为大家简要介绍我们的主要内容,更多细节还请移步原文。
框架
我们采用原型网络(Prototypical Networks)作为基础的少样本解决方案:
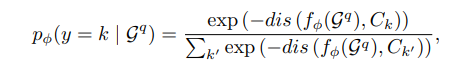
的动作的原型。熟悉少样本学习的同学都知道,一旦使用了原型网络,那么后续就需要设计合适的距离度量函数 dis() 来实现具体的匹配方法,本工作也是围绕设计度量函数来展开。在基于骨骼点的动作识别中,单个动作是由多个连续的骨架图组成,如下所示:
单个动作的表示形式
对于骨架图序列,我们采用了空间匹配和时序匹配结合的方式进行骨架序列度量,具体模型框架如下:
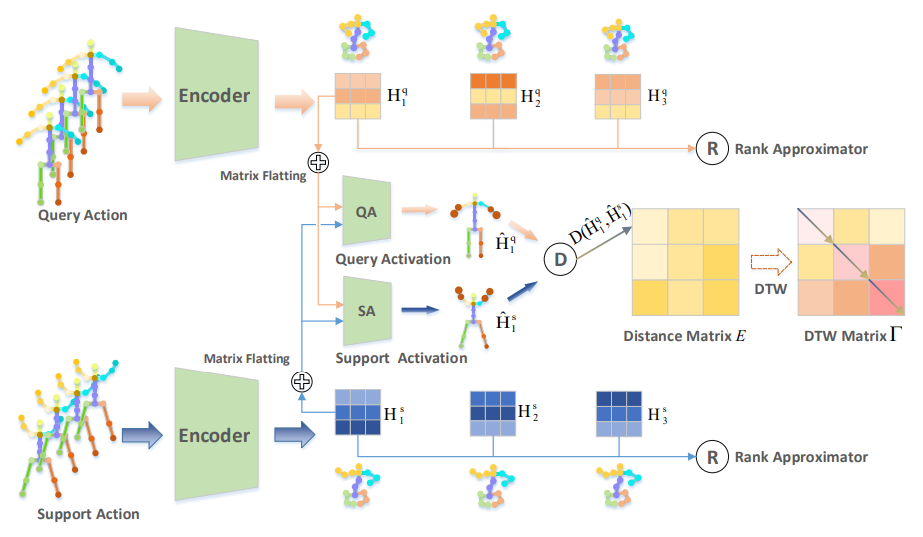
The Illustration that describes 1-shot action recognition with our framework.
该框架主要由两大部分组成:(1)空间对齐,包括基于秩最大化的解耦约束;基于注意力的空间激活模块;(2)时序对齐,直接基于DTW方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢