
多语言大模型落地的新范式自OpenAI GPT-3、盘古α等超大规模预训练语言模型问世以来,大模型的强大语言表征能力在AI领域掀起了新一轮革命。在大模型不断刷新各类AI任务纪录的同时,如何将其高效部署到实际产品中逐渐成为核心课题。特别是在算力受限的终端应用中,往往无法直接部署性能卓越的大模型。这一问题在多语言大模型上尤为突出,因为其较单语言模型(如中文)需要更大参数量,用以学习更大规模的多语言语料。
另一方面,随着中国企业国际化进程的加速,AI模型的跨语言迁移成为一个关键问题。例如,当业务部门已经在中文上构建并部署了一套基于CNN或Transformer网络的对话NLU模型后,如何能快速地、低成本地将模型迁移到如英语、日语、泰语等多个语种上,为相应语言的用户提供服务。并且,由于原模型已经完成推理优化与部署,往往希望各语种上的模型仍然保持同样的架构,以便于进行统一的部署和管理。
针对这一实际需求,华为诺亚方舟实验室提出了一种全新的多语言大模型应用范式:【FreeTransfer-X】,旨在利用多语言大模型的能力快速将已部署的NLP模型无缝迁移到其他语种,并且无需任何标注数据,从而在每个语种上至少节省上万元的标注成本。具体地,该方法借助多语言预训练模型的跨语言迁移能力和知识蒸馏技术,在目标语言上性能媲美用实际标注数据训练的模型。相关论文已发表在Findings of NAACL 2022:
https://aclanthology.org/2022.findings-naacl.16.pdf
代码开源在:
https://github.com/huawei-noah/noah-research/tree/master/NLP/FreeTransfer-X2
研究背景及任务设定
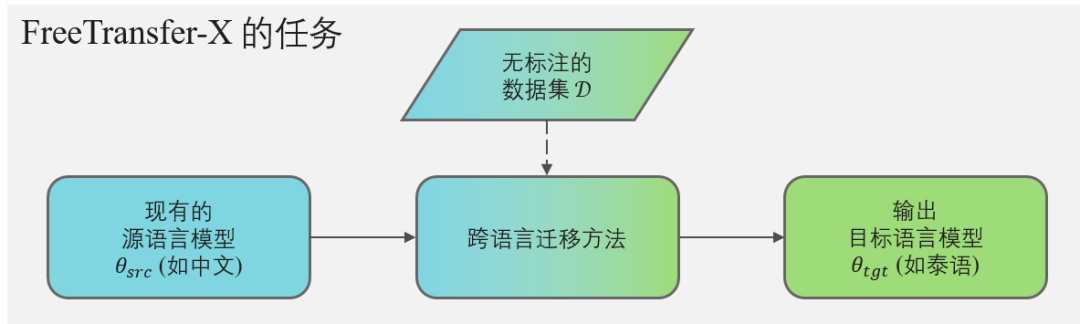
图1.FreeTransfer-X无需标注数据
传统的多语言大模型落地基于“精调+模型压缩”,它通常依赖昂贵的标注数据。而【FreeTransfer-X】如图1所示,仅基于【现有的源语言模型】及【无标注数据】,输出【目标语言的模型】。同时我们为了快速适配源语言已有部署环境,要求目标语言模型与源语言模型架构保持完全一致。【FreeTransfer-X】能安全、高效地利用已有的NLP模型及无标注数据。
【FreeTransfer-X】的解决方案
作为【FreeTransfer-X】的实现,本文提出了以【多语言预训练模型】(multilingual Pre-trained Language Model,mPLM)为“桥梁”的跨语言迁移框架,并通过知识蒸馏(Knowledge Distillation, KD [1])技术进行能力的迁移。此外,我们还引入了两种数据增强方法提升迁移性能。
- 基于mPLM的跨语言知识蒸馏
如图2所示,【FreeTransfer-X】包含两步蒸馏:
蒸馏①:源语言模型向mPLM蒸馏,同时借助mPLM的跨语言表示能力,得到具备目标语言NLP知识的;
蒸馏②:上述mPLM继续向目标语言模型蒸馏,使其具备目标语言NLP知识。
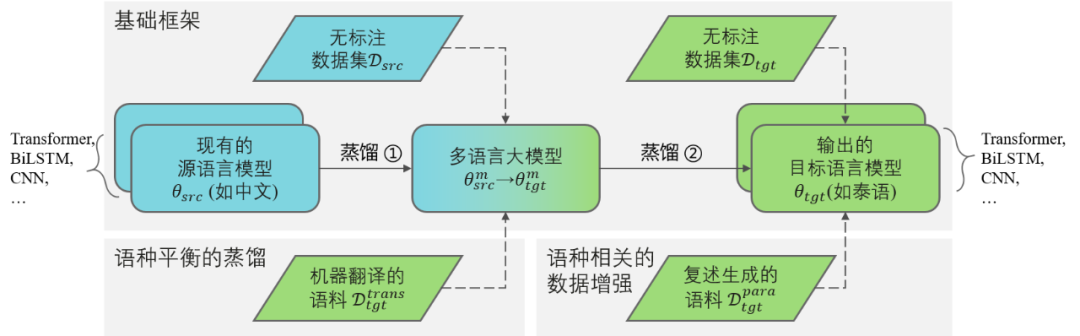
图2. 总体框架:基于多语言预训练模型、知识蒸馏和数据增强的【FreeTransfer-X】
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢