
机器学习中最重要的方面之一是超参数优化,因为为机器学习任务找到正确的超参数可以决定或破坏模型的性能。在内部,我们经常使用 Google Vizier 作为超参数优化的默认平台。在过去 5 年的部署过程中,Google Vizier 的使用次数已超过 1000 万次,用于各种应用程序,包括来自视觉、强化学习和语言的机器学习应用程序,以及蛋白质发现和硬件加速等科学应用程序.由于 Google Vizier 能够跟踪其数据库中的使用模式,因此这些数据通常由称为研究的优化轨迹组成,包含有关实际超参数调整目标的非常有价值的先验信息,因此对于开发更好的算法非常有吸引力。
虽然以前有许多对此类数据进行元学习的方法,但这些方法有一个主要的共同缺点:它们的元学习过程严重依赖于数值约束,例如超参数的数量及其值范围,因此要求所有任务都使用完全相同的总超参数搜索空间(即调整规范)。研究中的其他文本信息,例如其描述和参数名称,也很少使用,但可以包含有关正在优化的任务类型的有意义的信息。对于通常包含大量此类有意义信息的较大数据集,这种缺点变得更加严重。

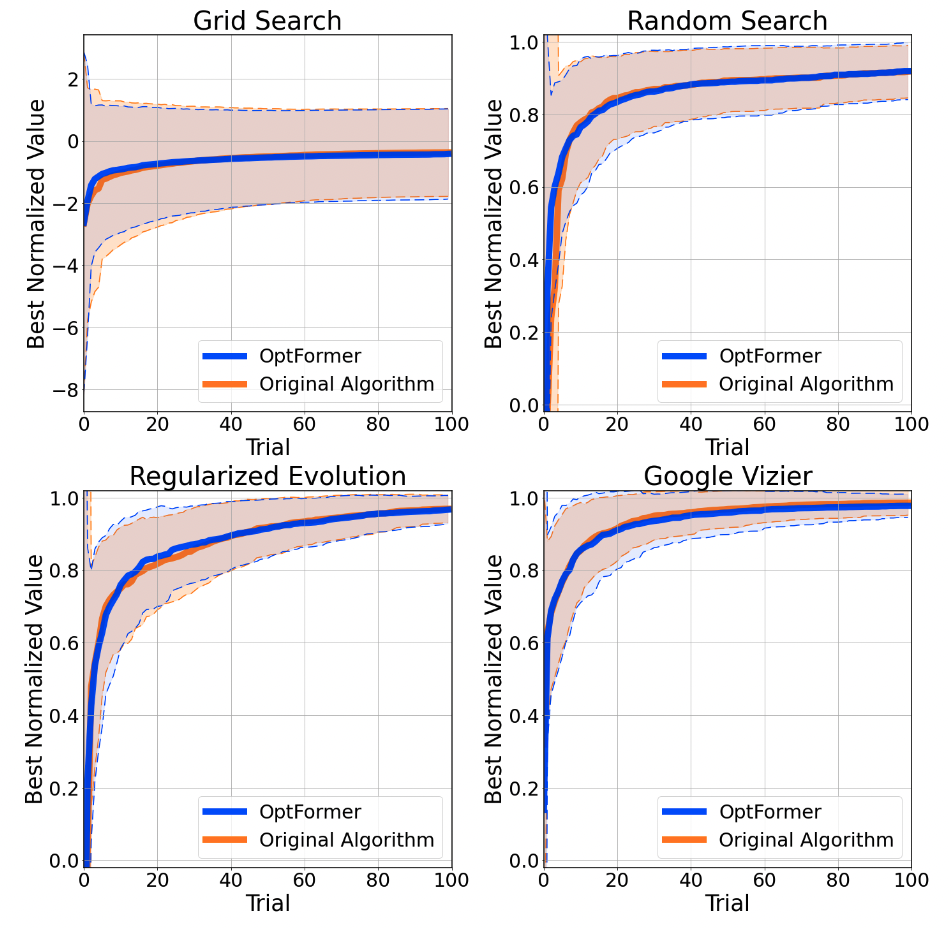
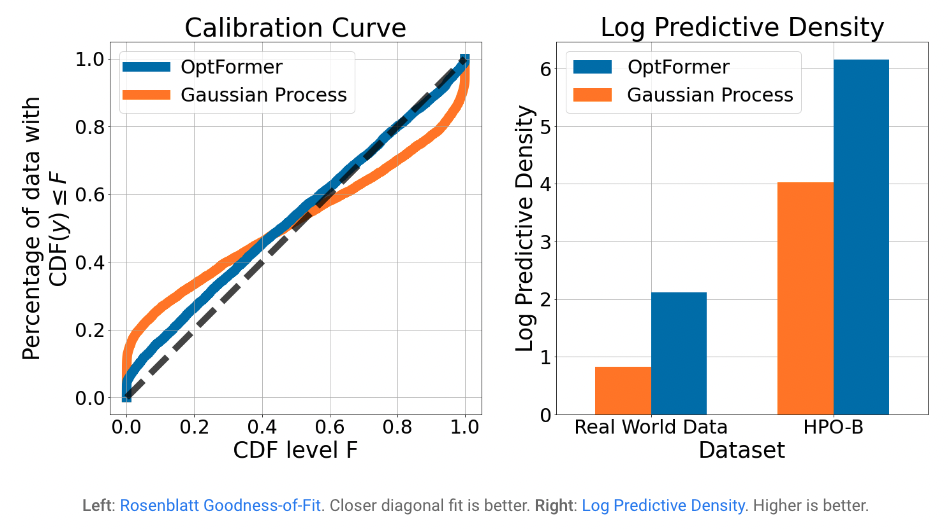
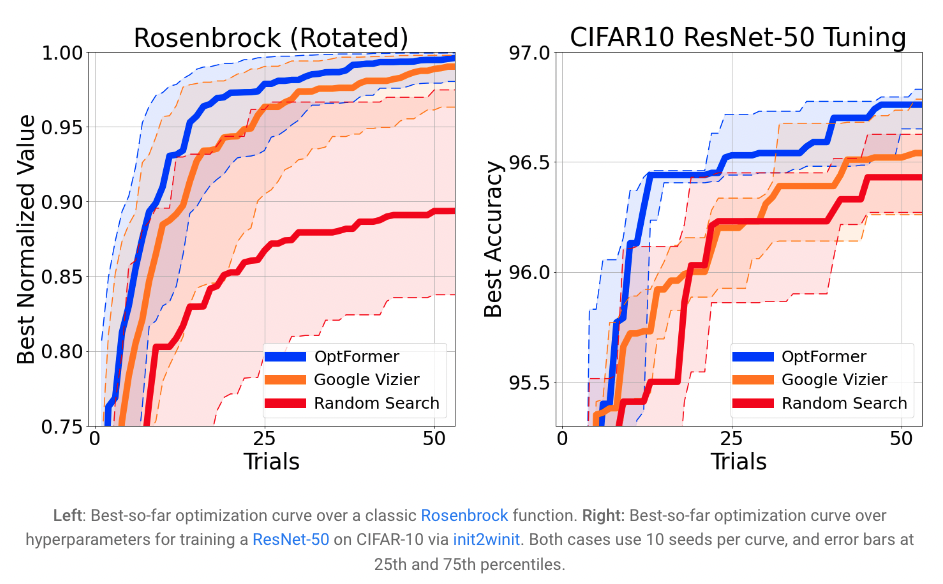
今天在“使用 Transformer 学习通用超参数优化器”中,我们很高兴介绍 OptFormer,它是第一个基于 Transformer 的超参数调整框架之一,它使用灵活的基于文本的表示从大规模优化数据中学习。虽然之前有许多作品展示了 Transformer 在各个领域的强大能力,但很少有人提到它基于优化的能力,尤其是在文本空间方面。我们的核心发现首次证明了 Transformer 的一些有趣的算法能力:1)单个 Transformer 网络能够在很长的范围内模仿多种算法的高度复杂的行为; 2)网络进一步能够非常准确地预测目标值,在许多情况下超过了贝叶斯优化等算法中常用的高斯过程。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢